本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
定义管道
要使用 Amazon Pipelines 编排工作流程,您必须以 JSON SageMaker 管道定义的形式生成有向无环图 (DAG)。DAG 规定了 ML 流程中涉及的不同步骤,如数据预处理、模型训练、模型评测和模型部署,以及这些步骤之间的依赖关系和数据流。下面的主题将向您展示如何生成管道定义。
您可以使用 Python SDK 或 Amaz SageMaker on Studio 中的可视化拖放管道设计器功能生成 JSON 管道定义。 SageMaker 下图是您在本教程中创建的管道 DAG 的示意图:
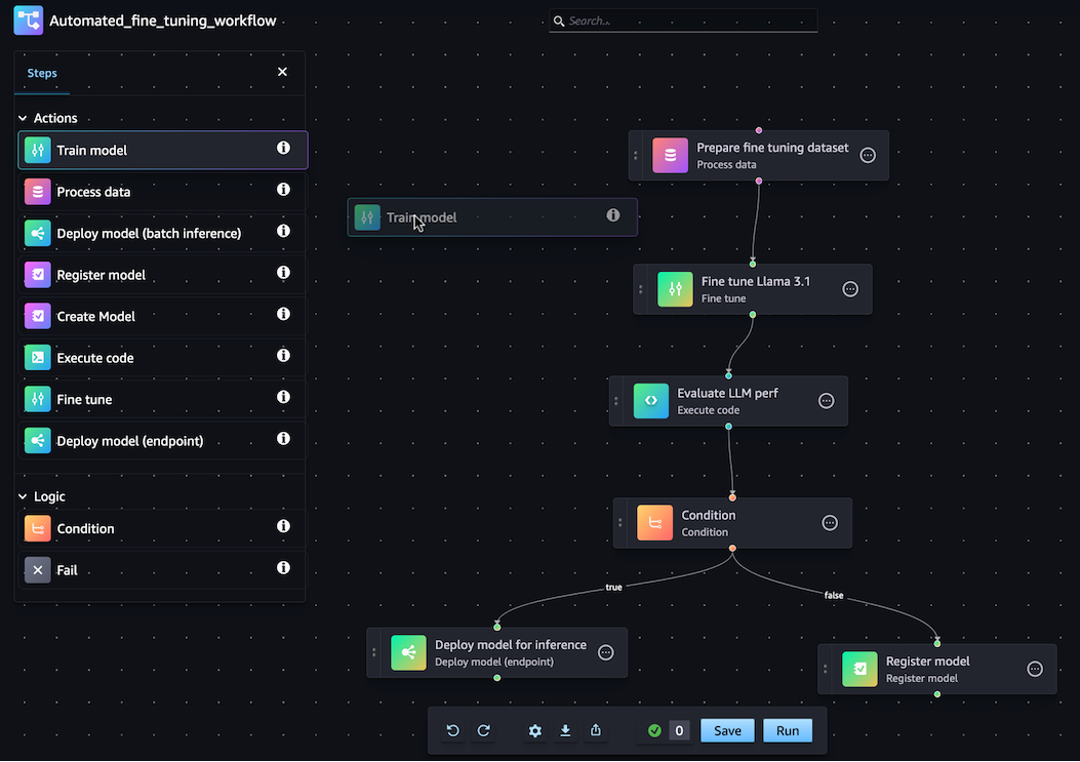
您在以下章节中定义的管道解决了一个回归问题,即根据鲍鱼的物理测量值确定其年龄。有关包含本教程内容的可运行 Jupyter 笔记本,请参阅使用 Amazon 模型构建管道编排作业
注意
您可以将模型位置作为训练步骤的属性进行引用,如 Github 中的端到端示例CustomerChurn 管道
主题
下面的演示将指导您使用拖放 Pipeline Designer 创建一个基本管道。如果您需要随时暂停或结束可视化设计器中的 Pipeline 编辑会话,请单击导出选项。这样就可以将管道的当前定义下载到本地环境中。之后,当您想恢复 Pipeline 编辑流程时,可以将相同的 JSON 定义文件导入可视化设计器。
创建 Processing 步骤
要创建数据处理作业步骤,请执行以下操作:
-
按照 启动亚马逊 SageMaker Studio 中的说明打开 Studio 管理控制台。
-
在左侧导航窗格中,选择 Pipelines。
-
选择创建。
-
选择空白。
-
在左侧边栏中选择处理数据,然后将其拖到画布上。
-
在画布中,选择添加的处理数据步骤。
-
要添加输入数据集,请在右侧边栏的数据(输入)下选择添加,然后选择一个数据集。
-
要添加保存输出数据集的位置,请在右侧边栏的数据(输出)下选择添加,然后导航至目的地。
-
填写右侧边栏中的其余字段。有关这些选项卡中字段的信息,请参阅 sagemaker.workflow.steps。 ProcessingStep
。
创建 Training 步骤
要设置模型训练步骤,请执行以下操作:
-
在左侧边栏中选择训练模型,然后将其拖到画布上。
-
在画布中选择添加的训练模型步骤。
-
要添加输入数据集,请在右侧边栏的数据(输入)下选择添加,然后选择一个数据集。
-
要选择保存模型构件的位置,请在位置 (S3 URI) 字段中输入 Amazon S3 URI,或选择 Browse S3 导航到目标位置。
-
填写右侧边栏中的其余字段。有关这些选项卡中字段的信息,请参阅 sagemaker.workflow.steps。 TrainingStep
。 -
单击并拖动光标,从上一节添加的处理数据步骤到训练模型步骤,创建连接两个步骤的边缘。
创建带有注册模型步骤的模型软件包
要创建带有模型注册步骤的模型软件包,请执行以下操作:
-
在左侧边栏中选择注册模型,然后将其拖到画布上。
-
在画布中,选择添加的注册模型步骤。
-
要选择要注册的模型,请在模型(输入)下选择添加。
-
选择创建模型组,将模型添加到新的模型组中。
-
填写右侧边栏中的其余字段。有关这些选项卡中字段的信息,请参阅 sagemaker.workflow.step_collections。 RegisterModel
。 -
单击并拖动光标,从上一节添加的训练模型步骤到注册模型步骤,创建连接两个步骤的边缘。
通过 Deploy 模型(端点)步骤将模型部署到端点
要使用模型部署步骤部署模型,请执行以下操作:
-
在左侧边栏中选择部署模型(端点),然后将其拖到画布上。
-
在画布中,选择添加的部署模型(端点)步骤。
-
要选择要部署的模型,请在模型(输入)下选择添加。
-
选择创建端点单选按钮创建新端点。
-
为端点输入姓名和描述。
-
单击并拖动光标,从上一节添加的注册模型步骤到部署模型(端点)步骤,创建连接两个步骤的边缘。
-
填写右侧边栏中的其余字段。
定义 Pipeline 参数
您可以配置一组 Pipeline 参数,其值可在每次执行时更新。要定义管道参数并设置默认值,请单击可视化设计器底部的齿轮图标。
保存 Pipeline
输入创建管道所需的全部信息后,点击可视化设计器底部的保存。这将在运行时验证管道是否存在任何潜在错误,并通知您。在处理自动验证检查标记的所有错误之前,保存操作不会成功。如果您想在以后继续编辑,可以在本地环境中将正在进行的管道保存为 JSON 定义。您可以点击可视化设计器底部的导出按钮,将管道导出为 JSON 定义文件。之后,要继续更新管道,请点击导入按钮上传 JSON 定义文件。
先决条件
要运行以下教程,请完成以下步骤:
-
按照创建笔记本实例中所述的步骤设置笔记本实例。这使您的角色有权读取和写入 Amazon S3,以及在 A SageMaker I 中创建训练、批量转换和处理任务。
-
授予笔记本获取和传递自身角色的权限,如修改角色权限策略中所示。添加以下 JSON 代码片段以将此策略附加到您的角色。将
<your-role-arn>替换为用于创建笔记本实例的 ARN。 -
按照修改角色信任策略中的步骤信任 SageMaker AI 服务主体。将以下语句片段添加到角色的信任关系中:
{ "Sid": "", "Effect": "Allow", "Principal": { "Service": "sagemaker.amazonaws.com" }, "Action": "sts:AssumeRole" }
设置环境
使用以下代码块创建新的 SageMaker AI 会话。这将返回会话的角色 ARN。此角色 ARN 应是您设置为先决条件的执行角色 ARN。
import boto3 import sagemaker import sagemaker.session from sagemaker.workflow.pipeline_context import PipelineSession region = boto3.Session().region_name sagemaker_session = sagemaker.session.Session() role = sagemaker.get_execution_role() default_bucket = sagemaker_session.default_bucket() pipeline_session = PipelineSession() model_package_group_name = f"AbaloneModelPackageGroupName"
创建管道
重要
允许 Amazon SageMaker Studio 或 Amazon SageMaker Studio Classic 创建亚马逊 SageMaker资源的自定义 IAM 策略还必须授予向这些资源添加标签的权限。之所以需要为资源添加标签的权限,是因为 Studio 和 Studio Classic 会自动为创建的任何资源添加标签。如果 IAM 策略允许 Studio 和 Studio Classic 创建资源但不允许标记,则在尝试创建资源时可能会出现 AccessDenied “” 错误。有关更多信息,请参阅 提供标记 A SageMaker I 资源的权限。
Amazon 亚马逊 A SageMaker I 的托管策略授予创建 SageMaker 资源的权限已经包括在创建这些资源时添加标签的权限。
从 SageMaker AI 笔记本实例运行以下步骤,创建包含以下步骤的管道:
-
预处理
-
训练
-
评测
-
条件评估
-
模型注册
注意
您可以使用ExecutionVariablesExecutionVariables在运行时已解析。例如,ExecutionVariables.PIPELINE_EXECUTION_ID 解析为当前执行的 ID,可在不同运行中用作唯一标识符。
步骤 1:下载数据集
此笔记本使用 UCI 机器学习鲍鱼数据集。该数据集包含以下特征:
-
length- 鲍鱼外壳最长测量值。 -
diameter- 垂直于长度方向的鲍鱼直径。 -
height- 带肉鲍鱼在壳内的高度。 -
whole_weight- 整只鲍鱼的重量。 -
shucked_weight- 从鲍鱼身上取出的肉的重量。 -
viscera_weight- 鲍鱼内脏出血后的重量。 -
shell_weight- 去肉和干燥后鲍鱼壳的重量。 -
sex- 鲍鱼的性别。“M”、“F”或“I”中的一个,其中“I”是幼鲍。 -
rings- 鲍鱼壳上的环数。
鲍鱼壳上的环数是其年龄的近似值,计算公式为 age=rings + 1.5。然而,获取这一数字是一项耗时的任务。您必须从锥体上切壳,将切面染色,然后通过显微镜计算环数。不过,其他物理测量数据比较容易获得。此笔记本使用该数据集,利用其他物理测量值来构建 rings 变量的预测模型。
下载数据集
-
将数据集下载到您账户的默认 Amazon S3 存储桶中。
!mkdir -p data local_path = "data/abalone-dataset.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset.csv", local_path ) base_uri = f"s3://{default_bucket}/abalone" input_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(input_data_uri) -
创建模型后,下载第二个数据集进行批量转换。
local_path = "data/abalone-dataset-batch.csv" s3 = boto3.resource("s3") s3.Bucket(f"sagemaker-servicecatalog-seedcode-{region}").download_file( "dataset/abalone-dataset-batch", local_path ) base_uri = f"s3://{default_bucket}/abalone" batch_data_uri = sagemaker.s3.S3Uploader.upload( local_path=local_path, desired_s3_uri=base_uri, ) print(batch_data_uri)
步骤 2:定义管道参数
此代码块为您的管道定义了以下参数:
-
processing_instance_count- 处理作业的实例数。 -
input_data- 输入数据在 Amazon S3 中的位置。 -
batch_data- 用于批量转换的输入数据在 Amazon S3 中的位置。 -
model_approval_status— 注册训练模型的批准状态 CI/CD。有关更多信息,请参阅 使用项目实现 MLOP 自动化 SageMaker。
from sagemaker.workflow.parameters import ( ParameterInteger, ParameterString, ) processing_instance_count = ParameterInteger( name="ProcessingInstanceCount", default_value=1 ) model_approval_status = ParameterString( name="ModelApprovalStatus", default_value="PendingManualApproval" ) input_data = ParameterString( name="InputData", default_value=input_data_uri, ) batch_data = ParameterString( name="BatchData", default_value=batch_data_uri, )
步骤 3:确定特征工程的处理步骤
本节介绍如何创建一个处理步骤,从数据集中准备用于训练的数据。
创建处理步骤
-
为处理脚本创建目录。
!mkdir -p abalone -
在
/abalone目录中创建一个包含以下内容的名为preprocessing.py的文件。该预处理脚本将被传入处理步骤,以便在输入数据上运行。然后,训练步骤使用预处理的训练功能和标签来训练模型。评估步骤使用训练过的模型和预处理过的测试功能和标签对模型进行评估。该脚本使用scikit-learn执行以下操作:-
填入缺失的
sex分类数据并对其进行编码,使其适合训练。 -
缩放和标准化除
rings和sex之外的所有数值字段。 -
将数据拆分为训练、测试和验证数据集。
%%writefile abalone/preprocessing.py import argparse import os import requests import tempfile import numpy as np import pandas as pd from sklearn.compose import ColumnTransformer from sklearn.impute import SimpleImputer from sklearn.pipeline import Pipeline from sklearn.preprocessing import StandardScaler, OneHotEncoder # Because this is a headerless CSV file, specify the column names here. feature_columns_names = [ "sex", "length", "diameter", "height", "whole_weight", "shucked_weight", "viscera_weight", "shell_weight", ] label_column = "rings" feature_columns_dtype = { "sex": str, "length": np.float64, "diameter": np.float64, "height": np.float64, "whole_weight": np.float64, "shucked_weight": np.float64, "viscera_weight": np.float64, "shell_weight": np.float64 } label_column_dtype = {"rings": np.float64} def merge_two_dicts(x, y): z = x.copy() z.update(y) return z if __name__ == "__main__": base_dir = "/opt/ml/processing" df = pd.read_csv( f"{base_dir}/input/abalone-dataset.csv", header=None, names=feature_columns_names + [label_column], dtype=merge_two_dicts(feature_columns_dtype, label_column_dtype) ) numeric_features = list(feature_columns_names) numeric_features.remove("sex") numeric_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="median")), ("scaler", StandardScaler()) ] ) categorical_features = ["sex"] categorical_transformer = Pipeline( steps=[ ("imputer", SimpleImputer(strategy="constant", fill_value="missing")), ("onehot", OneHotEncoder(handle_unknown="ignore")) ] ) preprocess = ColumnTransformer( transformers=[ ("num", numeric_transformer, numeric_features), ("cat", categorical_transformer, categorical_features) ] ) y = df.pop("rings") X_pre = preprocess.fit_transform(df) y_pre = y.to_numpy().reshape(len(y), 1) X = np.concatenate((y_pre, X_pre), axis=1) np.random.shuffle(X) train, validation, test = np.split(X, [int(.7*len(X)), int(.85*len(X))]) pd.DataFrame(train).to_csv(f"{base_dir}/train/train.csv", header=False, index=False) pd.DataFrame(validation).to_csv(f"{base_dir}/validation/validation.csv", header=False, index=False) pd.DataFrame(test).to_csv(f"{base_dir}/test/test.csv", header=False, index=False) -
-
创建要传递到处理步骤的
SKLearnProcessor的实例。from sagemaker.sklearn.processing import SKLearnProcessor framework_version = "0.23-1" sklearn_processor = SKLearnProcessor( framework_version=framework_version, instance_type="ml.m5.xlarge", instance_count=processing_instance_count, base_job_name="sklearn-abalone-process", sagemaker_session=pipeline_session, role=role, ) -
创建处理步骤。此步骤采用
SKLearnProcessor、输入和输出通道以及您创建的preprocessing.py脚本。这与 SageMaker AI Python SDK 中处理器实例的run方法非常相似。传入ProcessingStep的input_data参数是步骤本身的输入数据。处理器实例运行时会使用这些输入数据。请注意在处理作业的输出配置中指定的
"train、"validation和"test"命名通道。这样的步骤Properties可以在后续步骤中使用,并在运行时解析为运行时值。from sagemaker.processing import ProcessingInput, ProcessingOutput from sagemaker.workflow.steps import ProcessingStep processor_args = sklearn_processor.run( inputs=[ ProcessingInput(source=input_data, destination="/opt/ml/processing/input"), ], outputs=[ ProcessingOutput(output_name="train", source="/opt/ml/processing/train"), ProcessingOutput(output_name="validation", source="/opt/ml/processing/validation"), ProcessingOutput(output_name="test", source="/opt/ml/processing/test") ], code="abalone/preprocessing.py", ) step_process = ProcessingStep( name="AbaloneProcess", step_args=processor_args )
步骤 4:确定训练步骤
本节介绍如何使用 SageMaker AI xgBoost 算法根据处理步骤输出的训练数据训练模型。
定义训练步骤
-
指定要保存训练模型的模型路径。
model_path = f"s3://{default_bucket}/AbaloneTrain" -
为 XGBoost 算法和输入数据集配置估算器。训练实例类型传递到估算器中。一个典型的训练脚本:
-
从输入通道加载数据
-
配置超参数训练
-
训练模型
-
将模型保存到
model_dir,以便日后托管
SageMaker AI 在训练作业结束
model.tar.gz时以 a 的形式将模型上传到 Amazon S3。from sagemaker.estimator import Estimator image_uri = sagemaker.image_uris.retrieve( framework="xgboost", region=region, version="1.0-1", py_version="py3", instance_type="ml.m5.xlarge" ) xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, sagemaker_session=pipeline_session, role=role, ) xgb_train.set_hyperparameters( objective="reg:linear", num_round=50, max_depth=5, eta=0.2, gamma=4, min_child_weight=6, subsample=0.7, silent=0 ) -
-
使用估计器实例和
ProcessingStep的属性创建一个TrainingStep。将"train"的S3Uri和"validation"输出通道传递给TrainingStep。from sagemaker.inputs import TrainingInput from sagemaker.workflow.steps import TrainingStep train_args = xgb_train.fit( inputs={ "train": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "train" ].S3Output.S3Uri, content_type="text/csv" ), "validation": TrainingInput( s3_data=step_process.properties.ProcessingOutputConfig.Outputs[ "validation" ].S3Output.S3Uri, content_type="text/csv" ) }, ) step_train = TrainingStep( name="AbaloneTrain", step_args = train_args )
步骤 5:确定模型评测的处理步骤
本节介绍如何创建处理步骤以评估模型的精度。该模型评测的结果用于条件步骤,以确定采取哪种运行路径。
定义模型评测的处理步骤
-
在名为
evaluation.py的/abalone目录中创建一个文件。此脚本在处理步骤中用于执行模型评测。它以经过训练的模型和测试数据集作为输入,然后生成包含分类评估指标的 JSON 文件。%%writefile abalone/evaluation.py import json import pathlib import pickle import tarfile import joblib import numpy as np import pandas as pd import xgboost from sklearn.metrics import mean_squared_error if __name__ == "__main__": model_path = f"/opt/ml/processing/model/model.tar.gz" with tarfile.open(model_path) as tar: tar.extractall(path=".") model = pickle.load(open("xgboost-model", "rb")) test_path = "/opt/ml/processing/test/test.csv" df = pd.read_csv(test_path, header=None) y_test = df.iloc[:, 0].to_numpy() df.drop(df.columns[0], axis=1, inplace=True) X_test = xgboost.DMatrix(df.values) predictions = model.predict(X_test) mse = mean_squared_error(y_test, predictions) std = np.std(y_test - predictions) report_dict = { "regression_metrics": { "mse": { "value": mse, "standard_deviation": std }, }, } output_dir = "/opt/ml/processing/evaluation" pathlib.Path(output_dir).mkdir(parents=True, exist_ok=True) evaluation_path = f"{output_dir}/evaluation.json" with open(evaluation_path, "w") as f: f.write(json.dumps(report_dict)) -
创建
ScriptProcessor的实例,用于创建ProcessingStep。from sagemaker.processing import ScriptProcessor script_eval = ScriptProcessor( image_uri=image_uri, command=["python3"], instance_type="ml.m5.xlarge", instance_count=1, base_job_name="script-abalone-eval", sagemaker_session=pipeline_session, role=role, ) -
创建一个使用处理实例、输入和输出通道以及
evaluation.py脚本的处理器的ProcessingStep。传入:-
step_train训练步骤中的S3ModelArtifacts属性 -
step_process处理步骤的"test"输出通道的S3Uri
这与 SageMaker AI Python SDK 中处理器实例的
run方法非常相似。from sagemaker.workflow.properties import PropertyFile evaluation_report = PropertyFile( name="EvaluationReport", output_name="evaluation", path="evaluation.json" ) eval_args = script_eval.run( inputs=[ ProcessingInput( source=step_train.properties.ModelArtifacts.S3ModelArtifacts, destination="/opt/ml/processing/model" ), ProcessingInput( source=step_process.properties.ProcessingOutputConfig.Outputs[ "test" ].S3Output.S3Uri, destination="/opt/ml/processing/test" ) ], outputs=[ ProcessingOutput(output_name="evaluation", source="/opt/ml/processing/evaluation"), ], code="abalone/evaluation.py", ) step_eval = ProcessingStep( name="AbaloneEval", step_args=eval_args, property_files=[evaluation_report], ) -
步骤 6: CreateModelStep 为批量转换定义一个
重要
我们建议使用从 P 模型步骤 ython 软件开发工具包的 2.90.0 版本开始创建模型。 SageMaker CreateModelStep将继续在以前版本的 SageMaker Python SDK 中运行,但不再受支持。
本节介绍如何根据训练步骤的输出创建 SageMaker AI 模型。此模型用于对新数据集进行批量转换。该步骤会传入条件步骤,只有当条件步骤的结果为 true 时才会运行。
CreateModelStep 为批量转换定义一个
-
创建 A SageMaker I 模型。从
step_train训练步骤传入S3ModelArtifacts属性。from sagemaker.model import Model model = Model( image_uri=image_uri, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, sagemaker_session=pipeline_session, role=role, ) -
为 SageMaker AI 模型定义模型输入。
from sagemaker.inputs import CreateModelInput inputs = CreateModelInput( instance_type="ml.m5.large", accelerator_type="ml.eia1.medium", ) -
CreateModelStep使用您定义的CreateModelInput和 SageMaker AI 模型实例创建您的。from sagemaker.workflow.steps import CreateModelStep step_create_model = CreateModelStep( name="AbaloneCreateModel", model=model, inputs=inputs, )
步骤 7:定义一个 TransformStep 以执行批量转换
本节介绍如何在模型训练完毕后创建 TransformStep 以对数据集执行批量转换。该步骤会传入条件步骤,只有当条件步骤的结果为 true 时才会运行。
要定义 TransformStep 要执行批量转换
-
使用适当的计算实例类型、实例数量和所需的输出 Amazon S3 存储桶 URI 创建转换器实例。从
step_create_modelCreateModel步骤传入ModelName属性。from sagemaker.transformer import Transformer transformer = Transformer( model_name=step_create_model.properties.ModelName, instance_type="ml.m5.xlarge", instance_count=1, output_path=f"s3://{default_bucket}/AbaloneTransform" ) -
使用您定义的转换器实例和
batch_data管道参数创建TransformStep。from sagemaker.inputs import TransformInput from sagemaker.workflow.steps import TransformStep step_transform = TransformStep( name="AbaloneTransform", transformer=transformer, inputs=TransformInput(data=batch_data) )
步骤 8:定义创建模型包的 RegisterModel 步骤
重要
我们建议使用从 P 模型步骤 ython SDK 版本 2.90.0 起注册模型。 SageMaker RegisterModel将继续在以前版本的 SageMaker Python SDK 中运行,但不再受支持。
本节将介绍如何创建 RegisterModel 实例。在管道中运行 RegisterModel 的结果是一个模型软件包。模型包是一种可重复使用的模型构件抽象,它封装了推理所需的所有要素。它由一个定义要使用的推理映像的推理规范和一个可选的模型权重位置组成。模型包组是模型包的集合。您可以为管道使用 ModelPackageGroup,为每次管道运行向组中添加新版本和模型软件包。有关模型注册表的更多信息,请参阅利用模型注册中心进行模型注册部署。
该步骤会传入条件步骤,只有当条件步骤的结果为 true 时才会运行。
定义创建模型包的 RegisterModel 步骤
-
使用您用于训练步骤的估算器实例构造一个
RegisterModel步骤。从step_train训练步骤传入S3ModelArtifacts属性并指定ModelPackageGroup。Pipelines 会为您创建此ModelPackageGroup。from sagemaker.model_metrics import MetricsSource, ModelMetrics from sagemaker.workflow.step_collections import RegisterModel model_metrics = ModelMetrics( model_statistics=MetricsSource( s3_uri="{}/evaluation.json".format( step_eval.arguments["ProcessingOutputConfig"]["Outputs"][0]["S3Output"]["S3Uri"] ), content_type="application/json" ) ) step_register = RegisterModel( name="AbaloneRegisterModel", estimator=xgb_train, model_data=step_train.properties.ModelArtifacts.S3ModelArtifacts, content_types=["text/csv"], response_types=["text/csv"], inference_instances=["ml.t2.medium", "ml.m5.xlarge"], transform_instances=["ml.m5.xlarge"], model_package_group_name=model_package_group_name, approval_status=model_approval_status, model_metrics=model_metrics )
步骤 9:定义条件步骤以验证模型的准确性
ConditionStep 允许 Pipelines 根据步骤属性的条件在管道 DAG 中支持有条件运行。在这种情况下,只有当模型的精度超过要求值时,才需要注册模型软件包。模型的准确性由模型评测步骤决定。如果精度超过所需值,管道还会创建 A SageMaker I 模型并对数据集运行批量转换。本节介绍如何定义条件步骤。
定义条件步骤以验证模型精度
-
使用模型评测处理步骤
step_eval的输出中找到的精度值定义ConditionLessThanOrEqualTo条件。使用您在处理步骤中编制索引的属性文件以及均方误差值"mse"的相应 JSONPath 来获取此输出。from sagemaker.workflow.conditions import ConditionLessThanOrEqualTo from sagemaker.workflow.condition_step import ConditionStep from sagemaker.workflow.functions import JsonGet cond_lte = ConditionLessThanOrEqualTo( left=JsonGet( step_name=step_eval.name, property_file=evaluation_report, json_path="regression_metrics.mse.value" ), right=6.0 ) -
构造一个
ConditionStep。传入ConditionEquals条件,如果条件通过,则将模型包注册和批量转换步骤设置为后续步骤。step_cond = ConditionStep( name="AbaloneMSECond", conditions=[cond_lte], if_steps=[step_register, step_create_model, step_transform], else_steps=[], )
步骤 10:创建管道
现在,您已经创建了所有步骤,请将它们组合成一个管道。
创建管道
-
为您的管道定义以下内容:
name、parameters和steps。名称在(account, region)对中必须唯一。注意
一个步骤只能在工作流的步骤列表或条件步骤的 if/else步骤列表中出现一次。不能同时出现在两者中。
from sagemaker.workflow.pipeline import Pipeline pipeline_name = f"AbalonePipeline" pipeline = Pipeline( name=pipeline_name, parameters=[ processing_instance_count, model_approval_status, input_data, batch_data, ], steps=[step_process, step_train, step_eval, step_cond], ) -
(可选)检查 JSON 管道定义以确保其格式正确。
import json json.loads(pipeline.definition())
此管道定义已准备好提交给 SageMaker AI。在下一个教程中,您将此管道提交给 SageMaker AI 并开始运行。
您也可以使用 boto3
{'Version': '2020-12-01', 'Metadata': {}, 'Parameters': [{'Name': 'ProcessingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ProcessingInstanceCount', 'Type': 'Integer', 'DefaultValue': 1}, {'Name': 'TrainingInstanceType', 'Type': 'String', 'DefaultValue': 'ml.m5.xlarge'}, {'Name': 'ModelApprovalStatus', 'Type': 'String', 'DefaultValue': 'PendingManualApproval'}, {'Name': 'ProcessedData', 'Type': 'String', 'DefaultValue': 'S3_URL', {'Name': 'InputDataUrl', 'Type': 'String', 'DefaultValue': 'S3_URL', 'PipelineExperimentConfig': {'ExperimentName': {'Get': 'Execution.PipelineName'}, 'TrialName': {'Get': 'Execution.PipelineExecutionId'}}, 'Steps': [{'Name': 'ReadTrainDataFromFS', 'Type': 'Processing', 'Arguments': {'ProcessingResources': {'ClusterConfig': {'InstanceType': 'ml.m5.4xlarge', 'InstanceCount': 2, 'VolumeSizeInGB': 30}}, 'AppSpecification': {'ImageUri': 'IMAGE_URI', 'ContainerArguments': [....]}, 'RoleArn': 'ROLE', 'ProcessingInputs': [...], 'ProcessingOutputConfig': {'Outputs': [.....]}, 'StoppingCondition': {'MaxRuntimeInSeconds': 86400}}, 'CacheConfig': {'Enabled': True, 'ExpireAfter': '30d'}}, ... ... ... }
下一步:运行管道