本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
DeepAR 算法的工作方式
在训练过程中,DeepAR 接受训练数据集和可选的测试数据集。它将使用测试数据集评估训练后的模型。通常,数据集不必包含相同的时间序列集。您可以使用在给定训练集上训练的模型来生成训练集中时间序列的未来以及其他时间序列的预测。训练数据集和测试数据集都由一个或(最好是)多个目标时间序列组成。每个目标时间序列可以选择关联到一个特征时间序列向量和一个分类特征向量。有关更多信息,请参阅 Input/Output 深度增强现实算法接口。
例如,以下是用 i 编制索引的训练数据集元素,其中包含一个目标时间序列 Zi,t,以及两个关联的特征时间序列 Xi,1,t 和 Xi,2,t:
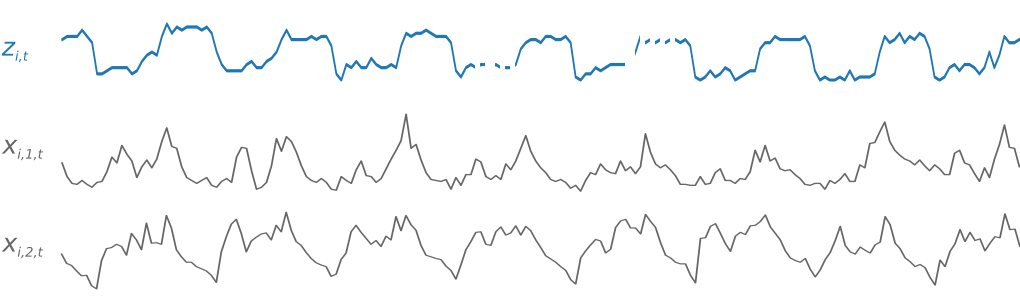
目标时间序列可能包含缺失值,这些值由时间系列中的换行符表示。DeepAR 仅支持将来已知的特征时间序列。这让您可以运行“假设” 场景。例如,如果我以某种方式改变产品价格,会发生什么?
每个目标时间序列也可以与大量分类特征关联。您可以使用这些特征对时间序列所属的特定分组进行编码。通过分类特征,模型可以学习这些分组的典型行为,这可以提高准确性。为了实施此功能,DeepAR 对各个组的嵌入向量进行学习,这些向量收集了组中所有时间序列的通用属性。
DeepAR 算法中特征时间序列的工作方式
为了推动学习与时间相关的模式(如周末的峰值),DeepAR 根据目标时间序列的频率,自动创建特征时间序列。它将这些派生的特征时间序列,与您在训练和推理期间提供的自定义特征时间序列结合使用。下图显示了这样两个派生的时间序列特征:ui,1,t 表示一天中的几点,ui,2,t 表示一周中的某天。
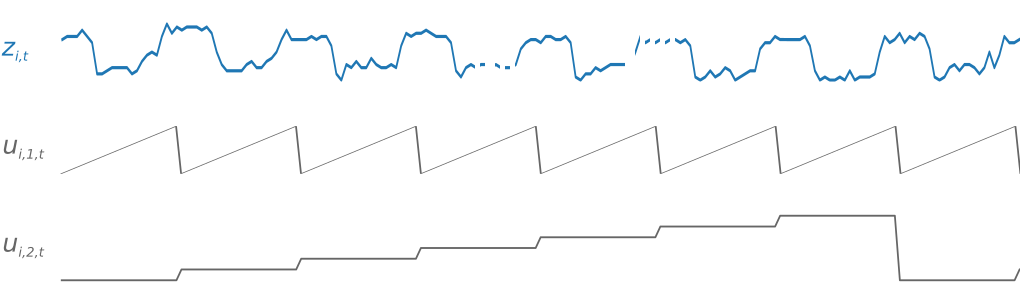
DeepAR 算法会自动生成这些特征时间序列。下表列出了可为支持的基本时间频率派生的特征。
| 时间序列的频率 | 派生的特征 |
|---|---|
Minute |
|
Hour |
|
Day |
|
Week |
|
Month |
一年中的某天 |
DeepAR 从训练数据集中的每个时间序列中随机抽取多个训练示例来训练模型。每个训练示例包括一对具有固定的预定义长度的相邻上下文和预测窗口。context_length 超参数控制网络可以向过去追溯的时间长度,prediction_length 参数控制可以对未来进行预测的时间长度。在训练过程中,如果训练集元素包含的时间序列要短于指定的预测时间长度,则忽略该元素。下图显示了从元素 i 中提取的 5 个示例,其中上下文长度为 12 个小时,预测长度为 6 个小时。为简单起见,我们省略了特征时间序列 xi,1,t 和 ui,2,t。
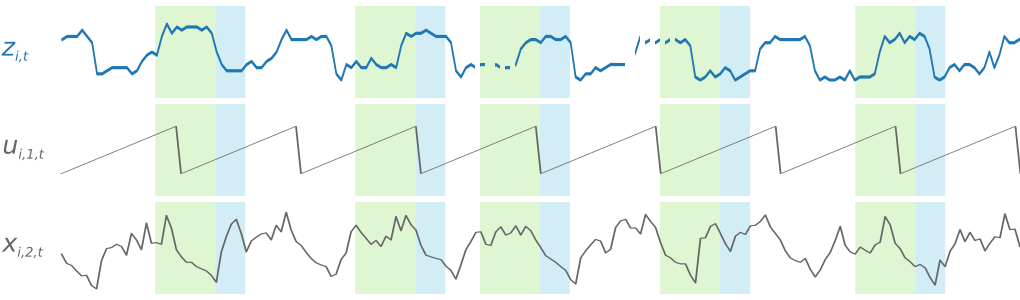
为了捕获季节性模式,DeepAR 还自动提供目标时间序列中的滞后值。在我们的以小时频率采样的示例中,对于每个时间索引 t = T,模型会公开 zi,t 值,过去大约 1 天、2 天和 3 天执行此操作一次。

对于推理,训练后的模型获取输入目标时间序列(这些时间序列在训练期间可能已使用,也可能未使用),并预测后续的 prediction_length 值的概率分布。由于 DeepAR 是在整个数据集上进行训练的,因此,预测会考虑从类似时间序列中学习的模式。
有关 DeepAR 数学运算背景的更多信息,请参阅 DeepAR:概率性预测与自回归递归网络