本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon Data Wrangler 准备机器学习 SageMaker 数据
重要
亚马逊 SageMaker Data Wrangler 已集成到亚马 SageMaker 逊 Canvas 中。在 Can SageMaker vas 中的全新 Data Wrangler 体验中,除了可视化界面外,您还可以使用自然语言界面来探索和转换数据。有关 Canvas 中的 Data Wrangler 的更多信息, SageMaker 请参阅。数据准备
Amazon SageMaker Data Wrangler(Data Wrangler)是 Amazon SageMaker Studio Classic 的一项功能,它为导入、准备、转换、特征化和分析数据提供了端到端解决方案。您可以将 Data Wrangler 数据准备流集成到机器学习 (ML) 工作流中,以简化和精简数据预处理和特征工程,只需少量甚至无需编码。您还可以添加自己的 Python 脚本和转换,以自定义工作流。
Data Wrangler 可提供以下核心功能,帮助您分析和准备用于机器学习应用程序的数据。
-
导入 — 连接亚马逊简单存储服务 (Amazon S3)、(Athena)、亚马逊 Redshift、Snow Amazon Athena flake 和 Databricks 并从中导入数据。
-
数据流 – 创建数据流以定义一系列机器学习数据准备步骤。您可以使用流合并来自不同数据源的数据集,确定要应用于数据集的转换数量和类型,并定义可集成到机器学习管线中的数据准备工作流。
-
转换 – 使用标准转换(如字符串、矢量和数字数据格式化工具)清理和转换数据集。使用文本和 date/time 嵌入等变换以及分类编码来展示您的数据。
-
生成数据见解 – 使用 Data Wrangler 数据见解和质量报告,自动验证数据质量并检测数据中的异常。
-
分析 – 在流中的任意点分析数据集中的特征。Data Wrangler 包括内置的数据可视化工具,如散点图和直方图,以及目标泄漏分析和快速建模等数据分析工具,以了解特征相关性。
-
导出 – 将数据准备工作流导出至其他位置。以下是一些示例位置:
-
Amazon Simple Storage Service(Amazon S3)桶
-
Amazon P SageMaker ipelines — 使用管道自动部署模型。您可以将转换后的数据直接导出至管线。
-
Amazon F SageMaker eature Store — 将功能及其数据存储在中央存储中。
-
Python 脚本 – 将数据及其转换存储在 Python 脚本中,用于您的自定义工作流。
-
要开始使用 Data Wrangler,请参阅开始使用 Data Wrangler。
重要
Data Wrangler 不再支持 Jupyter Lab 版本 1 (JL1)。要访问最新功能和更新,请更新为 Jupyter Lab 版本 3。有关升级的更多信息,请参阅从控制台查看和更新应用程序的 JupyterLab 版本。
重要
本指南中的信息和程序使用最新版本的 Amazon SageMaker Studio Classic。有关将 Studio Classic 升级到最新版本的信息,请参阅 亚马逊 SageMaker Studio 经典用户界面概述。
您必须使用 Studio Classic 1.3.0 或更高版本。使用以下步骤打开 Amazon SageMaker Studio Classic 并查看您正在运行哪个版本。
要打开 Studio Classic 并检查其版本,请参阅以下步骤。
-
按照中的先决条件步骤通过 Amazon SageMaker Studio Classic 访问 Data Wrangler。
-
在要用来启动 Studio Classic 的用户旁边,选择启动应用程序。
-
选择 Studio。
-
Studio Classic 载入后,选择文件,然后选择新建,再选择终端。
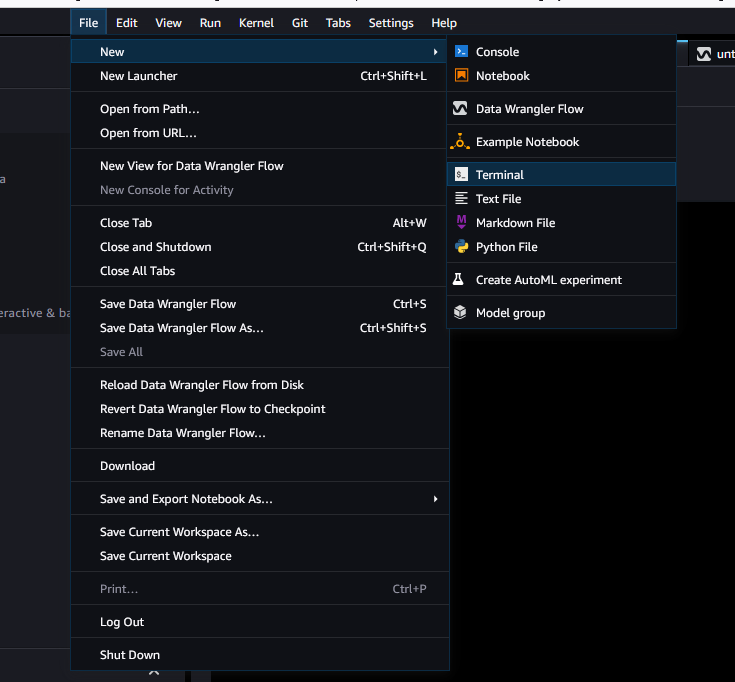
-
启动 Studio Classic 后,选择文件,然后选择新建,再选择终端。
-
输入
cat /opt/conda/share/jupyter/lab/staging/yarn.lock | grep -A 1 "@amzn/sagemaker-ui-data-prep-plugin@",打印 Studio Classic 实例的版本。您必须安装 Studio Classic 1.3.0 版本才能使用 Snowflake。
您可以从内部更新 Amazon SageMaker Studio Classic Amazon Web Services 管理控制台。有关更新 Studio Classic 的更多信息,请参阅 亚马逊 SageMaker Studio 经典用户界面概述。