本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 SageMaker AI Deepar 预测算法
Amazon SageMaker AI Deepar 预测算法是一种监督学习算法,用于使用循环神经网络 (RNN) 预测标量(一维)时间序列。经典预测方法,如自回归积分滑动平均模型 (ARIMA) 或指数平滑法 (ETS),会将一个模型拟合到各个单独的时间序列。然后使用该模型,将时间序列外推到未来。
但是,在很多应用中,您有跨一组具有代表性单元的多个相似时间序列。例如,您可以根据对不同产品、服务负载和网页请求的需求,将时间序列分组。对于这种类型的应用程序,您可以通过对所有时间序列共同训练单个模型中来受益。DeepAR 采用此方法。当您的数据集包含数百个相关的时间序列时,DeepAR 要优于标准 ARIMA 和 ETS 方法。您还可以使用训练过的模型来生成与已训练过的时间序列相似的新时间序列的预测。
DeepAR 算法的训练输入是一个或者(最好是)多个 target 时间序列,由同一进程或类似进程生成。基于此输入数据集,该算法训练一个模型,该模型学习其近似值, process/processes 并使用它来预测目标时间序列的演变方式。每个目标时间序列都可以选择关联一个由 cat 字段提供静态(与时间无关)分类特征向量,以及一个由 dynamic_feat 字段提供的动态(与时间相关)时间序列向量。 SageMaker AI 通过对训练数据集中每个目标时间序列的训练示例进行随机采样来训练 Deepar 模型。每个训练示例包括一对具有固定的预定义长度的相邻上下文和预测窗口。要控制网络可以向过去追溯的时间长度,请使用 context_length 超参数。要控制可以对未来进行预测的时间长度,请使用 prediction_length 超参数。有关更多信息,请参阅 DeepAR 算法的工作方式。
主题
Input/Output 深度增强现实算法接口
DeepAR 支持两种数据通道。必需的 train 通道描述训练数据集。可选的 test 通道描述在训练后,算法在评估模型准确性时使用的数据集。您可以通过 JSON 行
指定训练和测试数据的路径时,您可以指定一个文件,也可以指定包含多个文件的目录,这些文件可以存储在子目录中。如果指定目录,DeepAR 将使用目录中的所有文件作为对应通道的输入,但以句点 (.) 开头的文件和名为 _SUCCESS 的文件除外。这确保您可以直接将 Spark 作业生成的输出文件夹,用作 DeepAR 训练作业的输入通道。
默认情况下,DeepAR 模型通过指定输入路径中的文件扩展名(.json、.json.gz 或 .parquet)确定输入格式。如果路径未以其中一个扩展名结束,则必须在 SDK for Python 中明确指定格式。使用 s3_inputcontent_type 参数。
输入文件中的记录中应包含以下字段:
-
start– 格式为YYYY-MM-DD HH:MM:SS的字符串。开始时间戳不能包含时区信息。 -
target– 表示时间序列的浮点值或整数的数组。您可以将缺失的值编码为null文字,在 JSON 中作为"NaN"字符串,或者在 Parquet 中作为nan浮点值。 -
dynamic_feat(可选)– 表示自定义特征时间序列(动态特征)向量的浮点值或整数的一个或多个数组。如果设置此字段,则所有记录必须具有相同数量的内部数组(与特征时间序列数量相同)。此外,每个内部数组的长度必须与关联的target值加上prediction_length的长度相同。特征中不支持缺少的值。例如,如果目标时间序列代表对不同产品的需求,那么关联的dynamic_feat可能是布尔值时间序列,表示对特定产品应用了 (1) 还是没有应用 (0) 促销:{"start": ..., "target": [1, 5, 10, 2], "dynamic_feat": [[0, 1, 1, 0]]} -
cat(可选)– 可用于对记录所属的组进行编码的分类特征的数组。分类特征必须编码为从 0 开始的正整数序列。例如,分类域 {R, G, B} 可以编码为 {0, 1, 2}。每个分类域的所有值必须均存在于训练数据集中。这是因为 DeepAR 算法只能对训练期间观察到的类别进行预测。而且,每个分类特征都嵌入在低维度空间中,其维度由embedding_dimension超参数控制。有关更多信息,请参阅 DeepAR 超参数。
如果您使用 JSON 文件,它必须采用 JSON 行
{"start": "2009-11-01 00:00:00", "target": [4.3, "NaN", 5.1, ...], "cat": [0, 1], "dynamic_feat": [[1.1, 1.2, 0.5, ...]]} {"start": "2012-01-30 00:00:00", "target": [1.0, -5.0, ...], "cat": [2, 3], "dynamic_feat": [[1.1, 2.05, ...]]} {"start": "1999-01-30 00:00:00", "target": [2.0, 1.0], "cat": [1, 4], "dynamic_feat": [[1.3, 0.4]]}
在此示例中,每个时间序列都有两个关联的分类特征和一个时间序列特征。
对于 Parquet,您使用相同的三个字段作为列。此外,"start" 可以是 datetime 类型。您可以使用 gzip (gzip) 或 Snappy 压缩库 (snappy) 来压缩 Parquet 文件。
如果在无 cat 和 dynamic_feat 字段情况下训练该算法,则它学习一个“全局”模型,即跟推理时的目标时间序列的具体身份无关而仅以其形状为条件的模型。
如果模型的条件基于为每个时间序列提供的 cat 和 dynamic_feat 特征数据,则预测可能会受到具有对应 cat 特征的时间序列特性的影响。例如,如果 target 时间序列标识对服装商品的需求,您可以关联一个二维 cat 向量,在第一个组件中对商品类型进行编码(例如 0 = 鞋子,1 = 服装),在第二个组件中对商品的颜色进行编码(例如 0 = 红色,1 = 蓝色)。示例输入如下所示:
{ "start": ..., "target": ..., "cat": [0, 0], ... } # red shoes { "start": ..., "target": ..., "cat": [1, 1], ... } # blue dress
在推理时,您可以请求对具有 cat 值的目标进行预测,该值是在训练数据中观察到的 cat 值的组合,例如:
{ "start": ..., "target": ..., "cat": [0, 1], ... } # blue shoes { "start": ..., "target": ..., "cat": [1, 0], ... } # red dress
以下准则适用于训练数据:
-
时间序列的开始时间和长度可以不同。例如,在营销中,产品通常会在不同的日期输入零售目录中,因此它们的开始日期自然就不同。但所有序列都必须具有相同的频率、分类特征数和动态特征数。
-
根据文件中时间序列的位置将训练文件随机排序。换而言之,时间序列在文件中应以随机顺序出现。
-
请确保正确设置了
start字段。该算法使用start时间戳来推理内部特征。 -
如果您使用分类特征 (
cat),则所有时间序列必须具有相同的分类特征数。如果数据集包含cat字段,则算法使用它并从数据集中提取组的基数。默认情况下,cardinality为"auto"。如果数据集包含cat字段,但您并不想使用它,则可以通过将cardinality设置为""来禁用它。如果模型使用cat特征进行了训练,则您必须包括它以进行推理。 -
如果您的数据集包含
dynamic_feat字段,则算法会自动使用它。所有时间序列必须具有相同数量的特征时间序列。每个特征时间序列中的时间点与目标中的时间点一一对应。此外,dynamic_feat字段中条目的长度应与target相同。如果数据集包含dynamic_feat字段,但您不想使用它,请将num_dynamic_feat设置为""来禁用该字段。如果模型使用dynamic_feat字段进行训练,则您必须提供此字段用于推理。此外,每个特征的长度都必须是提供的目标加上prediction_length。换句话说,您必须在将来提供特征值。
如果您指定可选的测试通道数据,DeepAR 算法使用不同的准确性指标评估训练后的模型。该算法通过以下方式计算测试数据上的均方根误差 (RMSE):
![RMSE 公式:Sqrt 1/nT ((Sum [i, t] (y-hat (i, t)-y (i, t)) ^2))](images/deepar-1.png)
yi,t 是时间序列 i 在时间 t 的真实值。ŷi,t 是均值预测。总和基于测试集中的全部 n 个时间序列,并基于每个时间序列的最后 T 个时间点,其中 Τ 对应于预测期。您可以通过设置 prediction_length 超参数来指定预测期的长度。有关更多信息,请参阅 DeepAR 超参数。
此外,该算法使用加权分位数损失评估预测分布的准确性。对于范围为 [0, 1] 的分位数,加权分位数损失定义如下:
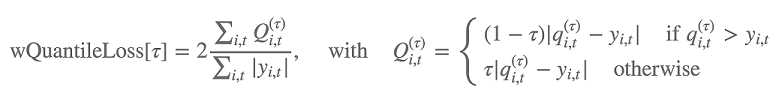
qi,t(τ) 是模型预测的分布的 τ 分位数。如需指定要计算损失的分位数,请设置 test_quantiles 超参数。除此之外,在训练日志中,还报告了规定的分位数损失的平均值。有关信息,请参阅DeepAR 超参数。
对于推理,DeepAR 接受 JSON 格式和以下字段:
-
"instances",其中包括 JSON 行格式的一个或多个时间序列 -
"configuration"的名称,其中包括用于生成预测的参数
有关更多信息,请参阅 DeepAR 推理格式。
使用 DeepAR 算法的最佳实践
准备时间序列数据时,请遵循以下最佳实践以获得最佳结果:
-
除了为训练和测试而拆分数据集之外,在训练、测试以及在调用模型进行推理时,请始终提供整个时间序列。无论您如何设置
context_length,都不要拆分时间序列或仅提供时间序列的一部分。对于滞后值特征,模型将使用比context_length中设置的值更早的数据点。 -
对于 DeepAR 模型调整,您可以拆分数据集以创建训练数据集和测试数据集。在典型的评估中,您应该在训练所用的相同时间序列上,但在未来的
prediction_length个时间点(紧跟训练期间可见的最后一个时间点)上测试模型。在训练期间,要创建满足此标准的训练和测试数据集,您可以使用整个数据集(所有可用时间序列的完整长度)作为测试集,并从每个时间序列中删除最后prediction_length个点来进行训练。在训练期间,模型将看不到所要评估的时间点的目标值。在测试期间,算法会保留测试数据集中每个时间序列的最后prediction_length个点并生成预测。然后将预测值与保留值进行比较。您可以在测试数据集中多次重复时间序列,但在不同的端点处切割它们,从而创建更复杂的评估。通过这种方法,将对不同时间点的多个预测取平均值来生成准确性指标。有关更多信息,请参阅 调整 DeepAR 模型。 -
避免对
prediction_length使用非常大的值(大于 400),因为这会降低模型的速度和准确性。如果您想进一步预测将来的情况,请考虑以较低的频率聚合数据。例如,使用5min而不是1min。 -
由于使了用滞后,模型可以向后追溯到比为
context_length指定的值更早的时间序列。因此,您不必将此参数设置为较大的值。我们建议您从用于prediction_length的值开始。 -
我们建议在尽可能多的时间序列上训练 DeepAR 模型。尽管在单个时间序列上训练的 DeepAR 模型可能正常工作,但标准预测方法(如 ARIMA 或 ETS)可能会提供更准确的结果。当数据集包含数百个相关时间序列时,DeepAR 算法便开始优于标准方法。目前,DeepAR 要求所有训练时间序列中可用的观察数据总数至少为 300。
DeepAR 算法的 EC2 实例建议
您可以在 GPU 和 CPU 实例上,在单机器和多机器设置中训练 DeepAR。我们建议您从单 CPU 实例开始(例如,ml.c4.2xlarge 或 ml.c4.4xlarge),并仅在必要时切换到 GPU 实例和多机器。使用 GPU 和多台机器只能提高大型模型(每层有多个单元和具有多个层)以及大量小批量大小(例如,大于 512)的吞吐量。
对于推理,DeepAR 仅支持 CPU 实例。
为 context_length、prediction_length、num_cells、num_layers 或者 mini_batch_size 指定较大的值,可能会创建对于小型实例来说太大的模型。在这种情况下,请使用较大的实例类型或减少这些参数的值。此问题在运行超参数调整作业时也会经常出现。在这种情况下,请为模型调整作业使用足够大的实例类型,并考虑限制关键参数的上限值以避免作业失败。
DeepAR 示例笔记本
有关演示如何准备用于训练 SageMaker AI DeepAR 算法的时间序列数据集以及如何部署经过训练的模型进行推断的示例笔记本,请参阅电力数据集的 DeepAR 演示,其中说明了现实世界数据集上
有关 Amazon A SageMaker I Deepar 算法的更多信息,请参阅以下博客文章: