本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
准备数据集
在此步骤中,您将使用 SHAP (SHapley Additive exPlanations) 库将 Adult Census 数据集
要运行以下示例,请将示例代码粘贴到笔记本实例的单元格中。
使用 SHAP 加载 Adult Census 数据集
使用 SHAP 库,导入 Adult Census 数据集,如下所示:
import shap X, y = shap.datasets.adult() X_display, y_display = shap.datasets.adult(display=True) feature_names = list(X.columns) feature_names
注意
如果当前的 Jupyter 内核没有 SHAP 库,请运行以下 conda 命令来安装该库:
%conda install -c conda-forge shap
如果您正在使用 JupyterLab,则必须在安装和更新完成后手动刷新内核。运行以下 IPython 脚本关闭内核(内核将自动重启):
import IPython IPython.Application.instance().kernel.do_shutdown(True)
feature_names list 对象应返回以下功能列表:
['Age', 'Workclass', 'Education-Num', 'Marital Status', 'Occupation', 'Relationship', 'Race', 'Sex', 'Capital Gain', 'Capital Loss', 'Hours per week', 'Country']
提示
如果您从未标记的数据开始,则可以使用 Amazon Ground T SageMaker ruth 在几分钟内创建数据标签工作流程。要了解更多信息,请参阅标注数据。
数据集概览
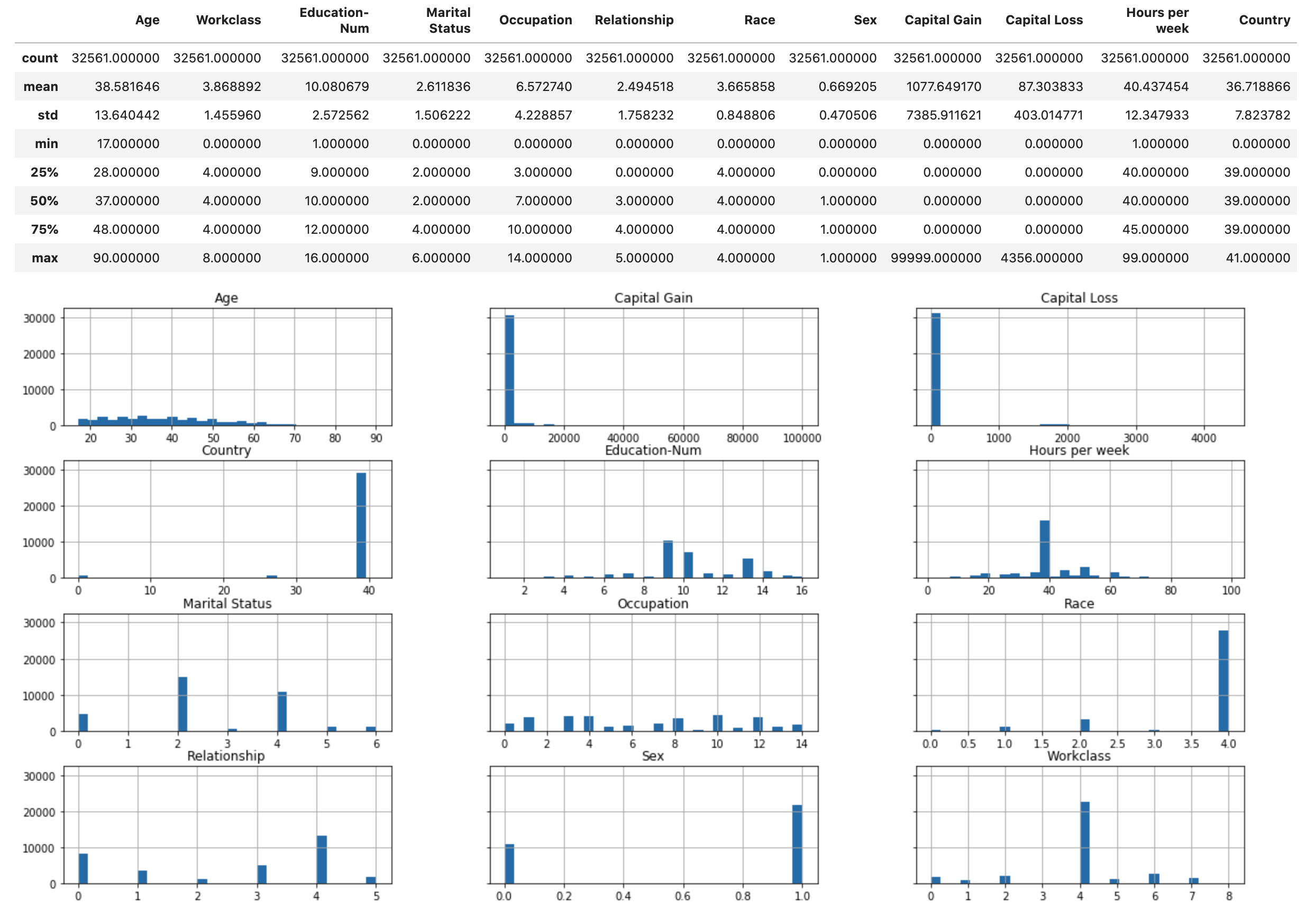
运行以下脚本,显示数据集的统计概览和数字特征的直方图。
display(X.describe()) hist = X.hist(bins=30, sharey=True, figsize=(20, 10))
提示
如果您想使用需要清理和转换的数据集,则可以使用 Amazon Data Wrangler 简化和简化 SageMaker 数据预处理和功能工程。要了解更多信息,请参阅使用 Amazon Data Wrangler 准备机器学习 SageMaker 数据。
将数据集拆分为训练、验证和测试数据集
使用 Sklearn,将数据集拆分为训练集和测试集。训练集用于训练模型,而测试集用于评估最终训练模型的性能。使用固定的随机种子对数据集进行随机排序:80% 的数据集用于训练集,20% 的数据集用于测试集。
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=1) X_train_display = X_display.loc[X_train.index]
拆分训练集以分离出验证集。验证集用于评估训练模型的性能,同时调整模型的超参数。75% 的训练集成为最终的训练集,其余的则成为验证集。
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=1) X_train_display = X_display.loc[X_train.index] X_val_display = X_display.loc[X_val.index]
使用 pandas 软件包,通过将数字特征与真实标签连接起来,显式地对齐每个数据集。
import pandas as pd train = pd.concat([pd.Series(y_train, index=X_train.index, name='Income>50K', dtype=int), X_train], axis=1) validation = pd.concat([pd.Series(y_val, index=X_val.index, name='Income>50K', dtype=int), X_val], axis=1) test = pd.concat([pd.Series(y_test, index=X_test.index, name='Income>50K', dtype=int), X_test], axis=1)
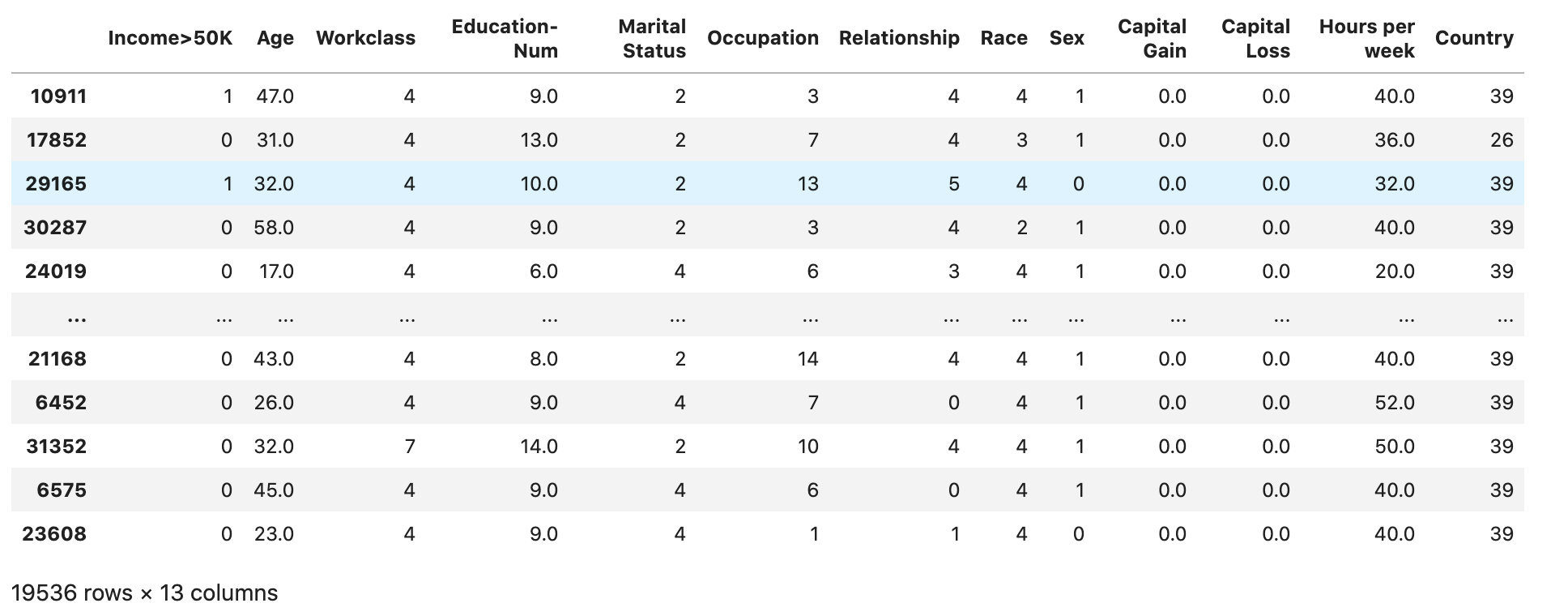
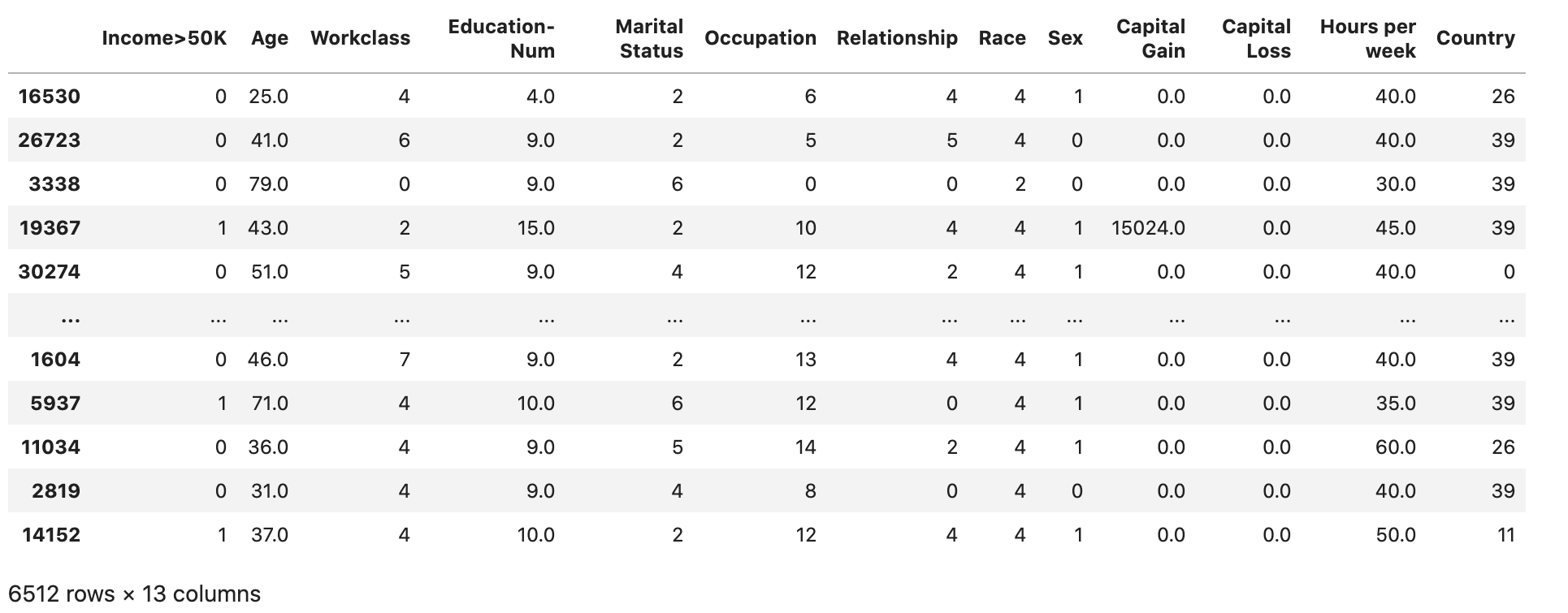
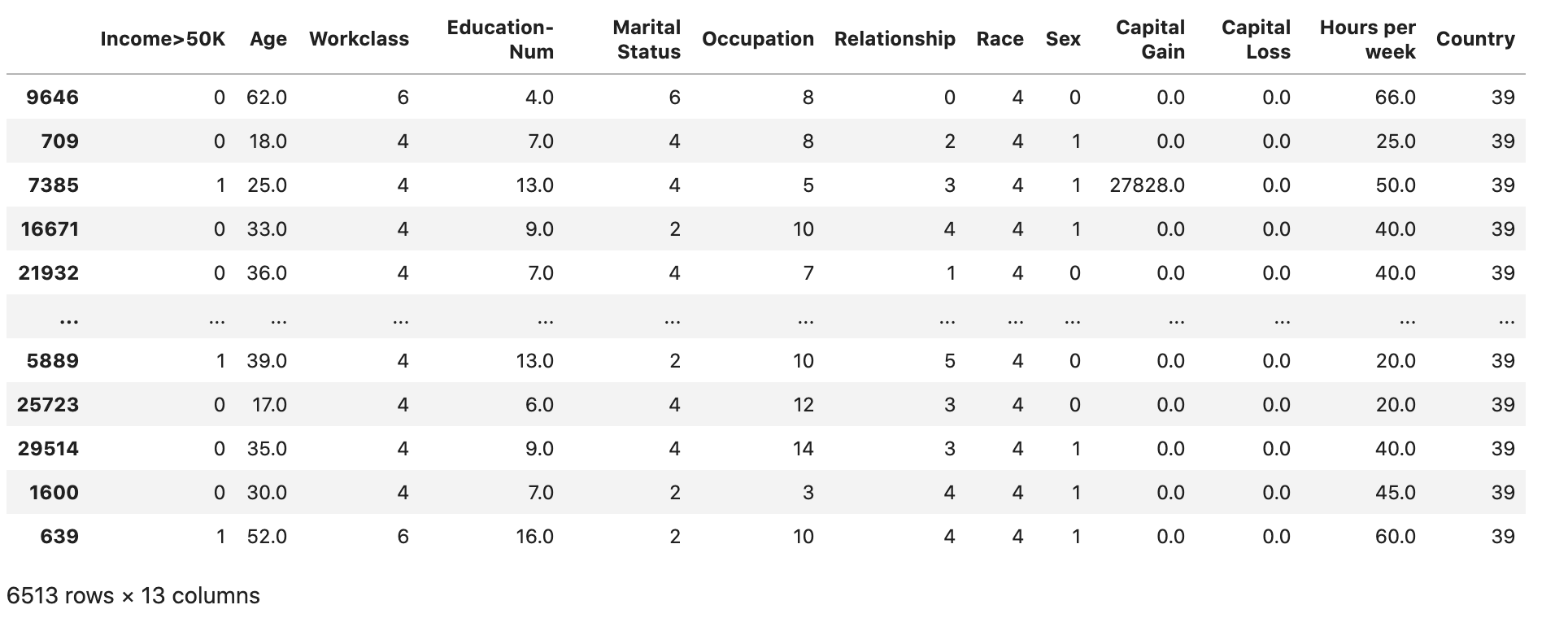
检查数据集是否按预期进行拆分和结构化:
train
validation
test
将训练数据集和验证数据集转换为 CSV 文件
将 train 和 validation dataframe 对象转换为 CSV 文件,以匹配 XGBoost 算法的输入文件格式。
# Use 'csv' format to store the data # The first column is expected to be the output column train.to_csv('train.csv', index=False, header=False) validation.to_csv('validation.csv', index=False, header=False)
将数据集上传到 Amazon S3
使用 SageMaker AI 和 Boto3,将训练和验证数据集上传到默认 Amazon S3 存储桶。Amazon EC2 上的计算优化 SageMaker实例将使用 S3 存储桶中的数据集进行训练。
以下代码为您当前 SageMaker AI 会话设置默认 S3 存储桶 URI,创建新demo-sagemaker-xgboost-adult-income-prediction文件夹,并将训练和验证数据集上传到该data子文件夹。
import sagemaker, boto3, os bucket = sagemaker.Session().default_bucket() prefix = "demo-sagemaker-xgboost-adult-income-prediction" boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/train.csv')).upload_file('train.csv') boto3.Session().resource('s3').Bucket(bucket).Object( os.path.join(prefix, 'data/validation.csv')).upload_file('validation.csv')
运行以下命令 Amazon CLI 以检查 CSV 文件是否已成功上传到 S3 存储桶。
! aws s3 ls {bucket}/{prefix}/data --recursive
这应该返回以下输出内容:
