本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
开始使用 Data Wrangler
Amazon SageMaker Data Wrangler 是亚马逊 SageMaker Studio Classic 中的一项功能。使用此部分学习如何访问和开始使用 Data Wrangler。执行以下操作:
-
完成 先决条件 中的每个步骤。
-
按照 访问 Data Wrangler 中的步骤开始使用 Data Wrangler。
先决条件
要使用 Data Wrangler,您必须完成以下必备步骤。
-
要使用 Data Wrangler,您需要访问 Amazon Elastic Compute Cloud (Amazon EC2) 实例。有关可使用的 Amazon EC2 实例的更多信息,请参阅 实例。要了解如何查看配额以及根据需要申请增加配额,请参阅 Amazon 服务限额。
-
配置 安全性和权限 中介绍的必要权限。
-
如果您所在企业使用的是阻止互联网流量的防火墙,则您必须有权访问以下 URL:
-
https://ui.prod-1.data-wrangler.sagemaker.aws/ -
https://ui.prod-2.data-wrangler.sagemaker.aws/ -
https://ui.prod-3.data-wrangler.sagemaker.aws/ -
https://ui.prod-4.data-wrangler.sagemaker.aws/
-
要使用 Data Wrangler,您需要一个活动的 Studio Classic 实例。要了解如何启动新实例,请参阅 亚马逊 SageMaker AI 域名概述。当您的 Studio Classic 实例为就绪时,请使用 访问 Data Wrangler 中的说明。
访问 Data Wrangler
以下过程假定您已完成 先决条件。
要在 Studio Classic 中访问 Data Wrangler,请执行以下操作。
-
登录 Studio Classic。有关更多信息,请参阅 亚马逊 SageMaker AI 域名概述。
-
选择 Studio。
-
选择启动应用程序。
-
从下拉列表中选择 Studio。
-
选择主页图标。
-
选择数据。
-
选择 Data Wrangler。
-
您也可以执行以下操作,来创建 Data Wrangler 流。
-
在顶部导航栏中,选择文件。
-
选择新建。
-
选择 Data Wrangler 流。

-
-
(可选)重命名新目录和 .flow 文件。
-
在 Studio Classic 中创建新的 .flow 文件时,您可能会看到一个向您介绍 Data Wrangler 的旋转木马。
该过程可能需要几分钟。
只要您的 “用户详细信息” 页面上的KernelGateway应用程序处于 “待处理” 状态,此消息就会一直存在。要查看此应用程序的状态,请在 A mazon SageMaker Studio Classic 页面的 A SageMaker I 控制台中,选择您用于访问 Studio Classic 的用户名。在用户详细信息页面上,您可以在 “KernelGateway应用程序” 下看到一个应用程序。等待此应用程序状态变为准备就绪,再开始使用 Data Wrangler。首次启动 Data Wrangler 时,可能需要大约 5 分钟时间。

-
要开始使用,请选择一个数据来源并使用它导入数据集。要了解更多信息,请参阅 导入。
导入数据集时,该数据集会显示在您的数据流中。要了解更多信息,请参阅创建和使用 Data Wrangler 流。
-
导入数据集后,Data Wrangler 会自动推断每个列中的数据类型。选择数据类型步骤旁边的 +,然后选择编辑数据类型。
重要
在数据类型步骤中添加转换后,您无法使用更新类型批量更新列类型。
-
要导出完整的数据流,请选择导出,然后选择导出选项。要了解更多信息,请参阅导出。
-
最后,选择组件和注册表图标,然后从下拉列表中选择 Data Wrangler,以查看您创建的所有 .flow 文件。可以使用此菜单在数据流之间查找和移动。
启动 Data Wrangler 后,可以使用以下部分了解如何使用 Data Wrangler 创建机器学习数据准备流程。
更新 Data Wrangler
我们建议您定期更新 Data Wrangler Studio Classic 应用程序,以访问最新功能和更新。Data Wrangler 应用程序名称以 sagemaker-data-wrang 开头。要了解如何更新 Studio Classic 应用程序,请参阅 关闭并更新 Amazon SageMaker Studio 经典版应用程序。
演示:Data Wrangler Titanic 数据集演练
下面几个部分提供了演练,可协助您了解如何使用 Data Wrangler。本演练假设您已按照 访问 Data Wrangler 中的步骤操作,并打开了要用于演示的新数据流文件。您可能需要将此 .flow 文件重命名为类似于 titanic-demo.flow 这样的名称。
本演练使用 Titanic 数据集
在本教程中,您会执行以下步骤。
-
请执行以下操作之一:
-
打开 Data Wrangler 流,然后选择使用样本数据集。
-
将 Titanic 数据集
上传到 Amazon Simple Storage Service (Amazon S3),然后导入到 Data Wrangler。
-
-
使用 Data Wrangler 分析来分析此数据集。
-
使用 Data Wrangler 数据转换来定义数据流。
-
将您的流导出到 Jupyter 笔记本中,您可以用它来创建 Data Wrangler 作业。
-
处理您的数据,然后开始 SageMaker 训练作业,训练 XGBoost 二进制分类器。
将数据集上传到 S3 并导入
在开始时,您可以使用以下方法之一,将 Titanic 数据集导入到 Data Wrangler:
-
直接从 Data Wrangler 流导入数据集
-
将数据集上传到 Amazon S3,然后导入到 Data Wrangler
要将数据集直接导入到 Data Wrangler,请打开该流,然后选择使用样本数据集。
将数据集上传到 Amazon S3 并导入到 Data Wrangler 时,更接近导入自己的数据的体验。以下信息向您介绍如何上传和导入数据集。
开始将数据导入到 Data Wrangler 之前,请下载 Titanic 数据集
如果您是 Amazon S3 的新用户,可以在 Amazon S3 控制台中,通过拖放操作来完成此操作。要了解如何操作,请参阅《Amazon Simple Storage Service 用户指南》中的使用拖放功能上传文件和文件夹。
重要
将您的数据集上传到您要用于完成此演示的同一 Amazon 区域的 S3 存储桶。
当数据集成功上传到 Amazon S3 后,您可以将该数据集导入到 Data Wrangler。
将 Titanic 数据集导入到 Data Wrangler
-
在数据流选项卡中选择导入数据按钮,或者选择导入选项卡。
-
选择 Amazon S3。
-
使用从 S3 导入数据集表,查找已将 Titanic 数据集添加到的存储桶。选择 Titanic 数据集 CSV 文件以打开详细信息窗格。
-
在详细信息下,文件类型应该为 CSV。选中第一行是标题,指定数据集的第一行是标题。您还可以将数据集命名为更友好的名称,例如
Titanic-train。 -
选择导入按钮。
将数据集导入到 Data Wrangler 后,该数据集会显示在数据流选项卡中。可以双击节点进入节点详细信息视图,在其中可以添加转换或分析。可以使用加号图标快速访问导航方式。在下一个部分中,您将会使用此数据流添加分析和转换步骤。
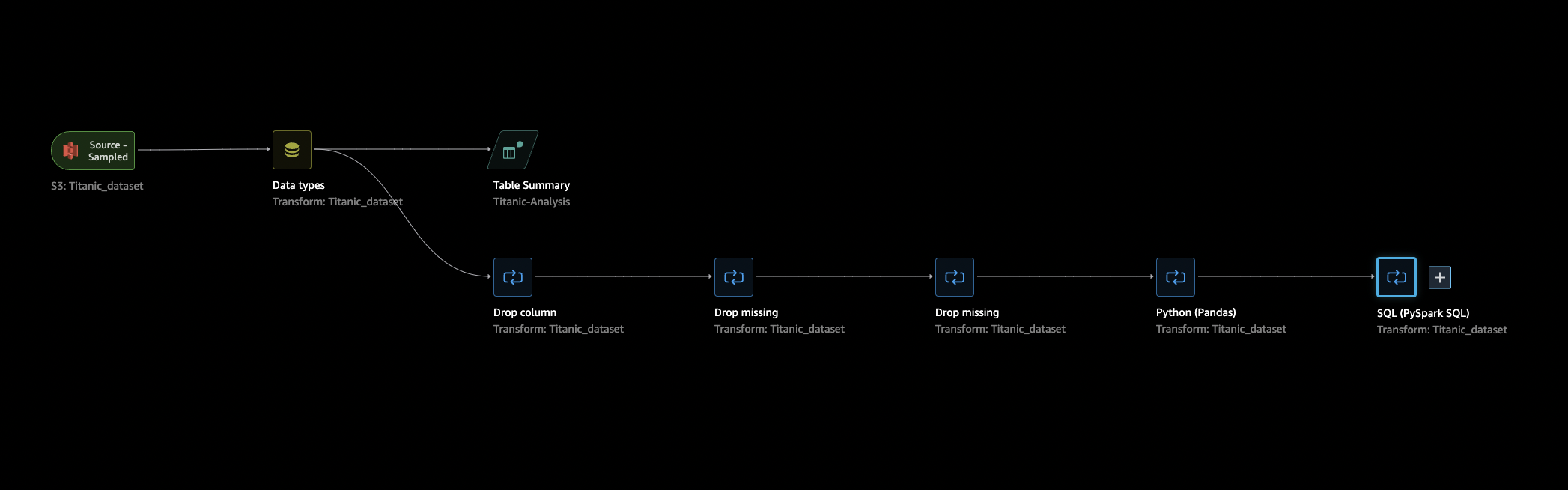
数据流
在数据流部分中,数据流中仅有的步骤是您最近导入数据集的步骤和一个数据类型步骤。在应用转换后,可以返回到此选项卡,查看数据流的具体情况。现在,在准备和分析选项卡下,添加一些基本的转换。
准备和可视化
Data Wrangler 具有内置的转换和可视化功能,可用于分析、清理和转换您的数据。
在节点详细信息视图的数据选项卡中,右侧面板列出了所有内置转换,其中还包含一个可添加自定义转换的区域。以下使用场景展示了如何使用这些转换。
要获取可协助您进行数据探索和特征工程的信息,请创建数据质量和见解报告。报告中的信息有助于您清理和处理数据。该报告为您提供诸如缺失值数量和异常值数量之类的信息。如果您的数据存在问题,例如目标泄漏或不平衡,则见解报告可以让您注意到这些问题。有关创建报告的更多信息,请参阅 获取有关数据和数据质量的见解。
数据探究
首先,使用分析创建数据的表摘要。执行以下操作:
-
选择数据流中数据类型步骤旁边的 +,然后选择添加分析。
-
在分析区域中,从下拉列表中选择表摘要。
-
为表摘要指定名称。
-
选择预览以预览将要创建的表。
-
选择保存,将其保存到您的数据流中。数据显示在所有分析下。
使用看到的统计数据,您可以对该数据集得到类似以下内容的观测结果:
-
平均票价(平均值)约为 33 美元,最高票价超过 500 美元。此列可能有异常值。
-
该数据集使用 ? 来表示缺失值。许多列都有缺失值:cabin、embarked 和 home.dest
-
年龄类别缺少超过 250 个值。
接下来,使用从这些统计数据获得的见解来清理您的数据。
删除未使用的列
利用上一部分中的分析,清理数据集,为训练做好准备。要向数据流添加新的转换,请选择数据流中数据类型步骤旁边的 +,然后选择添加转换。
首先,删除您不希望用于训练的列。可以使用 pandas
通过以下步骤来删除未使用的列。
删除未使用的列。
-
打开 Data Wrangler 流。
-
Data Wrangler 流中有两个节点。选择数据类型节点右侧的 +。
-
选择添加转换。
-
在所有步骤列中,选择添加步骤。
-
在标准转换列表中,选择管理列。标准转换是现成的内置转换。确保选中删除列。
-
在要删除的列下,选中以下列名:
-
cabin
-
ticket
-
name
-
sibsp
-
parch
-
home.dest
-
boat
-
body
-
-
选择预览。
-
验证这些列是否已删除,然后选择添加。
要使用 pandas 执行此操作,请按照以下步骤操作。
-
在所有步骤列中,选择添加步骤。
-
在自定义转换列表中,选择自定义转换。
-
为您的转换提供名称,然后从下拉列表中选择 Python (Pandas)。
-
在代码框中输入以下 Python 脚本。
cols = ['name', 'ticket', 'cabin', 'sibsp', 'parch', 'home.dest','boat', 'body'] df = df.drop(cols, axis=1) -
选择预览以预览更改,然后选择添加以添加转换。
清理缺失值
现在清理缺失的值。您可以使用处理缺失值转换组来执行此操作。
许多列有缺失值。在其余列中,age 和 fare 包含缺失值。使用自定义转换进行检查。
使用 Python (Pandas) 选项,通过以下命令快速查看每个列中的条目数量:
df.info()
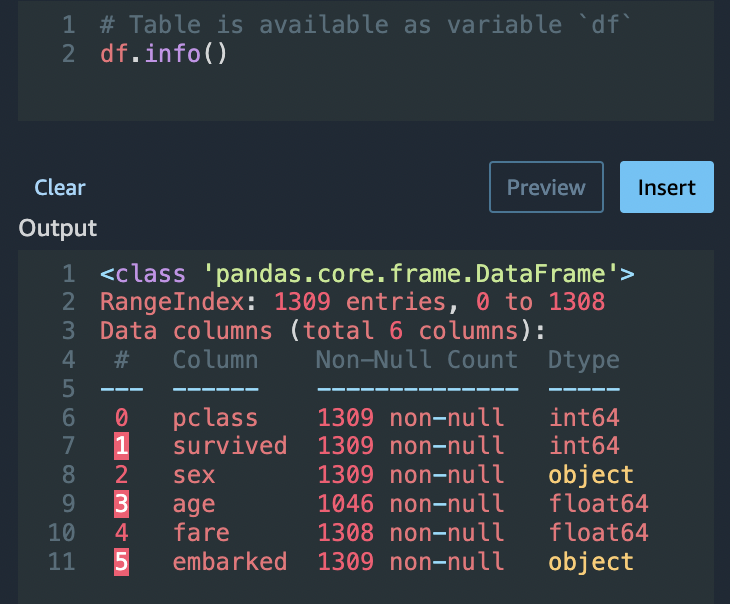
要删除 age 类别中缺少值的行,请执行以下操作:
-
选择处理缺失值。
-
为转换器选择删除缺失值。
-
为输入列选择 age。
-
选择预览查看新的数据框,然后选择添加,将转换添加到您的流中。
-
对 fare 重复同样的过程。
您可以在自定义转换部分中使用 df.info(),来确认所有行现在都有 1045 个值。
自定义 Pandas:编码
尝试使用 Pandas 进行平面编码。对分类数据进行编码是为分类创建数字表示形式的过程。例如,如果您的分类是 Dog 和 Cat,则可以将此信息编码为两个向量:[1,0] 表示 Dog,[0,1] 表示 Cat。
-
在自定义转换部分中,从下拉列表中选择 Python (Pandas)。
-
在代码框中,输入以下内容。
import pandas as pd dummies = [] cols = ['pclass','sex','embarked'] for col in cols: dummies.append(pd.get_dummies(df[col])) encoded = pd.concat(dummies, axis=1) df = pd.concat((df, encoded),axis=1) -
选择预览以预览更改。将每个列的编码版本添加到数据集内。
-
选择添加来添加转换。
自定义 SQL:SELECT 列
现在,选择要继续使用 SQL 的列。对于此演示,请选择以下 SELECT 语句中列出的列。因为 survived 是训练的目标列,所以将该列放在第一位。
-
在 “自定义转换” 部分,从下拉列表中选择 PySpark SQL (SQL)。
-
在代码框中,输入以下内容。
SELECT survived, age, fare, 1, 2, 3, female, male, C, Q, S FROM df; -
选择预览以预览更改。您的
SELECT语句中列出的列仅仅是剩余的列。 -
选择添加来添加转换。
导出到 Data Wrangler 笔记本
完成创建数据流后,可以选择多种导出选项。以下部分介绍如何导出到 Data Wrangler 作业笔记本。Data Wrangler 作业用于通过数据流中定义的步骤来处理您的数据。要了解有关所有导出选项的更多信息,请参阅 导出。
导出到 Data Wrangler 作业笔记本
使用 Data Wrangler 作业导出数据流时,该过程会自动创建 Jupyter 笔记本。此笔记本会自动在您的 Studio Classic 实例中打开,并配置为运行 SageMaker 处理作业来运行您的 Data Wrangler 数据流,这被称为数据牧马人作业。
-
保存数据流。选择文件,然后选择保存 Data Wrangler 流。
-
返回到数据流选项卡,选择数据流 (SQL) 中的最后一步,然后选择 + 以打开导航。
-
选择导出,然后选择 Amazon S3(通过 Jupyter 笔记本)。这将打开 Jupyter 笔记本。
-
为内核选择任何 Python 3 (Data Science) 内核。
-
当内核启动时,运行笔记本书中的单元格,直到 Kick off Trainin SageMaker g Job(可选)。
-
或者,如果您想创建 SageMaker AI SageMaker训练作业来训练 XGBoost 分类器,则可以在 Kick off Training Job(可选)中运行单元格。您可以在 Amazon Pricin SageMaker g 中找到开展培训工作的 SageMaker 费用
。 或者,您可以将 训练 XGBoost 分类器 中的代码块添加到笔记本中并运行,以使用 XGBoost
开源库来训练 XGBoost 分类器。 -
取消注释并在 C leanup 下运行单元格,然后运行它以将 Pyth SageMaker on SDK 恢复到其原始版本。
您可以在 SageMaker AI 控制台的 “处理” 选项卡中监控您的 Data Wrangler 作业状态。此外,您还可以使用 Amazon 监控您的 Data Wrangler 作业。 CloudWatch有关更多信息,请参阅使用 CloudWatch 日志和指标监控 Amazon SageMaker 处理任务。
如果您启动了训练作业,则可以使用 SageMaker AI 控制台在 “训练” 部分的 “训练作业” 下方监控其状态。
训练 XGBoost 分类器
你可以使用 Jupyter 笔记本或 Amazon Autopilot 来训练 XGBoost 二进制分类器。 SageMaker 可以使用 Autopilot,根据直接从 Data Wrangler 流转换的数据自动训练和优化模型。有关 Autopilot 的信息,请参阅 根据您的数据流自动训练模型。
在启动 Data Wrangler 作业的同一个笔记本中,可以使用准备好的数据提取数据并训练 XGBoost 二进制分类器,只需最少的数据准备工作。
-
首先,使用
pip升级必要的模块,然后删除 _SUCCESS 文件(最后一个文件在使用awswrangler时有问题)。! pip install --upgrade awscli awswrangler boto sklearn ! aws s3 rm {output_path} --recursive --exclude "*" --include "*_SUCCESS*" -
从 Amazon S3 读取数据。可以使用
awswrangler递归读取 S3 前缀中的所有 CSV 文件。然后,将数据拆分为特征和标签。标签是数据框的第一列。import awswrangler as wr df = wr.s3.read_csv(path=output_path, dataset=True) X, y = df.iloc[:,:-1],df.iloc[:,-1]-
最后,创建 DMatrices(数据的 XGBoost 基元结构),然后使用 XGBoost 二进制分类执行交叉验证。
import xgboost as xgb dmatrix = xgb.DMatrix(data=X, label=y) params = {"objective":"binary:logistic",'learning_rate': 0.1, 'max_depth': 5, 'alpha': 10} xgb.cv( dtrain=dmatrix, params=params, nfold=3, num_boost_round=50, early_stopping_rounds=10, metrics="rmse", as_pandas=True, seed=123)
-
关闭 Data Wrangler
完成使用 Data Wrangler 后,我们建议您关闭运行的实例,以免产生额外费用。要了解如何关闭 Data Wrangler 应用程序和关联的实例,请参阅 关闭 Data Wrangler。