本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
导入
您可以使用 Amazon SageMaker Data Wrangler 从以下数据源导入数据:亚马逊简单存储服务 (Amazon S3)、亚马逊雅典娜、亚马逊 Redshift 和 Snowflake。您导入的数据集最多可以包含 1000 列。
主题
使用某些数据来源可以添加多个数据连接:
-
可以连接到多个 Amazon Redshift 集群。每个集群会变成一个数据来源。
-
您可以查询账户中的任何 Athena 数据库,从该数据库导入数据。
从数据来源导入数据集时,该数据集将显示在数据流中。Data Wrangler 会自动推断数据集内每个列的数据类型。要修改这些类型,请选择数据类型步骤,然后选择编辑数据类型。
当您从 Athena 或 Amazon Redshift 导入数据时,导入的数据将自动存储在您使用 Studio Classic 的地区的 SageMaker 默认 AI S3 存储桶中。 Amazon 此外,Athena 会将您在 Data Wrangler 中预览的数据存储在此存储桶中。要了解更多信息,请参阅导入的数据存储。
重要
默认 Amazon S3 存储桶可能未设置最严格的安全设置,例如存储桶策略和服务器端加密 (SSE)。我们强烈建议您添加存储桶策略,来限制对导入到 Data Wrangler 的数据集的访问。
重要
此外,如果您将托管策略用于 SageMaker AI,我们强烈建议您将其范围缩小到允许您执行用例的最严格的策略。有关更多信息,请参阅 授予 IAM 角色使用 Data Wrangler 的权限。
除 Amazon Simple Storage Service (Amazon S3) 以外的所有数据来源,都要求您指定 SQL 查询来导入数据。对于每个查询,必须指定以下内容:
-
数据目录
-
数据库
-
表
可以在下拉菜单或查询中指定数据库或数据目录的名称。下面是示例查询:
-
select * from– 查询不使用用户界面 (UI) 下拉菜单中指定的任何项来运行。它在example-data-catalog-name.example-database-name.example-table-nameexample-data-catalog-name内部的example-database-name中查询example-table-name。 -
select * from– 查询使用您在数据目录下拉菜单中指定的数据目录来运行。它会在您指定的数据目录内的example-database-name.example-table-nameexample-database-name中查询example-table-name。 -
select * from– 查询要求您为数据目录和数据库名称下拉菜单选择字段。它会在您指定的数据库和数据目录内的数据目录中查询example-table-nameexample-table-name。
Data Wrangler 与数据来源之间的关联是连接。可以使用该连接从您的数据来源导入数据。
有以下几种类型的连接:
-
直接
-
编目
Data Wrangler 始终可以通过直接连接访问最新的数据。如果数据来源中的数据已更新,则可以使用连接导入数据。例如,如果有人将文件添加到您的某个 Amazon S3 存储桶,您可以导入该文件。
编目连接是数据传输的结果。编目连接中的数据不一定包含最新数据。例如,您可以设置 Salesforce 与 Amazon S3 之间的数据传输。如果 Salesforce 数据发生更新,则必须重新传输数据。您可以自动执行数据传输过程。有关数据传输的更多信息,请参阅 从软件即服务 (SaaS) 平台导入数据。
从 Amazon S3 导入数据
可以使用 Amazon Simple Storage Service (Amazon S3) 随时从任何位置在 Web 上存储和检索任何数量的数据。您可以使用简单直观的 Amazon Web Services 管理控制台网页界面和 Amazon S3 API 来完成这些任务。如果您已将数据集存储在本地,我们建议您将数据集添加到 S3 存储桶中,以便导入到 Data Wrangler 中。要了解具体方法,请参阅《Amazon Simple Storage Service 用户指南》中的将对象上传到存储桶。
Data Wrangler 使用 S3 Select
重要
如果您计划导出数据流并启动 Data Wrangler 作业、将数据提取到 AI feature store 或创建 A SageMaker I 管道,请注意这些集成要求 Amazon S3 的输入数据位于同一区域。 SageMaker Amazon
重要
如果正在导入 CSV 文件,请确保该文件满足以下要求:
-
数据集内的记录不能超过一行。
-
反斜杠
\是唯一有效的转义字符。 -
您的数据集必须使用以下分隔符之一:
-
逗号 –
, -
冒号 –
: -
分号 –
; -
竖线 –
| -
Tab 键 –
[TAB]
-
为了节省空间,您可以导入压缩的 CSV 文件。
使用 Data Wrangler,您能够导入整个数据集或对其中的一部分进行采样。对于 Amazon S3,它提供了以下采样选项:
-
无 – 导入整个数据集。
-
前 K 行 – 对数据集的前 K 行进行采样,其中 K 是您指定的整数。
-
随机化 – 随机提取指定大小的样本。
-
分层 – 随机提取分层样本。分层样本保持列中的值比例。
导入数据后,您还可以使用采样转换器,从整个数据集内提取一个或多个样本。有关采样转换器的更多信息,请参阅 采样。
您可以使用以下资源标识符之一来导入数据:
-
使用 Amazon S3 存储桶或 Amazon S3 接入点的 Amazon S3 URI
-
Amazon S3 接入点别名
-
使用 Amazon S3 接入点或 Amazon S3 存储桶的 Amazon 资源名称 (ARN)
Amazon S3 接入点是附加到存储桶的命名网络端点。每个接入点都有您可配置的不同的权限和网络控制。有关接入点的更多信息,请参阅使用 Amazon S3 接入点管理数据访问。
重要
如果您使用亚马逊资源名称 (ARN) 来导入数据,则该名称必须与您用于访问 Amazon SageMaker Studio Classic 的资源相同 Amazon Web Services 区域 。
可以将单个文件或多个文件作为数据集导入。如果您有分为多个单独文件的数据集,可以使用多文件导入操作。该操作从 Amazon S3 目录中获取所有文件,并将这些文件作为单个数据集导入。有关您可导入的文件类型以及如何导入这些文件的信息,请参阅以下各个部分。
您也可以使用参数来导入与模式匹配的文件子集。使用参数有助于您更有选择性地选择要导入的文件。要开始使用参数,请编辑数据来源,并将其应用于您用于导入数据的路径。有关更多信息,请参阅 针对不同数据集重用数据流。
从 Athena 导入数据
使用 Amazon Athena 将您的数据从 Amazon Simple Storage Service (Amazon S3) 导入到 Data Wrangler。在 Athena 中,可以编写标准的 SQL 查询,来选择要从 Amazon S3 导入的数据。有关更多信息,请参阅什么是 Amazon Athena?
您可以使用 Amazon Web Services 管理控制台 来设置 Amazon Athena。开始运行查询之前,必须在 Athena 中至少创建一个数据库。有关开始使用 Athena 的更多信息,请参阅入门。
Athena 直接与 Data Wrangler 集成。无需离开 Data Wrangler UI,即可编写 Athena 查询。
除了在 Data Wrangler 中编写简单的 Athena 查询之外,您还可以使用:
在 Data Wrangler 中查询 Athena
注意
Data Wrangler 不支持联合查询。
如果您 Amazon Lake Formation 与 Athena 一起使用,请确保您的 Lake Formation IAM 权限不会覆盖数据库的 IAM 权限。sagemaker_data_wrangler
使用 Data Wrangler,您能够导入整个数据集或对其中的一部分进行采样。对于 Athena,提供了以下采样选项:
-
无 – 导入整个数据集。
-
前 K 行 – 对数据集的前 K 行进行采样,其中 K 是您指定的整数。
-
随机化 – 随机提取指定大小的样本。
-
分层 – 随机提取分层样本。分层样本保持列中的值比例。
以下过程介绍如何将 Athena 中的数据集导入到 Data Wrangler。
将数据集从 Athena 导入到 Data Wrangler
-
选择 Studio。
-
选择启动应用程序。
-
从下拉列表中选择 Studio。
-
选择主页图标。
-
选择数据。
-
选择 Data Wrangler。
-
选择导入数据。
-
在可用下,选择 Amazon Athena。
-
对于数据目录,选择一个数据目录。
-
使用数据库下拉列表选择要查询的数据库。选择数据库后,您可以使用详细信息下列出的表预览数据库中的所有表。
-
(可选)选择高级配置。
-
选择一个工作组。
-
如果您的工作组尚未强制使用 Amazon S3 输出位置,或者您没有使用工作组,请为查询结果的 Amazon S3 位置指定一个值。
-
(可选)对于数据留存期,选中该复选框以设置数据留存期,并指定在删除数据之前存储数据的天数。
-
(可选)默认情况下,Data Wrangler 会保存连接。可以选择取消选中该复选框,此时不保存连接。
-
-
对于采样,选择一种采样方法。选择无可关闭采样。
-
在查询编辑器中输入您的查询,然后使用运行按钮运行查询。查询成功后,可以在编辑器下预览您的结果。
注意
Salesforce 数据使用
timestamptz类型。如果您要查询从 Salesforce 导入到 Athena 的时间戳列,请将该列中的数据转换为timestamp类型。以下查询将时间戳列转换为正确的类型。# cast column timestamptz_col as timestamp type, and name it as timestamp_col select cast(timestamptz_col as timestamp) as timestamp_col from table -
要导入查询结果,请选择导入。
完成上述过程后,您查询并导入的数据集将会显示在 Data Wrangler 流中。
默认情况下,Data Wrangler 会将连接设置保存为新连接。导入数据时,已指定的查询将显示为新的连接。保存的连接存储有关正在使用的 Athena 工作组和 Amazon S3 存储桶的信息。当您再次连接到数据来源时,可以选择已保存的连接。
管理查询结果
Data Wrangler 支持使用 Athena 工作组来管理账户 Amazon 中的查询结果。可以为每个工作组指定 Amazon S3 输出位置。您还可以指定查询输出是否可以保存到不同的 Amazon S3 位置。有关更多信息,请参阅使用工作组控制查询访问和成本。
您的工作组可能已配置为强制使用 Amazon S3 查询输出位置。您无法更改这些工作组的查询结果输出位置。
如果您不使用工作组或为查询指定输出位置,Data Wrangler 会使用您的 Studio Classic 实例所在 Amazon 区域的默认 Amazon S3 存储桶来存储 Athena 查询结果。它会在此数据库中创建临时表,以将查询输出移至此 Amazon S3 存储桶。它会在导入数据后删除这些表;不过数据库 sagemaker_data_wrangler 仍然存在。要了解更多信息,请参阅导入的数据存储。
要使用 Athena 工作组,请设置用于授予工作组访问权限的 IAM 策略。如果您使用 SageMaker AI-Execution-Role,我们建议将策略添加到角色中。有关用于工作组的 IAM 策略的更多信息,请参阅用于访问工作组的 IAM 策略。有关工作组策略示例,请参阅工作组示例策略。
设置数据留存期
Data Wrangler 会自动为查询结果设置数据留存期。留存期过后,结果将被删除。例如,默认留存期为五天。查询结果将在五天后被删除。此配置可以协助您清理不再使用的数据。清理您的数据可以防止未授权用户获得访问权限。该操作还有助于控制在 Amazon S3 上存储数据的成本。
如果您未设置留存期,Amazon S3 生命周期配置将决定对象的存储期限。您为生命周期配置指定的数据留存策略会删除任何超过指定生命周期配置的查询结果。有关更多信息,请参阅设置存储桶的生命周期配置。
Data Wrangler 使用 Amazon S3 生命周期配置来管理数据留存和过期。您必须授予您的 Amazon SageMaker Studio Classic IAM 执行角色权限才能管理存储桶生命周期配置。可以通过以下步骤授予权限。
要授予管理生命周期配置的权限,请执行以下操作。
-
登录 Amazon Web Services 管理控制台 并打开 IAM 控制台,网址为https://console.aws.amazon.com/iam/
。 -
选择角色。
-
在搜索栏中,指定 Amazon SageMaker Studio Classic 正在使用的亚马逊 A SageMaker I 执行角色。
-
选择角色 。
-
选择添加权限。
-
选择创建内联策略。
-
对于服务,指定 S3 并选择该项。
-
在 “阅读” 部分下,选择GetLifecycleConfiguration。
-
在 “写入” 部分下,选择PutLifecycleConfiguration。
-
对于资源,选择特定。
-
对于操作,选择权限管理旁边的箭头图标。
-
选择 PutResourcePolicy。
-
对于资源,选择特定。
-
选中此账户中的任何资源旁边的复选框。
-
选择查看策略。
-
对于名称,指定一个名称。
-
选择创建策略。
从 Amazon Redshift 导入数据
Amazon Redshift 是云中一种完全托管的 PB 级数据仓库服务。创建数据仓库的第一步是启动一组节点(称为 Amazon Redshift 集群)。预置集群后,您可以上传数据集,然后执行数据分析查询。
可以在 Data Wrangler 中连接并查询一个或多个 Amazon Redshift 集群。要使用此导入选项,必须在 Amazon Redshift 中至少创建一个集群。要了解操作方法,请参阅 Amazon Redshift 入门。
可以将 Amazon Redshift 查询结果输出到以下位置之一:
-
Amazon S3 存储桶
-
指定的 Amazon S3 输出位置
可以导入整个数据集,或者对其中一部分进行采样。对于 Amazon Redshift,它提供了以下采样选项:
-
无 – 导入整个数据集。
-
前 K 行 – 对数据集的前 K 行进行采样,其中 K 是您指定的整数。
-
随机化 – 随机提取指定大小的样本。
-
分层 – 随机提取分层样本。分层样本保持列中的值比例。
默认 Amazon S3 存储桶位于您的 Studio Classift 实例所在的同一 Amazon 区域,用于存储 Amazon Redshift 查询结果。有关更多信息,请参阅 导入的数据存储。
对于默认 Amazon S3 存储桶或您指定的存储桶,都可以使用以下加密选项:
-
使用 Amazon S3 托管密钥进行默认 Amazon 服务端加密 () SSE-S3
-
您指定的 Amazon Key Management Service (Amazon KMS) 密钥
Amazon KMS 密钥是您创建和管理的加密密钥。有关 KMS 密钥的更多信息,请参阅 Amazon Key Management Service。
您可以使用账户的 Amazon KMS 密钥 ARN 或 ARN 来指定密钥。 Amazon
如果您使用 IAM 托管式策略 AmazonSageMakerFullAccess 授予角色在 Studio Classic 中使用 Data Wrangler 的权限,则数据库用户名称的前缀必须是 sagemaker_access。
通过以下过程,了解如何添加新集群。
注意
Data Wrangler 通过临时凭证来使用 Amazon Redshift Data API。要了解有关此 API 的更多信息,请参阅《Amazon Redshift 管理指南》中的使用 Amazon Redshift Data API。
连接到 Amazon Redshift 集群
-
选择 Studio。
-
选择启动应用程序。
-
从下拉列表中选择 Studio。
-
选择主页图标。
-
选择数据。
-
选择 Data Wrangler。
-
选择导入数据。
-
在可用下,选择 Amazon Athena。
-
选择 Amazon Redshift。
-
为类型选择临时凭证 (IAM)。
-
输入连接名称。这是 Data Wrangler 用来标识该连接的名称。
-
输入集群标识符以指定要连接的集群。注意:仅输入集群标识符,而不要输入 Amazon Redshift 集群的完整端点。
-
输入要连接到的数据库的数据库名称。
-
输入数据库用户以标识要用于连接数据库的用户。
-
对于 UNLOAD IAM 角色,输入 Amazon Redshift 集群在向 Amazon S3 移动和写入数据时应代入的角色的 IAM 角色 ARN。有关此角色的更多信息,请参阅亚马逊 Redshift 管理指南中的授权亚马逊 Redshift 代表您访问 Amazon 其他服务。
-
选择连接。
-
(可选)对于 Amazon S3 输出位置,指定用于存储查询结果的 S3 URI。
-
(可选)对于 KMS 密钥 ID,指定 Amazon KMS 密钥的 ARN 或别名。下图显示了在 Amazon Web Services 管理控制台中可以找到任一密钥的位置。
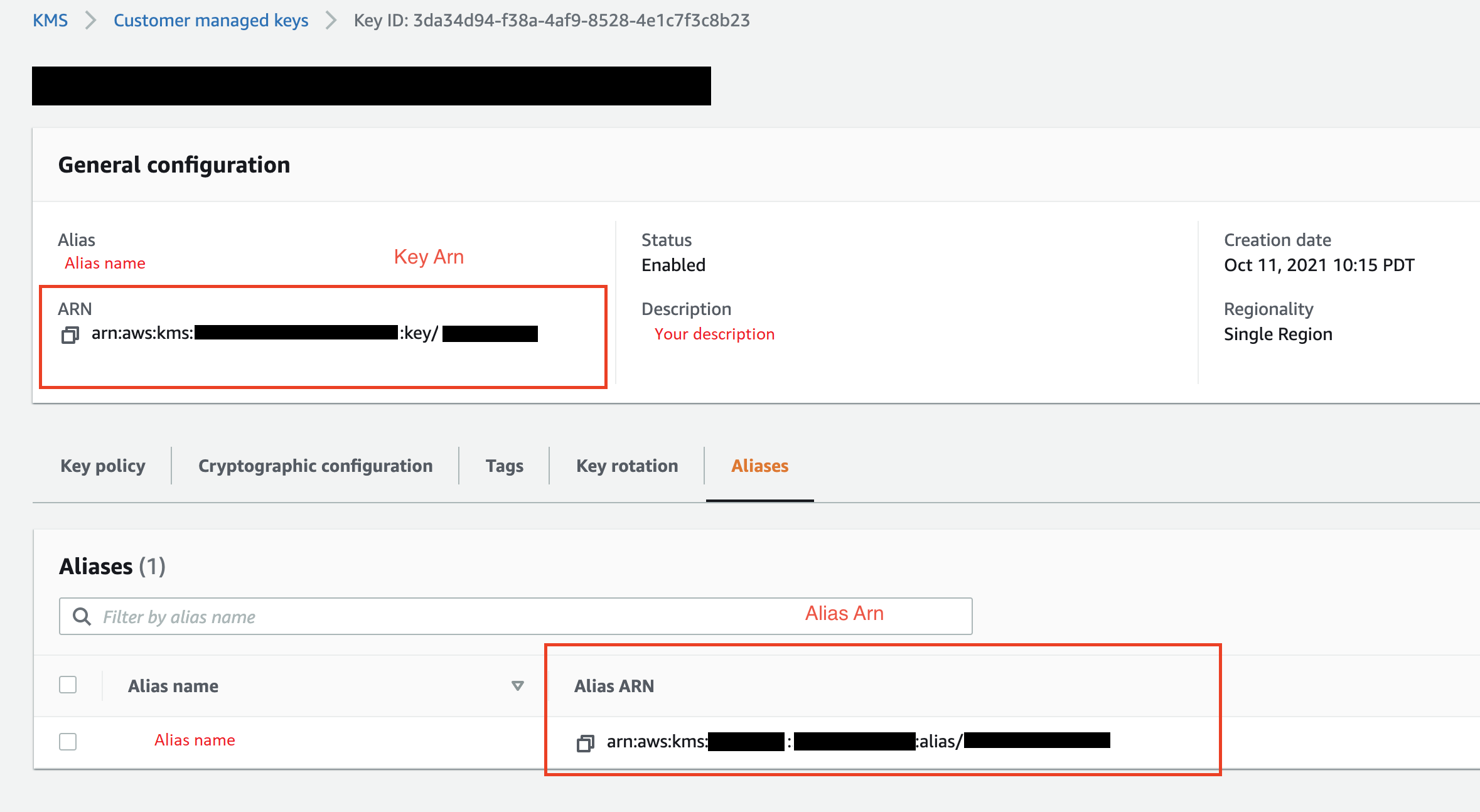
下图显示了前述过程中的所有字段。
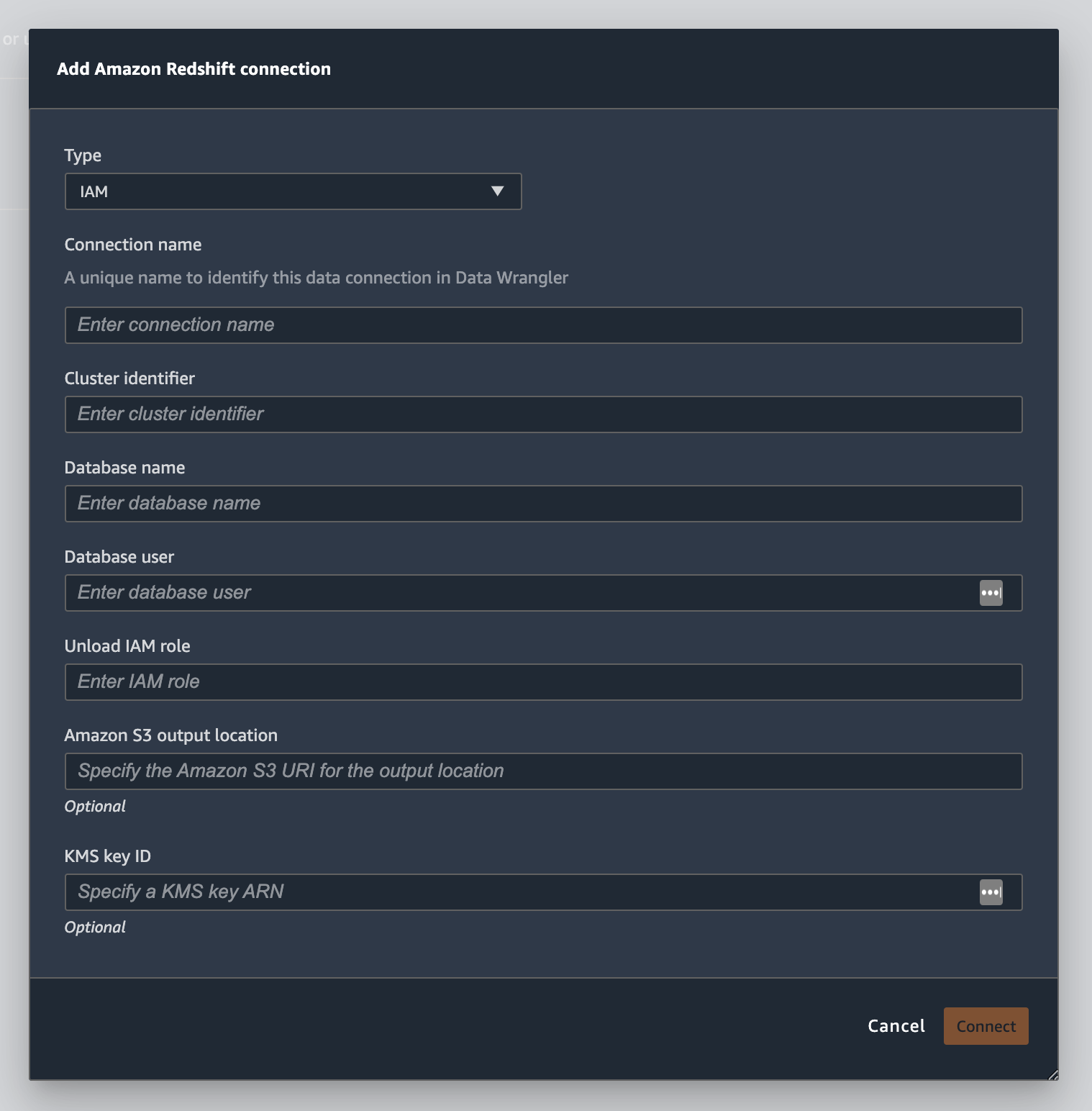
成功建立连接后,它将作为数据来源显示在数据导入下。选择此数据来源可以查询您的数据库并导入数据。
从 Amazon Redshift 查询和导入数据
-
从数据来源中选择要查询的连接。
-
选择架构。要了解有关 Amazon Redshift 架构的更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的架构。
-
(可选)在高级配置下,指定要使用的采样方法。
-
在查询编辑器中输入您的查询,然后选择运行以运行查询。查询成功后,可以在编辑器下预览您的结果。
-
选择导入数据集以导入已查询的数据集。
-
输入数据集名称。如果您添加的数据集名称中包含空格,则在导入您的数据集时,这些空格将替换为下划线。
-
选择添加。
要编辑数据集,请执行以下操作。
-
导航到您的 Data Wrangler 流。
-
选择来源 – 采样旁边的 + 号。
-
更改要导入的数据。
-
选择应用
从 Amazon EMR 导入数据
您可以使用 Amazon EMR 作为您的 Amazon Data Wrangler 流程 SageMaker 的数据源。Amazon EMR 是一个托管式集群平台,可用来处理和分析大量数据。有关 Amazon EMR 的更多信息,请参阅什么是 Amazon EMR?。要从 EMR 导入数据集,您需要连接到该数据集并进行查询。
重要
必须满足以下先决条件,才能连接 Amazon EMR 集群:
先决条件
-
网络配置
-
您在该地区有一个亚马逊 VPC,用于启动 Amazon SageMaker Studio Classic 和亚马逊 EMR。
-
亚马逊 EMR 和 Amazon SageMaker Studio Classic 都必须在私有子网中启动。它们可位于相同的子网中,也可以位于不同的子网中。
-
亚马逊 SageMaker Studio Classic 必须处于 VPC-only 模式下。
有关创建 VPC 的更多信息,请参阅创建 VPC。
有关创建 VPC 的更多信息,请参阅将 VPC 中的 SageMaker Studio 经典笔记本电脑连接到外部资源。
-
您正在运行的 Amazon EMR 集群必须位于相同的 Amazon VPC 中。
-
亚马逊 EMR 集群和亚马逊 VPC 必须位于同一个 Amazon 账户中。
-
您的 Amazon EMR 集群正在运行 Hive 或 Presto。
-
Hive 集群必须允许来自 Studio Classic 安全组 10000 端口的入站流量。
-
Presto 集群必须允许来自 Studio Classic 安全组 8889 端口的入站流量。
注意
使用 IAM 角色的 Amazon EMR 集群的端口号有所不同。有关更多信息,请导航到先决条件部分的结尾。
-
-
-
SageMaker 经典工作室
-
亚马逊 SageMaker Studio Classic 必须运行 Jupyter Lab 版本 3。有关更新 Jupyter Lab 版本的信息,请参阅 从控制台查看和更新应用程序的 JupyterLab 版本。
-
Amazon SageMaker Studio Classic 有一个控制用户访问权限的 IAM 角色。你用于运行 Amazon SageMaker Studio Classic 的默认 IAM 角色没有允许你访问亚马逊 EMR 集群的策略。您必须附加向 IAM 角色授予权限的策略。有关更多信息,请参阅 配置 Amazon EMR 集群列表。
-
IAM 角色还必须附加有以下策略:
secretsmanager:PutResourcePolicy。 -
如果您使用的是已经创建的 Studio Classic 域名,请确保该
AppNetworkAccessType域名 VPC-only 处于模式中。有关将域更新为使用 VPC-only 模式的信息,请参阅关闭并更新 Amazon SageMaker Studio 经典版。
-
-
Amazon EMR 集群
-
您的集群上必须已安装 Hive 或 Presto。
-
Amazon EMR 版本必须为 5.5.0 或更高版本。
注意
Amazon EMR 支持自动终止。自动终止功能会阻止空闲集群运行,可防止产生成本。下面是支持自动终止功能的版本:
-
对于 6.x 发行版,版本 6.1.0 或更高版本。
-
对于 5.x 发行版,版本 5.30.0 或更高版本。
-
-
-
使用 IAM 运行时角色的 Amazon EMR 集群
-
使用以下页面可以为 Amazon EMR 集群设置 IAM 运行时角色。在使用运行时角色时,必须启用传输中加密功能:
-
您必须将 Lake Formation 用作监管数据库中数据的工具。您还必须使用外部数据筛选功能进行访问控制。
-
有关 Lake Formation 的更多信息,请参阅什么是 Amazon Lake Formation?
-
有关将 Lake Formation 集成到 Amazon EMR 中的更多信息,请参阅将第三方服务与 Lake Formation 集成。
-
-
集群的版本必须是 6.9.0 或更高版本。
-
访问 Amazon Secrets Manager。有关 Secrets Manager 的更多信息,请参阅什么是 Amazon Secrets Manager?
-
Hive 集群必须允许来自 Studio Classic 安全组 10000 端口的入站流量。
-
Amazon VPC 是一种在逻辑上与 Amazon 云上其他网络隔离的虚拟网络。Amazon SageMaker Studio Classic 和您的亚马逊 EMR 集群仅存在于亚马逊 VPC 中。
使用以下步骤在亚马逊 VPC 中启动 Amazon SageMaker Studio Classic。
要在 VPC 中启动 Studio Classic,请执行以下操作。
-
导航到 SageMaker AI 控制台,网址为https://console.aws.amazon.com/sagemaker/
。 -
选择启动 SageMaker 工作室经典版。
-
选择标准设置。
-
在默认执行角色中,选择要设置 Studio Classic 的 IAM 角色。
-
选择您启动 Amazon EMR 集群的 VPC。
-
对于子网,选择私有子网。
-
对于安全组,指定用于在您的 VPC 之间进行控制的安全组。
-
选择仅 VPC。
-
(可选) Amazon 使用默认加密密钥。您还可以指定另一个 Amazon Key Management Service 密钥来加密数据。
-
选择下一步。
-
在 Studio 设置下,选择最适合您的配置。
-
选择 “下一步” 可跳过 “ SageMaker 画布” 设置。
-
选择下一步可跳过 RStudio 设置。
如果您还没有准备好 Amazon EMR 集群,可以使用以下步骤创建一个。有关 Amazon EMR 的更多信息,请参阅什么是 Amazon EMR?
要创建集群,请执行以下操作。
-
导航到 Amazon Web Services 管理控制台。
-
在搜索栏中指定
Amazon EMR。 -
选择创建集群。
-
对于集群名称,指定您的集群名称。
-
对于版本,选择集群的发布版本。
注意
Amazon EMR 支持以下版本的自动终止功能:
-
对于 6.x 发行版,版本 6.1.0 或更高版本
-
对于 5.x 发行版,版本 5.30.0 或更高版本
自动终止功能会阻止空闲集群运行,可防止产生成本。
-
-
(可选)对于应用程序,选择 Presto。
-
选择您在集群上运行的应用程序。
-
在联网下,对于硬件配置,指定硬件配置设置。
重要
对于网络,请选择运行 Amazon SageMaker Studio Classic 的 VPC 并选择私有子网。
-
在安全和访问权限下,指定安全设置。
-
选择创建。
有关创建 Amazon EMR 集群的教程,请参阅 Amazon EMR 入门。有关配置集群的最佳实践的信息,请参阅注意事项和最佳实践。
注意
出于安全最佳实践,Data Wrangler 只能连接到私有子网上的 VPC。除非您用 Amazon Systems Manager 于 Amazon EMR 实例,否则您无法连接到主节点。有关更多信息,请参阅使用 Amazon Systems Manager保护对 EMR 集群的访问
目前,您可以使用以下方法来访问 Amazon EMR 集群:
-
不使用身份验证
-
轻型目录访问协议 (LDAP)
-
IAM(运行时角色)
如果不使用身份验证或使用 LDAP,可能会要求您创建多个集群和 Amazon EC2 实例配置文件。如果您是管理员,则可能需要为用户组提供不同级别的数据访问权限。这些方法可能会导致管理开销,从而使管理您的用户变得更加困难。
我们建议使用一个 IAM 运行时角色向多个用户授予连接到同一 Amazon EMR 集群的能力。运行时角色是一个 IAM 角色,您可以将该角色分配给连接到 Amazon EMR 集群的用户。可以将运行时 IAM 角色配置为具有特定于每个用户组的权限。
使用以下部分创建已激活 LDAP 的 Presto 或 Hive Amazon EMR 集群。
按照以下部分,对您已创建的 Amazon EMR 集群使用 LDAP 身份验证。
可以通过以下步骤,从集群导入数据。
要从集群导入数据,请执行以下操作。
-
打开 Data Wrangler 流。
-
选择创建连接。
-
选择 Amazon EMR。
-
请执行以下操作之一。
-
(可选)对于密钥 ARN,指定集群内数据库的 Amazon 资源编号 (ARN)。密钥可提供额外的安全措施。有关密钥的更多信息,请参阅什么是 Amazon Secrets Manager? 有关为集群创建密钥的信息,请参阅 创建一个 Amazon Secrets Manager 你的集群的秘密。
重要
如果使用 IAM 运行时角色进行身份验证,则必须指定密钥。
-
从下拉列表中,选择一个集群。
-
-
选择下一步。
-
在 “为
example-cluster-name集群选择终端节点” 中,选择查询引擎。 -
(可选)选择保存连接。
-
选择下一步,选择登录,然后选择以下项之一:
-
不使用身份验证
-
LDAP
-
IAM
-
-
在 “登录到
example-cluster-name集群” 中,指定群集的用户名和密码。 -
选择连接。
-
在查询编辑器中,指定 SQL 查询。
-
选择运行。
-
选择导入。
创建一个 Amazon Secrets Manager 你的集群的秘密
如果使用 IAM 运行时角色访问您的 Amazon EMR 集群,则必须将用于访问 Amazon EMR 的凭证存储为 Secrets Manager 密钥。您将用于访问集群的所有凭证都存储在密钥中。
必须在密钥中存储以下信息:
-
JDBC 端点 –
jdbc:hive2:// -
DNS 名称 – Amazon EMR 集群的 DNS 名称。这要么是主节点的端点,要么是主机名。
-
端口 –
8446
您还可以在密钥中存储以下附加信息:
-
IAM 角色 – 用于访问集群的 IAM 角色。默认情况下,Data Wrangler 使用你的 SageMaker AI 执行角色。
-
信任库路径 – 默认情况下,Data Wrangler 会为您创建信任库路径。您还可以使用自己的信任库路径。有关信任库路径的更多信息,请参阅 HiveServer2 中的In-transit 加密。
-
信任库密码 – 默认情况下,Data Wrangler 会为您创建信任库密码。您还可以使用自己的信任库路径。有关信任库路径的更多信息,请参阅 HiveServer2 中的In-transit 加密。
通过以下步骤将凭证存储在 Secrets Manager 密钥中。
要将您的凭证存储为密钥,请执行以下操作。
-
导航到 Amazon Web Services 管理控制台。
-
在搜索栏中,指定 Secrets Manager。
-
选择 Amazon Secrets Manager。
-
选择存储新密钥。
-
对于密钥类型,请选择其他密钥类型。
-
在 “Key/value配对” 下,选择 “纯文本”。
-
对于运行 Hive 的集群,可以使用以下模板进行 IAM 身份验证。
{"jdbcURL": "" "iam_auth": {"endpoint": "jdbc:hive2://", #required "dns": "ip-xx-x-xxx-xxx.ec2.internal", #required "port": "10000", #required "cluster_id": "j-xxxxxxxxx", #required "iam_role": "arn:aws:iam::xxxxxxxx:role/xxxxxxxxxxxx", #optional "truststore_path": "/etc/alternatives/jre/lib/security/cacerts", #optional "truststore_password": "changeit" #optional }}注意
导入数据后,可以对数据进行转换。然后,将转换后的数据导出到特定位置。如果您使用 Jupyter 笔记本将转换后的数据导出到 Amazon S3,则必须使用上述示例中指定的信任库路径。
Secrets Manager 密钥将 Amazon EMR 集群的 JDBC URL 存储为密钥。相比直接输入凭证,使用密钥更加安全。
通过以下步骤,将 JDBC URL 存储为密钥。
要将 JDBC URL 存储为密钥,请执行以下操作。
-
导航到 Amazon Web Services 管理控制台。
-
在搜索栏中,指定 Secrets Manager。
-
选择 Amazon Secrets Manager。
-
选择存储新密钥。
-
对于密钥类型,请选择其他密钥类型。
-
对于Key/value 配对,请指定
jdbcURL为密钥并指定有效的 JDBC URL 作为值。有效 JDBC URL 的格式取决于您是否使用身份验证,以及是使用 Hive 还是 Presto 作为查询引擎。下面的列表显示了适用于可能的不同配置的有效 JBDC URL 格式。
-
Hive,不进行身份验证 –
jdbc:hive2://emr-cluster-master-public-dns:10000/; -
Hive,使用 LDAP 身份验证 –
jdbc:hive2://emr-cluster-master-public-dns-name:10000/;AuthMech=3;UID=david;PWD=welcome123; -
对于已启用 SSL 的 Hive,JDBC URL 格式取决于您是否使用 Java 密钥库文件进行 TLS 配置。Java 密钥库文件有助于验证 Amazon EMR 集群的主节点身份。要使用 Java 密钥库文件,请在 EMR 集群上生成该文件并上传到 Data Wrangler。要生成文件,请在 Amazon EMR 集群
keytool -genkey -alias hive -keyalg RSA -keysize 1024 -keystore hive.jks上使用以下命令。有关在 Amazon EMR 集群上运行命令的信息,请参阅使用 Amazon Systems Manager保护对 EMR 集群的访问。要上传文件,请选择 Data Wrangler UI 左侧导航栏上的向上箭头。 下面是已启用 SSL 的 Hive 的有效 JDBC URL 格式:
-
没有 Java 密钥库文件 –
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;AllowSelfSignedCerts=1; -
带有 Java 密钥库文件 –
jdbc:hive2://emr-cluster-master-public-dns:10000/;AuthMech=3;UID=user-name;PWD=password;SSL=1;SSLKeyStore=/home/sagemaker-user/data/Java-keystore-file-name;SSLKeyStorePwd=Java-keystore-file-passsword;
-
-
Presto,没有身份验证 — jdbc: presto: //: 8889/;
emr-cluster-master-public-dns -
对于已启用 LDAP 身份验证和 SSL 的 Presto,JDBC URL 格式取决于您是否使用 Java 密钥库文件进行 TLS 配置。Java 密钥库文件有助于验证 Amazon EMR 集群的主节点身份。要使用 Java 密钥库文件,请在 EMR 集群上生成该文件并上传到 Data Wrangler。要上传文件,请选择 Data Wrangler UI 左侧导航栏上的向上箭头。有关为 Presto 创建 Java 密钥库文件的信息,请参阅适用于 TLS 的 Java 密钥库文件
。有关在 Amazon EMR 集群上运行命令的信息,请参阅使用 Amazon Systems Manager保护对 EMR 集群的访问 。 -
没有 Java 密钥库文件 –
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;UID=user-name;PWD=password;AllowSelfSignedServerCert=1;AllowHostNameCNMismatch=1; -
带有 Java 密钥库文件 –
jdbc:presto://emr-cluster-master-public-dns:8889/;SSL=1;AuthenticationType=LDAP Authentication;SSLTrustStorePath=/home/sagemaker-user/data/Java-keystore-file-name;SSLTrustStorePwd=Java-keystore-file-passsword;UID=user-name;PWD=password;
-
-
在从 Amazon EMR 集群导入数据的整个过程中,可能会遇到问题。有关排查故障的信息,请参阅 排除 Amazon EMR 中的问题。
从 Databricks (JDBC) 导入数据
您可以使用 Databricks 作为 Amazon Data Wrangler 流程 SageMaker 的数据源。要从 Databricks 导入数据集,请使用 JDBC(Java 数据库连接)导入功能访问 Databricks 数据库。访问数据库后,指定 SQL 查询,以获取数据并导入。
我们假设您有一个正在运行的 Databricks 集群,并且您已为该集群配置了 JDBC 驱动程序。有关更多信息,请参阅以下 Databricks 文档页面:
Data Wrangler 会将你的 JDBC 网址存储在中。 Amazon Secrets Manager您必须授予您的 Amazon SageMaker Studio Classic IAM 执行角色权限才能使用 Secrets Manager。可以通过以下步骤授予权限。
要向 Secrets Manager 授予权限,请执行以下操作。
-
登录 Amazon Web Services 管理控制台 并打开 IAM 控制台,网址为https://console.aws.amazon.com/iam/
。 -
选择角色。
-
在搜索栏中,指定 Amazon SageMaker Studio Classic 正在使用的亚马逊 A SageMaker I 执行角色。
-
选择角色 。
-
选择添加权限。
-
选择创建内联策略。
-
对于服务,指定 Secrets Manager 并选择该项。
-
对于操作,选择权限管理旁边的箭头图标。
-
选择 PutResourcePolicy。
-
对于资源,选择特定。
-
选中此账户中的任何资源旁边的复选框。
-
选择查看策略。
-
对于名称,指定一个名称。
-
选择创建策略。
可以使用分区更快地导入您的数据。利用分区,Data Wrangler 能够并行处理数据。默认情况下,Data Wrangler 使用 2 个分区。对于大多数使用案例而言,2 个分区能够为您提供近乎最佳的数据处理速度。
如果选择指定 2 个以上的分区,还可以指定一列来对数据进行分区。列中值的类型必须是数字或日期。
我们建议只有在您了解数据的结构及其处理方式的情况下,才使用分区。
可以导入整个数据集,或者对其中一部分进行采样。对于 Databricks 数据库,提供了以下采样选项:
-
无 – 导入整个数据集。
-
前 K 行 – 对数据集的前 K 行进行采样,其中 K 是您指定的整数。
-
随机化 – 随机提取指定大小的样本。
-
分层 – 随机提取分层样本。分层样本保持列中的值比例。
可以通过以下步骤,从 Databricks 数据库导入数据。
要从 Databricks 导入数据,请执行以下操作。
-
选择 Studio。
-
选择启动应用程序。
-
从下拉列表中选择 Studio。
-
从 Data Wrangler 流的导入数据选项卡中,选择 Databricks。
-
指定以下字段:
-
数据集名称 – 要在 Data Wrangler 流中用于数据集的名称。
-
驱动程序 – com.simba.spark.jdbc.Driver。
-
JDBC URL – Databricks 数据库的 URL。不同 Databricks 实例的 URL 格式可能有所不同。有关查找 URL 以及在其中指定参数的信息,请参阅 JDBC 配置和连接参数
。以下是如何格式化网址的示例:jdbc: spark: //aws-sagemaker-datawrangler.cloud.databricks.com:; transportMode=http;ssl=1;httpPath=//0909-200301-cut318;=3;UID=;PWD=。443/default sql/protocolv1 o/3122619508517275 AuthMech tokenpersonal-access-token注意
可以指定包含 JDBC URL 的密钥 ARN,而不是指定 JDBC URL 本身。密钥必须包含以下格式的键/值对:
jdbcURL:。有关更多信息,请参阅什么是 Secrets Manager?JDBC-URL
-
-
指定 SQL SELECT 语句。
注意
Data Wrangler 不支持查询中的公用表表达式 (CTE) 或临时表。
-
对于采样,选择一种采样方法。
-
选择运行。
-
(可选)对于预览,选择齿轮以打开分区设置。
-
指定分区的数量。如果指定分区数,可以按列进行分区:
-
输入分区数 – 指定一个大于 2 的值。
-
(可选)按列分区 – 指定以下字段。只有在输入分区数中指定值后,才能按列进行分区。
-
选择列 – 选择要用于数据分区的列。列的数据类型必须为数字或日期。
-
上限 – 根据您指定的列中的值,上限是正在分区中使用的值。指定的值不会更改正在导入的数据。只会影响导入的速度。为了获得最佳性能,请指定接近列最大值的上限。
-
下限 – 根据您指定的列中的值,下限是正在分区中使用的值。指定的值不会更改正在导入的数据。只会影响导入的速度。为了获得最佳性能,请指定接近列最小值的下限。
-
-
-
-
选择导入。
从 Salesforce Data Cloud 导入数据
您可以使用 Salesforce 数据云作为 Amazon Data Wrangler 中的 SageMaker 数据源,为机器学习准备 Salesforce 数据云中的数据。
使用 Salesforce Data Cloud 作为 Data Wrangler 中的数据来源,您不需要编写一行代码,即可快速连接到 Salesforce 数据。在 Data Wrangler 中,可以将您的 Salesforce 数据与来自任何其他数据来源的数据联接起来。
连接到数据云后,可以执行以下操作:
-
使用内置的可视化效果可视化您的数据
-
了解数据并标识潜在的错误和极端值
-
使用 300 多种内置转换功能转换数据
-
导出转换后的数据
管理员设置
重要
在开始之前,请确保您的用户运行的是 Amazon SageMaker Studio Classic 版本 1.3.0 或更高版本。有关检查 Studio Classic 版本和更新的信息,请参阅 使用 Amazon Data Wrangler 准备机器学习 SageMaker 数据。
设置对 Salesforce Data Cloud 的访问权限时,您必须完成以下任务:
-
获取您的 Salesforce 域 URL。Salesforce 也将域 URL 称为您的组织的 URL。
-
从 Salesforce 获取 OAuth 凭证。
-
获取您的 Salesforce 域的授权 URL 和令牌 URL。
-
使用 OAuth 配置创建 Amazon Secrets Manager 密钥。
-
创建 Data Wrangler 用来从密钥中读取凭证的生命周期配置。
-
向 Data Wrangler 授予读取密钥的权限。
执行上述任务后,您的用户可以使用 OAuth 登录到 Salesforce Data Cloud。
注意
在完成所有设置后,您的用户可能会遇到问题。有关排查故障的信息,请参阅 Salesforce 故障排除。
可以通过以下步骤获取域 URL。
-
导航到 Salesforce 登录页面。
-
对于快速查找,指定我的域。
-
将当前我的域 URL 的值复制到文本文件中。
-
将
https://添加到 URL 的开头。
获取 Salesforce 域 URL 后,可以通过以下过程,从 Salesforce 获取登录凭证,并允许 Data Wrangler 访问您的 Salesforce 数据。
要从 Salesforce 获取登录凭证并提供对 Data Wrangler 的访问权限,请执行以下操作。
-
导航到您的 Salesforce 域 URL 并登录到您的账户。
-
选择齿轮图标。
-
在显示的搜索栏中,指定应用程序管理器。
-
选择新建连接的应用程序。
-
指定以下字段:
-
连接的应用程序名称 – 您可以指定任何名称,但我们建议选择包含 Data Wrangler 的名称。例如,可以指定 Salesforce Data Cloud Data Wrangler Integration。
-
API 名称 – 使用默认值。
-
联系人电子邮件 – 指定电子邮件地址。
-
在 API 标题(启用 OAuth 设置)下,选中复选框以激活 OAuth 设置。
-
对于回调网址,请指定亚马逊 SageMaker Studio 经典版网址。要获取 Studio Classic 的网址,请从访问 Amazon Web Services 管理控制台 并复制网址。
-
-
在选定 OAuth 作用域下,将以下内容从可用 OAuth 作用域移至选定 OAuth 作用域:
-
通过 API 管理用户数据 (
api) -
随时执行请求 (
refresh_token,offline_access) -
对 Salesforce Data Cloud 数据执行 ANSI SQL 查询 (
cdp_query_api) -
管理 Salesforce 客户数据平台配置文件数据 (
cdp_profile_api)
-
-
选择保存。保存更改后,Salesforce 会打开一个新页面。
-
选择继续。
-
导航到使用者密钥和私有密钥。
-
选择管理使用者详细信息。Salesforce 会将您重定向到一个新页面,其中您可能需要通过双因素身份验证。
-
重要
将使用者密钥和私有密钥复制到文本编辑器中。您需要该信息,才能将数据云连接到 Data Wrangler。
-
导航回管理连接的应用程序。
-
导航到连接的应用程序名称和您的应用程序名称。
-
选择管理。
-
选择编辑策略。
-
将 IP 放宽更改为放宽 IP 限制。
-
选择保存。
-
在提供对 Salesforce Data Cloud 的访问权限后,您需要为用户提供权限。可以通过以下步骤为他们提供权限。
要为您的用户提供权限,请执行以下操作。
-
导航到设置主页。
-
在左侧导航栏中,搜索用户,然后选择用户菜单项。
-
选择包含您的用户名的超链接。
-
导航到权限集分配。
-
选择编辑分配。
-
添加以下权限:
-
客户数据平台管理员
-
客户数据平台数据感知专家
-
-
选择保存。
获取 Salesforce 域名的信息后,必须获取正在创建的 Amazon Secrets Manager 密钥的授权网址和令牌网址。
可以通过以下步骤获取授权 URL 和令牌 URL。
获取授权 URL 和令牌 URL
-
导航到您的 Salesforce 域 URL。
-
使用以下方法之一获取 URL。如果您使用的是安装有
curl和jq的 Linux 发行版,我们建议您使用仅适用于 Linux 的方法。-
(仅限 Linux)在终端中指定以下命令。
curlsalesforce-domain-URL/.well-known/openid-configuration | \ jq '. | { authorization_url: .authorization_endpoint, token_url: .token_endpoint }' | \ jq '. += { identity_provider: "SALESFORCE", client_id: "example-client-id", client_secret: "example-client-secret" }' -
-
在您的浏览器中导航到
example-org-URL/.well-known/openid-configuration -
将
authorization_endpoint和token_endpoint复制到文本编辑器中。 -
创建以下 JSON 对象:
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" }
-
-
创建 OAuth 配置对象后,您可以创建一个存储该对象的 Amazon Secrets Manager 密钥。通过以下过程创建密钥。
要创建密钥,请执行以下操作。
-
选择存储密钥。
-
选择其他密钥类型。
-
在 “Key/value配对” 下选择 “纯文本”。
-
将空的 JSON 替换为以下配置设置。
{ "identity_provider": "SALESFORCE", "authorization_url": "example-authorization-endpoint", "token_url": "example-token-endpoint", "client_id": "example-consumer-key", "client_secret": "example-consumer-secret" } -
选择下一步。
-
对于密钥名称,指定密钥的名称。
-
在标签下,选择添加。
-
对于键,指定 sagemaker:partner。对于值,我们建议指定一个可能对您的使用案例有用的值。不过,可以指定任何值。
重要
您必须创建键。如果不创建键,则无法从 Salesforce 导入数据。
-
-
选择下一步。
-
选择存储。
-
选择您创建的密钥。
-
记录以下字段:
-
密钥的 Amazon 资源编号 (ARN)
-
密钥的名称
-
创建密钥后,必须为 Data Wrangler 添加读取密钥的权限。通过以下过程添加权限。
要为 Data Wrangler 添加读取权限,请执行以下操作。
-
选择域。
-
选择您用于访问 Data Wrangler 的域。
-
选择您的用户配置文件。
-
在详细信息下,找到执行角色。ARN 的格式如下:
arn:aws:iam::111122223333:role/。记下 A SageMaker I 执行角色。在 ARN 中,这是位于example-rolerole/后面的全部内容。 -
导航到 IAM 控制台
。 -
在搜索 IAM 搜索栏中,指定 SageMaker AI 执行角色的名称。
-
选择角色 。
-
选择添加权限。
-
选择创建内联策略。
-
选择 JSON 选项卡。
-
在编辑器中指定以下策略。
-
选择查看策略。
-
对于名称,指定一个名称。
-
选择创建策略。
在您授予 Data Wrangler 读取密钥的权限后,您必须将使用您的 Secrets Manager 密钥的生命周期配置添加到您的 Amazon SageMaker Studio Classic 用户个人资料中。
使用以下步骤创建生命周期配置并将其添加到 Studio Classic 配置文件。
要创建生命周期配置并将其添加到 Studio Classic 配置文件,请执行以下操作。
-
选择域。
-
选择您用于访问 Data Wrangler 的域。
-
选择您的用户配置文件。
-
如果您看到以下应用程序,请将其删除:
-
KernelGateway
-
JupyterKernel
注意
删除应用程序会更新 Studio Classic。更新操作可能需要一段时间才能生效。
-
-
在等待更新生效时,选择生命周期配置。
-
确保您所在的页面显示 Studio Classic Lifecycle 配置。
-
选择创建配置。
-
确保已选择 Jupyter 服务器应用程序。
-
选择下一步。
-
对于名称,指定配置的名称。
-
对于脚本,指定以下脚本:
#!/bin/bash set -eux cat > ~/.sfgenie_identity_provider_oauth_config <<EOL { "secret_arn": "secrets-arn-containing-salesforce-credentials" } EOL -
选择提交。
-
在左侧导航栏选择域。
-
选择您的域。
-
选择环境。
-
在个人 Studio Classic 应用程序的生命周期配置下,选择附加。
-
选择现有配置。
-
在 Studio Classic Lifecycle 配置下选择已创建的生命周期配置。
-
选择附加到域。
-
选中附加的生命周期配置旁边的复选框。
-
选择设为默认值。
设置生命周期配置时,可能会遇到问题。有关调试生命周期配置的信息,请参阅 在亚马逊 SageMaker Studio 经典版中调试生命周期配置。
《数据科学家指南》
使用以下方法连接 Salesforce Data Cloud,并在 Data Wrangler 中访问您的数据。
重要
您的管理员需要使用上述部分中的信息来设置 Salesforce Data Cloud。如果您遇到问题,请与他们联系,以获得故障排除帮助。
要打开 Studio Classic 并检查其版本,请参阅以下步骤。
-
按照中的先决条件步骤通过 Amazon SageMaker Studio Classic 访问 Data Wrangler。
-
在要用来启动 Studio Classic 的用户旁边,选择启动应用程序。
-
选择 Studio。
在 Data Wrangler 中使用 Salesforce Data Cloud 的数据创建数据集
-
选择 Studio。
-
选择启动应用程序。
-
从下拉列表中选择 Studio。
-
选择主页图标。
-
选择数据。
-
选择 Data Wrangler。
-
选择导入数据。
-
在可用下,选择 Salesforce Data Cloud。
-
对于连接名称,为与 Salesforce Data Cloud 的连接指定一个名称。
-
对于组织 URL,指定您的 Salesforce 账户中的组织 URL。可以从管理员那里获取 URL。
-
选择连接。
-
指定用于登录 Salesforce 的凭证。
连接到 Salesforce Data Cloud 后,即可开始使用其中的数据创建数据集。
选择表后,可以编写查询并运行。查询输出显示在查询结果下方。
确定查询输出后,可以将查询的输出导入到 Data Wrangler 流中,以执行数据转换。
创建数据集后,导航到数据流屏幕,开始转换数据。
从 Snowflake 导入数据
您可以在 Data Wrangler 中使用 Snowflake 作为 SageMaker 数据源,在 Snowflake 中为机器学习准备数据。
利用 Snowflake 作为 Data Wrangler 中的数据来源,您可以快速连接到 Snowflake,而无需编写一行代码。在 Data Wrangler 中,可以将 Snowflake 中的数据与来自任何其他数据来源的数据联接起来。
连接后,您可以交互式查询存储在 Snowflake 中的数据,使用 300 多种预配置的数据转换方式来转换数据,使用一组强大的预配置可视化模板了解数据并识别潜在的错误和极端值,快速识别数据准备工作流中的不一致性,并在将模型部署到生产环境之前诊断问题。最后,您可以将数据准备工作流程导出到 Amazon S3,以用于其他 SageMaker 人工智能功能,例如亚马逊 SageMaker 自动驾驶、亚马逊 SageMaker 功能商店和亚马逊 SageMaker 管道。
您可以使用自己创建的 Amazon Key Management Service 密钥对查询输出进行加密。有关的更多信息 Amazon KMS,请参阅Amazon Key Management Service。
管理员指南
重要
要了解有关细粒度访问控制和最佳实践的更多信息,请参阅安全访问控制
本节适用于在 Data Wrangler 中设置对 Snowflake 的访问权限的 Snowflake 管理员。 SageMaker
重要
您负责管理和监控 Snowflake 中的访问控制。Data Wrangler 不会添加与 Snowflake 相关的访问控制层。
访问控制包括以下内容:
-
用户访问的数据
-
(可选)使 Snowflake 能够将查询结果写入到 Amazon S3 存储桶的存储集成
-
用户可以运行的查询
(可选)配置 Snowflake 数据导入权限
默认情况下,Data Wrangler 会查询 Snowflake 中的数据,而不在 Amazon S3 位置中创建数据的副本。如果要配置与 Snowflake 的存储集成,请使用以下信息。您的用户可以使用存储集成,将查询结果存储在 Amazon S3 位置。
您的用户对敏感数据的访问权限可能会有所不同。为了获得最佳的数据安全性,请为每位用户提供各自的存储集成。每个存储集成都应具有各自的数据监管策略。
该功能目前在您所选择的区域中不可用。
Snowflake 需要对 S3 存储桶和目录具有以下权限,才能访问目录中的文件:
-
s3:GetObject -
s3:GetObjectVersion -
s3:ListBucket -
s3:ListObjects -
s3:GetBucketLocation
创建一个 IAM 策略
您必须创建 IAM 策略,以便配置 Snowflake 从 Amazon S3 存储桶加载数据以及将数据卸载到 Amazon S3 存储桶的访问权限。
下面是用来创建策略的 JSON 策略文档:
# Example policy for S3 write access # This needs to be updated { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:PutObject", "s3:GetObject", "s3:GetObjectVersion", "s3:DeleteObject", "s3:DeleteObjectVersion" ], "Resource": "arn:aws:s3:::bucket/prefix/*" }, { "Effect": "Allow", "Action": [ "s3:ListBucket" ], "Resource": "arn:aws:s3:::bucket/", "Condition": { "StringLike": { "s3:prefix": ["prefix/*"] } } } ] }
有关使用策略文档创建策略的信息和过程,请参阅创建 IAM 策略。
有关概要介绍如何在 Snowflake 中使用 IAM 权限的文档,请参阅以下资源:
要向数据科学家的 Snowflake 角色授予对存储集成的使用权限,必须运行 GRANT USAGE ON INTEGRATION
integration_name TO snowflake_role;。
-
integration_name是您的存储集成的名称。 -
snowflake_role是为数据科学家用户授予的默认 Snowflake 角色的名称。
设置 Snowflake OAuth 访问权限
可以让您的用户使用身份提供商来访问 Snowflake,而不是让用户直接在 Data Wrangler 中输入凭证。下面是介绍 Data Wrangler 支持的身份提供商的 Snowflake 文档的链接。
使用前述链接中的文档来设置对您的身份提供商的访问权限。本节中的信息和过程有助于您了解如何正确使用文档在 Data Wrangler 中访问 Snowflake。
您的身份提供商需要将 Data Wrangler 识别为应用程序。通过以下过程,将 Data Wrangler 注册为身份提供商中的应用程序:
-
选择开始将 Data Wrangler 注册为应用程序的过程的配置。
-
为身份提供商中的用户提供对 Data Wrangler 的访问权限。
-
通过将客户端凭据存储为密钥来启用 OAuth 客户端身份 Amazon Secrets Manager 验证。
-
使用以下格式指定重定向网址:https://
domain-ID.studio。Amazon Web Services 区域.sagemaker。 aws/jupyter/default/lab重要
您正在指定用于运行 Data Wrangl Amazon Web Services 区域 er 的 SageMaker Amazon AI 域名 ID。
重要
您必须为每个 Amazon A SageMaker I 域名以及运行 Data Wrangler 的 Amazon Web Services 区域 位置注册一个 URL。来自某个网域但未为 Amazon Web Services 区域 其设置重定向网址的用户将无法通过身份提供商进行身份验证以访问 Snowflake 连接。
-
确保 Data Wrangler 应用程序允许使用授权代码和刷新令牌授予类型。
在身份提供商中,您必须设置一个服务器,在用户级别向 Data Wrangler 发送 OAuth 令牌。该服务器应发送以 Snowflake 为受众的令牌。
Snowflake 使用的角色概念与 IAM 角色中使用的角色截然不同。 Amazon您必须配置身份提供商,以便让任何角色来使用与 Snowflake 账户关联的默认角色。例如,如果用户在 Snowflake 配置文件中使用 systems administrator 作为默认角色,则从 Data Wrangler 到 Snowflake 的连接会将 systems administrator 用作角色。
通过以下过程设置驱动程序。
要设置服务器,请执行以下操作。除最后一个步骤外,在所有其他步骤中,您在 Snowflake 中工作。
-
开始设置服务器或 API。
-
将授权服务器配置为使用授权代码和刷新令牌授予类型。
-
指定访问令牌的生命周期。
-
设置刷新令牌空闲超时。空闲超时是指刷新令牌在未使用的情况下失效的时间。
注意
如果在 Data Wrangler 中调度作业,我们建议将空闲超时时间设置为大于处理作业的频率。否则,由于刷新令牌在运行之前就已过期,某些处理作业可能会失败。刷新令牌到期后,用户必须通过 Data Wrangler 访问他们与 Snowflake 建立的连接,以便重新进行身份验证。
-
将
session:role-any指定为新范围。注意
对于 Azure AD,复制作用域的唯一标识符。Data Wrangler 要求您提供标识符。
-
重要
在 Snowflake 的外部 OAuth 安全集成中,启用
external_oauth_any_role_mode。
重要
Data Wrangler 不支持轮换刷新令牌。使用轮换刷新令牌可能会导致访问失败或用户需要经常登录。
重要
如果刷新令牌过期,用户必须通过 Data Wrangler 访问他们与 Snowflake 建立的连接,以便重新进行身份验证。
设置 OAuth 提供商后,需要向 Data Wrangler 提供连接到该提供商所需的信息。可以使用身份提供商提供的文档来获取以下字段的值:
-
令牌 URL – 身份提供商发送给 Data Wrangler 的令牌的 URL。
-
授权 URL – 身份提供商的授权服务器的 URL。
-
客户端 ID – 身份提供商的 ID。
-
客户端密钥 – 只有授权服务器或 API 能够识别的密钥。
-
(仅限 Azure AD)您复制的 OAuth 作用域凭证。
您将字段和值存储在 Amazon Secrets Manager 密钥中,然后将其添加到用于数据牧马人的 Amazon SageMaker Studio Classic 生命周期配置中。生命周期配置是一个 shell 脚本。通过该配置,Data Wrangler 可以访问密钥的 Amazon 资源名称 (ARN)。有关创建密钥的信息,请参阅将硬编码密钥移至。 Amazon Secrets Manager有关在 Studio Classic 中使用生命周期配置的信息,请参阅 使用生命周期配置自定义 Amazon SageMaker Studio 经典版。
重要
在创建 Secrets Manager 密钥之前,请确保你在 Amazon SageMaker Studio Classic 中使用的 A SageMaker I 执行角色有权在 Secrets Manager 中创建和更新密钥。有关添加权限的更多信息,请参阅示例:创建密钥的权限。
对于 Okta 和 Ping 联合身份验证,密钥格式如下:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"OKTA"|"PING_FEDERATE", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize" }
对于 Azure AD,密钥格式如下:
{ "token_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/token", "client_id":"example-client-id", "client_secret":"example-client-secret", "identity_provider":"AZURE_AD", "authorization_url":"https://identityprovider.com/oauth2/example-portion-of-URL-path/v2/authorize", "datasource_oauth_scope":"api://appuri/session:role-any)" }
生命周期配置必须使用已创建的 Secrets Manager 密钥。可以创建生命周期配置,也可以修改已创建的生命周期配置。配置必须使用以下脚本。
#!/bin/bash set -eux ## Script Body cat > ~/.snowflake_identity_provider_oauth_config <<EOL { "secret_arn": "example-secret-arn" } EOL
有关设置生命周期配置的信息,请参阅 创建生命周期配置并将其与 Amazon SageMaker Studio Classic 关联。完成设置过程时,请执行以下操作:
-
将配置的应用程序类型设置为
Jupyter Server。 -
将配置附加到拥有您的用户的 SageMaker Amazon AI 域。
-
让配置在默认情况下运行。每次用户登录 Studio Classic 时,它都必须运行。否则,您的用户在使用 Data Wrangler 时,将无法使用保存在配置中的凭证。
-
生命周期配置将在用户的主文件夹中创建一个名为
snowflake_identity_provider_oauth_config的文件。该文件包含 Secrets Manager 密钥。确保每次初始化 Jupyter Server 的实例时,该文件都位于用户的主文件夹中。
通过 Data Wrangler 和 Snowflake 之间的私有连接 Amazon PrivateLink
本节介绍如何使用 Amazon PrivateLink 在 Data Wrangler 和 Snowflake 之间建立私有连接。这些步骤将在以下各节详细介绍。
创建 VPC
如果您尚未设置 VPC,请按照创建新的 VPC 中的说明,创建一个。
选择要用于建立私有连接的 VPC 后,请向 Snowflake 管理员提供以下凭证,以便启用 Amazon PrivateLink:
-
- VPC ID
-
Amazon 账户编号
-
您用于访问 Snowflake 的相应账户 URL
重要
按照 Snowflake 文档中所述,启用 Snowflake 账户最多可能需要两个工作日。
设置 Snowflake Amazon PrivateLink 集成
激活后 Amazon PrivateLink ,通过在 Snowflake 工作表中运行以下命令来检索您所在地区的 Amazon PrivateLink 配置。登录您的 Snowflake 控制台,然后在工作表下输入以下内容:select
SYSTEM$GET_PRIVATELINK_CONFIG();
-
从生成的 JSON 对象中检索以下项的值:
privatelink-account-name、privatelink_ocsp-url、privatelink-account-url和privatelink_ocsp-url。以下代码段显示了每个值的示例。存储这些值以供以后使用。privatelink-account-name: xxxxxxxx.region.privatelink privatelink-vpce-id: com.amazonaws.vpce.region.vpce-svc-xxxxxxxxxxxxxxxxx privatelink-account-url: xxxxxxxx.region.privatelink.snowflakecomputing.com privatelink_ocsp-url: ocsp.xxxxxxxx.region.privatelink.snowflakecomputing.com -
切换到您的 Amazon 控制台并导航到 VPC 菜单。
-
在左侧面板中,选择端点链接,导航到 VPC 端点设置。
在设置中,选择创建端点。
-
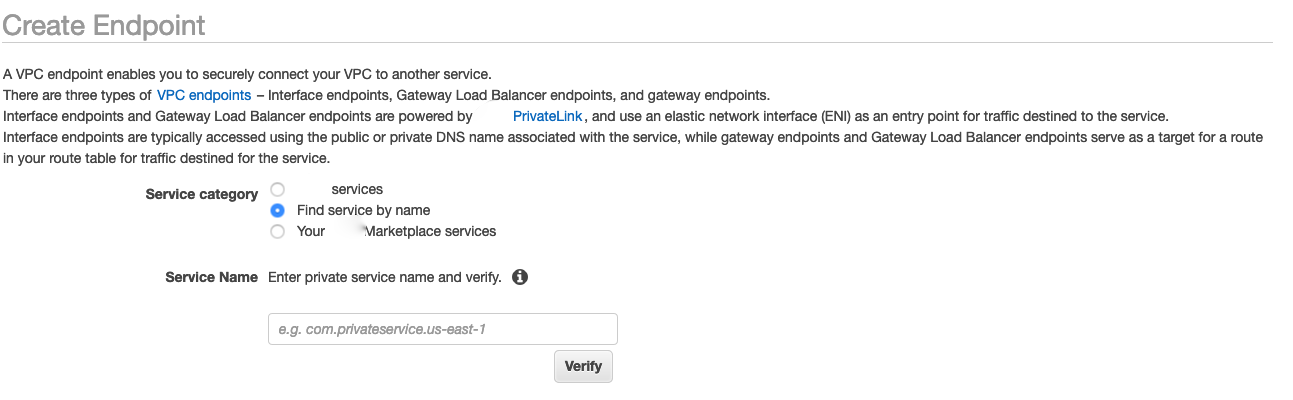
选择按名称查找服务单选按钮,如以下屏幕截图所示。
-
在服务名称字段中,粘贴您在上一步中为
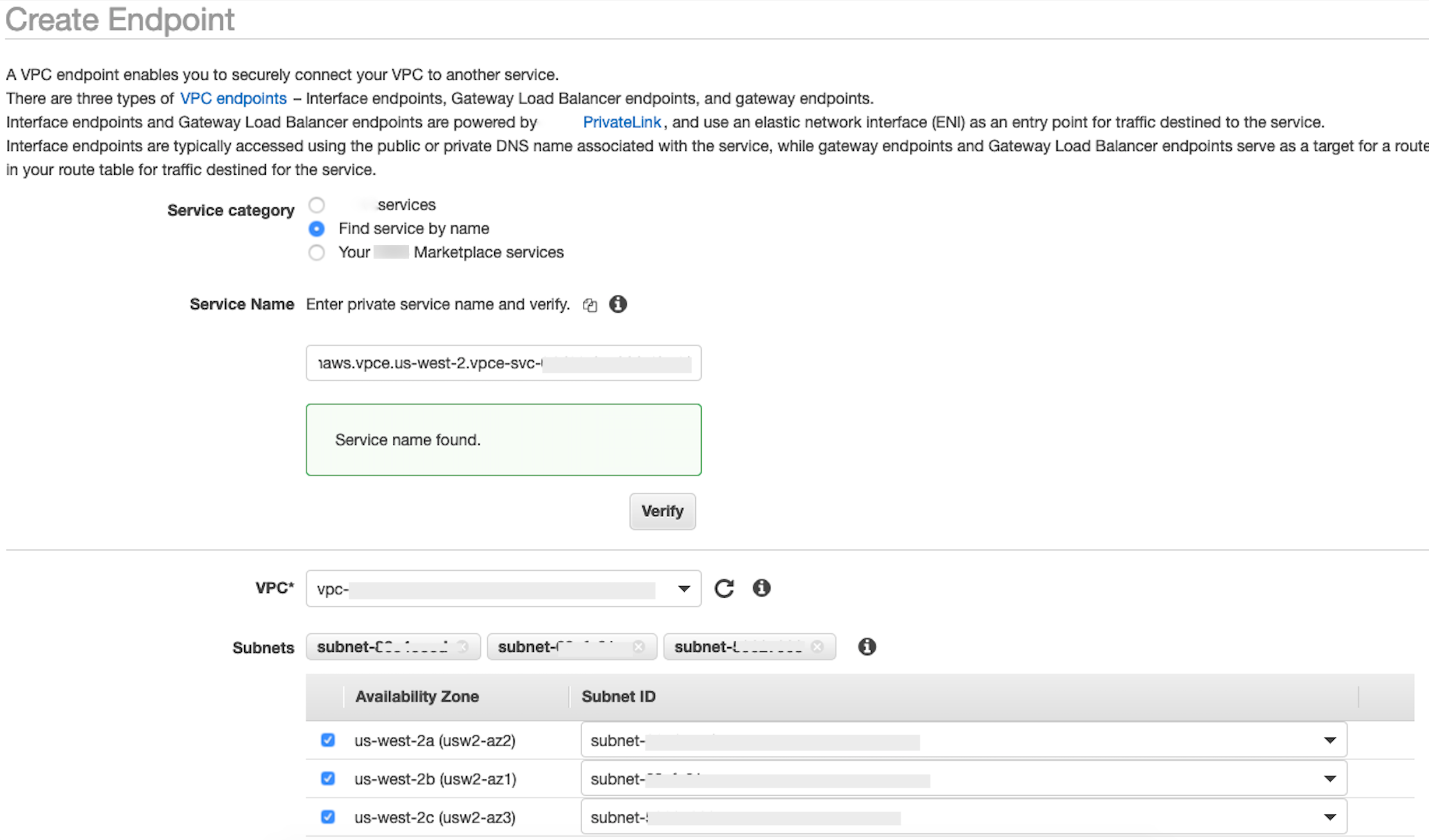
privatelink-vpce-id检索到的值,然后选择验证。如果连接成功,屏幕上会显示一条绿色提醒消息,提示已找到服务名称,并且 VPC 和子网选项会自动展开,如以下屏幕截图中所示。根据您的目标区域,出现的屏幕中可能会显示其他 Amazon 区域名称。
-
从 VPC 下拉列表中,选择您发送到 Snowflake 的相同 VPC ID。
-
如果您尚未创建子网,请按照以下有关创建子网的说明执行操作。
-
从 VPC 下拉列表中选择子网。然后选择创建子网,并按照提示在您的 VPC 中创建子集。确保选择您发送到 Snowflake 的 VPC ID。
-
在安全组配置下,选择创建新安全组,在新选项卡中打开默认安全组屏幕。在这个新选项卡中,选择创建安全组。
-
提供新安全组的名称(例如
datawrangler-doc-snowflake-privatelink-connection)和描述。确保选择您在之前步骤中使用的 VPC ID。 -
添加两个规则,以便允许流量从 VPC 内部流向此 VPC 端点。
在单独的选项卡中导航到您的 VPC 下的 VPC,然后检索 VPC 的 CIDR 块。在入站规则部分中,选择添加规则。为类型选择
HTTPS,在表单中将源保留为自定义,然后粘贴从上一个describe-vpcs调用中检索到的值(例如10.0.0.0/16)。 -
选择创建安全组。从新创建的安全组中检索安全组 ID(例如
sg-xxxxxxxxxxxxxxxxx)。 -
在 VPC 端点配置屏幕中,删除默认安全组。在搜索字段中粘贴安全组 ID,然后选中该复选框。
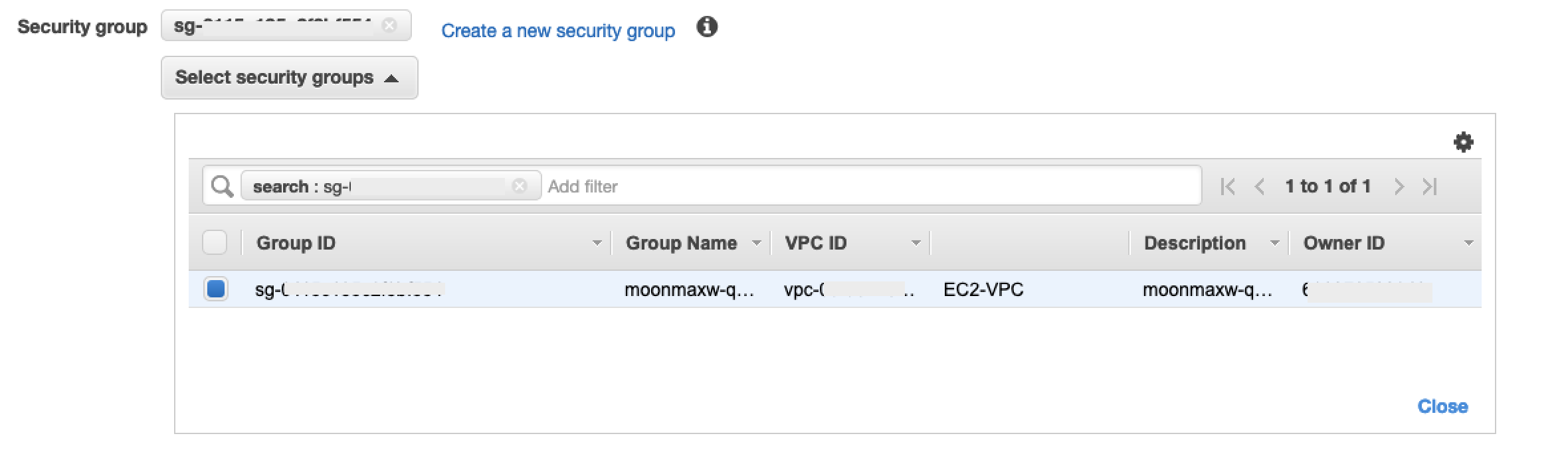
-
选择创建端点。
-
如果端点创建成功,您将看到一个页面,其中包含指向 VPC ID 所指定的 VPC 端点配置的链接。选择该链接可以查看完整配置。
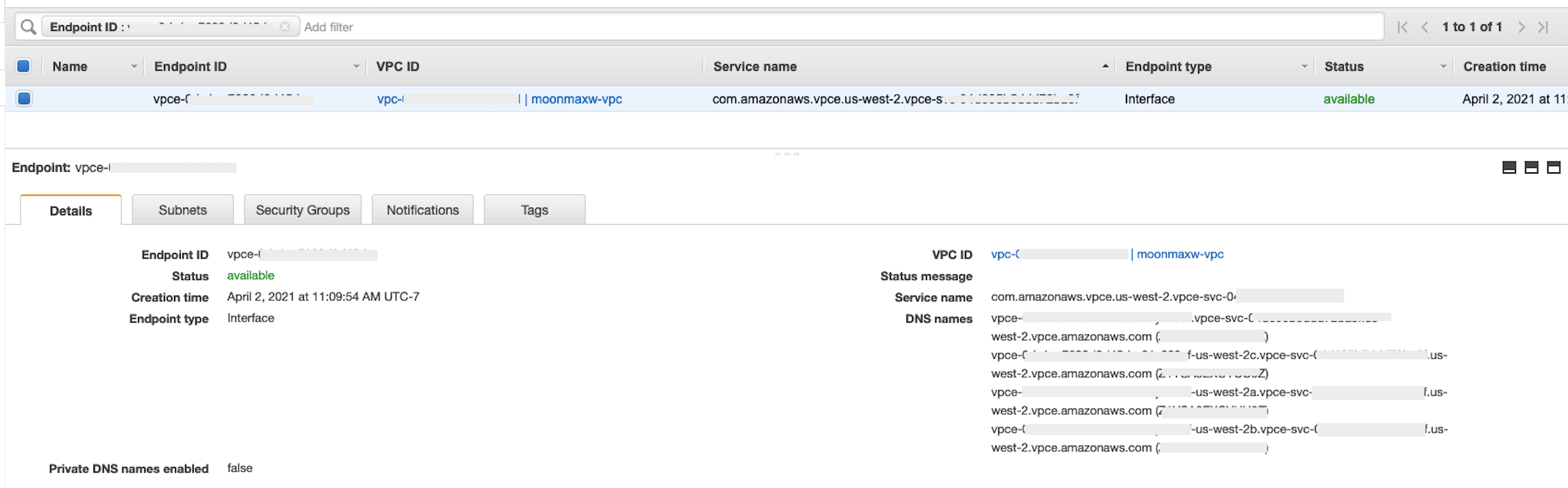
检索 DNS 名称列表中最上面的记录。这可以与其他 DNS 名称区分开来,因为它只包含区域名称(例如
us-west-2),但不包含可用区字母表示法(例如us-west-2a)。存储此信息以供以后使用。
在 VPC 中为 Snowflake 端点配置 DNS
本节介绍如何在您的 VPC 中为 Snowflake 端点配置 DNS。这样,VPC 就可以解析对 Snowflake Amazon PrivateLink 端点的请求。
-
导航到 Amazon 控制台中的 Route 53 菜单
。 -
选择托管区域选项(如有必要,展开左侧菜单以找到此选项)。
-
选择创建托管区域。
-
在域名字段中,引用在前述步骤中为
privatelink-account-url存储的值。在此字段中,Snowflake 账户 ID 将从 DNS 名称中删除,并且只使用以区域标识符开头的值。后面还会为子域创建一个资源记录集,例如region.privatelink.snowflakecomputing.com。 -
在类型部分中,选择私有托管区域的单选按钮。您的区域代码可能不是
us-west-2。引用 Snowflake 返回的 DNS 名称。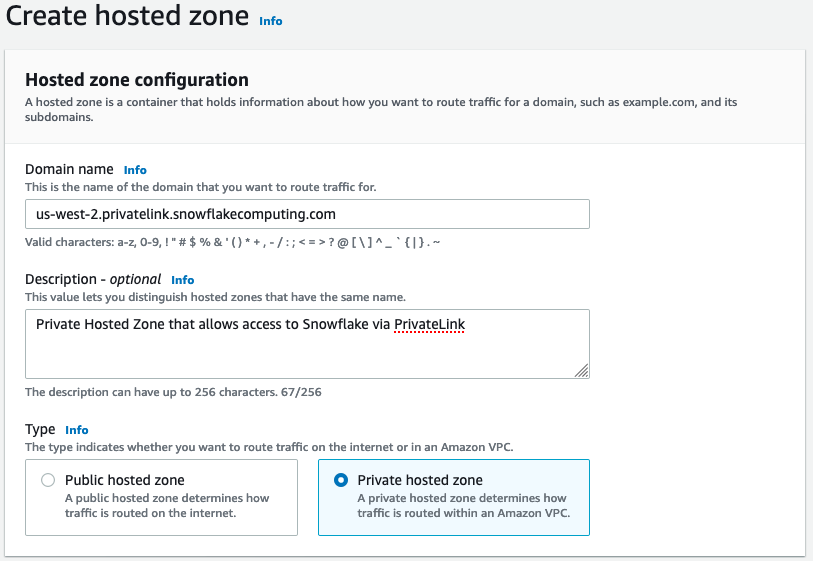
-
在要与托管区域关联的 VPC 部分中,选择您的 VPC 所在的区域以及前述步骤中使用的 VPC ID。
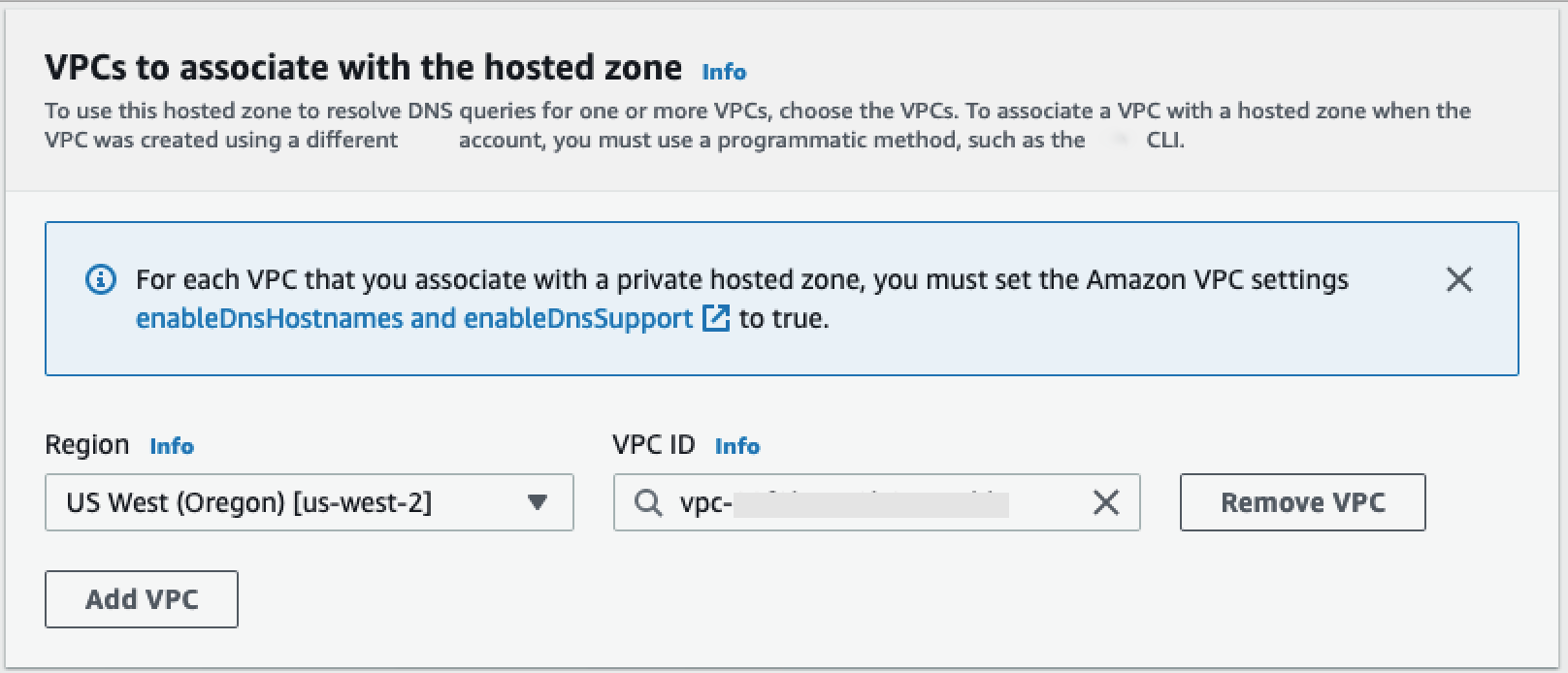
-
选择创建托管区域。
-
-
接下来,创建两个记录,一条用于
privatelink-account-url,另一个用于privatelink_ocsp-url。-
在托管区域菜单中,选择创建记录集。
-
在记录名称下,只输入您的 Snowflake 账户 ID(
privatelink-account-url中的前 8 个字符)。 -
在记录类型下,选择 CNAME。
-
在值下,输入您在设置 Snowflake Amazon PrivateLink 集成部分的最后一步中检索的区域 VPC 端点的 DNS 名称。
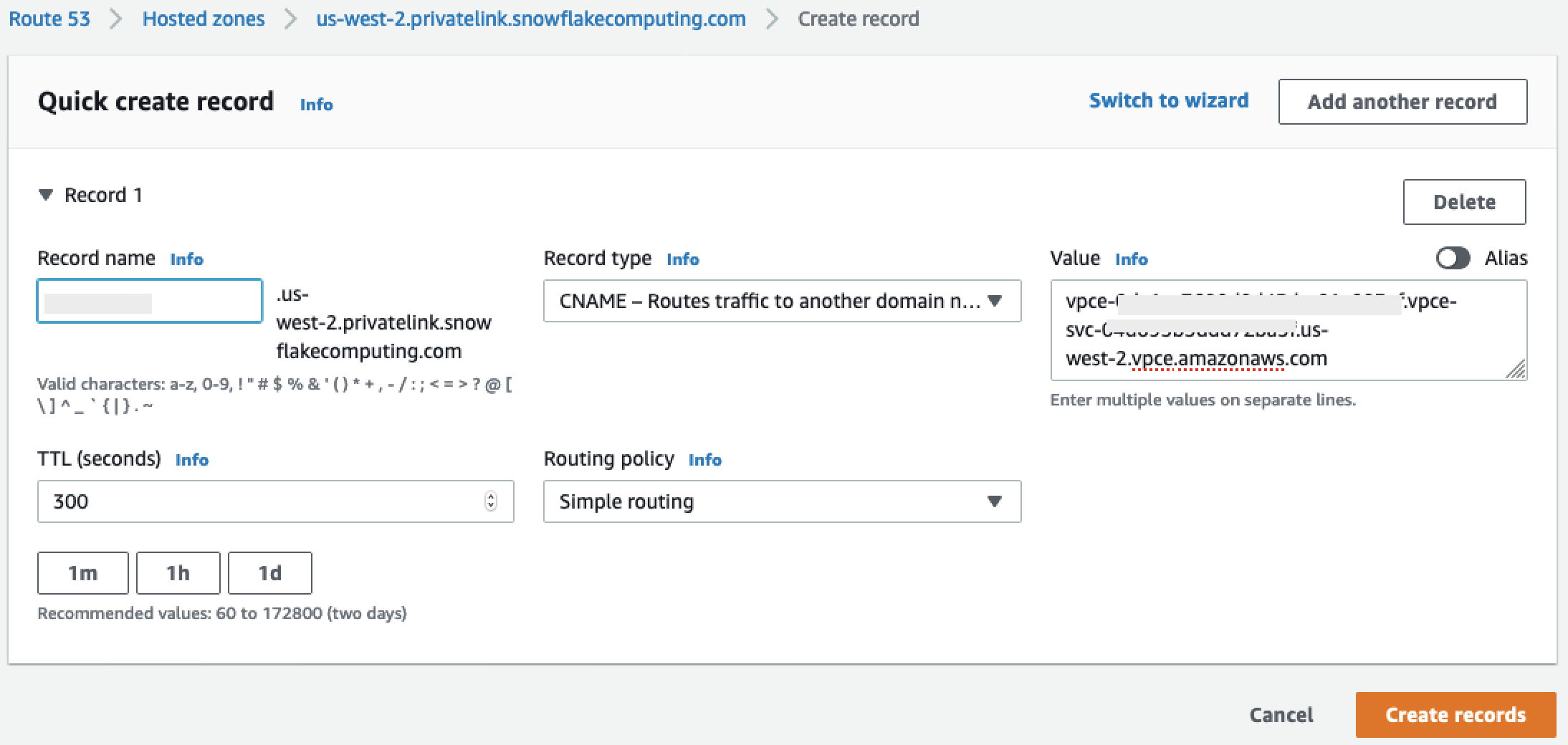
-
选择创建记录。
-
对我们标注为
privatelink-ocsp-url的 OCSP 记录重复上述步骤,从ocsp开始到记录名称的 8 个字符的 Snowflake ID(例如ocsp.xxxxxxxx)。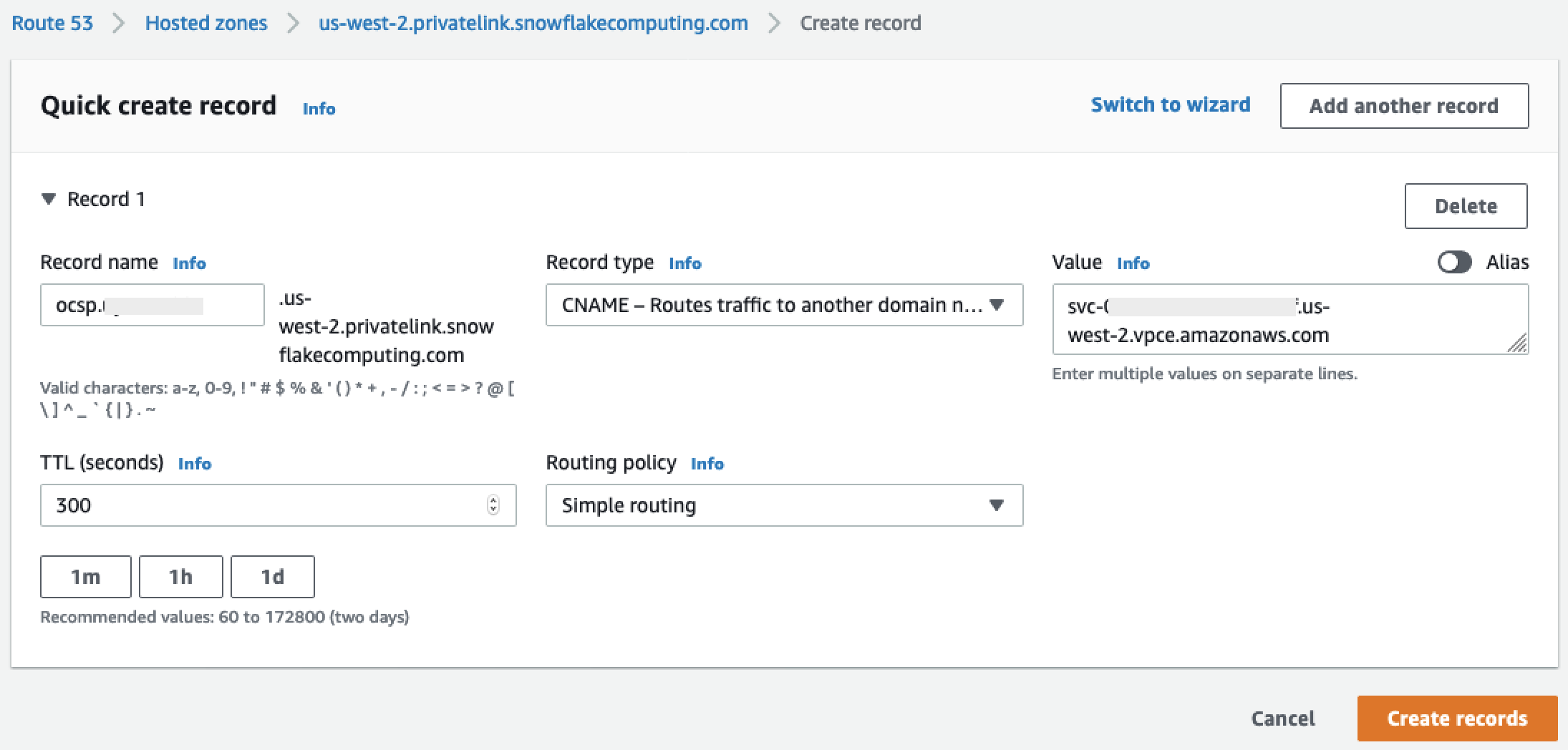
-
-
为 VPC 配置 Route 53 解析器入站端点
本节介绍如何为您的 VPC 配置 Route 53 解析器入站端点。
-
导航到 Amazon 控制台中的 Route 53 菜单
。 -
在左侧面板的安全部分中,选择安全组选项。
-
-
选择创建安全组。
-
提供您的安全组的名称(例如
datawranger-doc-route53-resolver-sg)和描述。 -
选择之前步骤中使用的 VPC ID。
-
创建允许从 VPC CIDR 块内通过 UDP 和 TCP 进行 DNS 的规则。

-
选择创建安全组。请注意安全组 ID,因为将会添加允许流向 VPC 端点安全组的流量的规则。
-
-
导航到 Amazon 控制台中的 Route 53 菜单
。 -
在解析器部分中,选择入站端点选项。
-
-
选择创建入站端点。
-
提供端点名称。
-
从区域中的 VPC 下拉列表中,选择您在前面的所有步骤中使用的 VPC ID。
-
在此端点的安全组下拉列表中,选择本节步骤 2 中的安全组 ID。
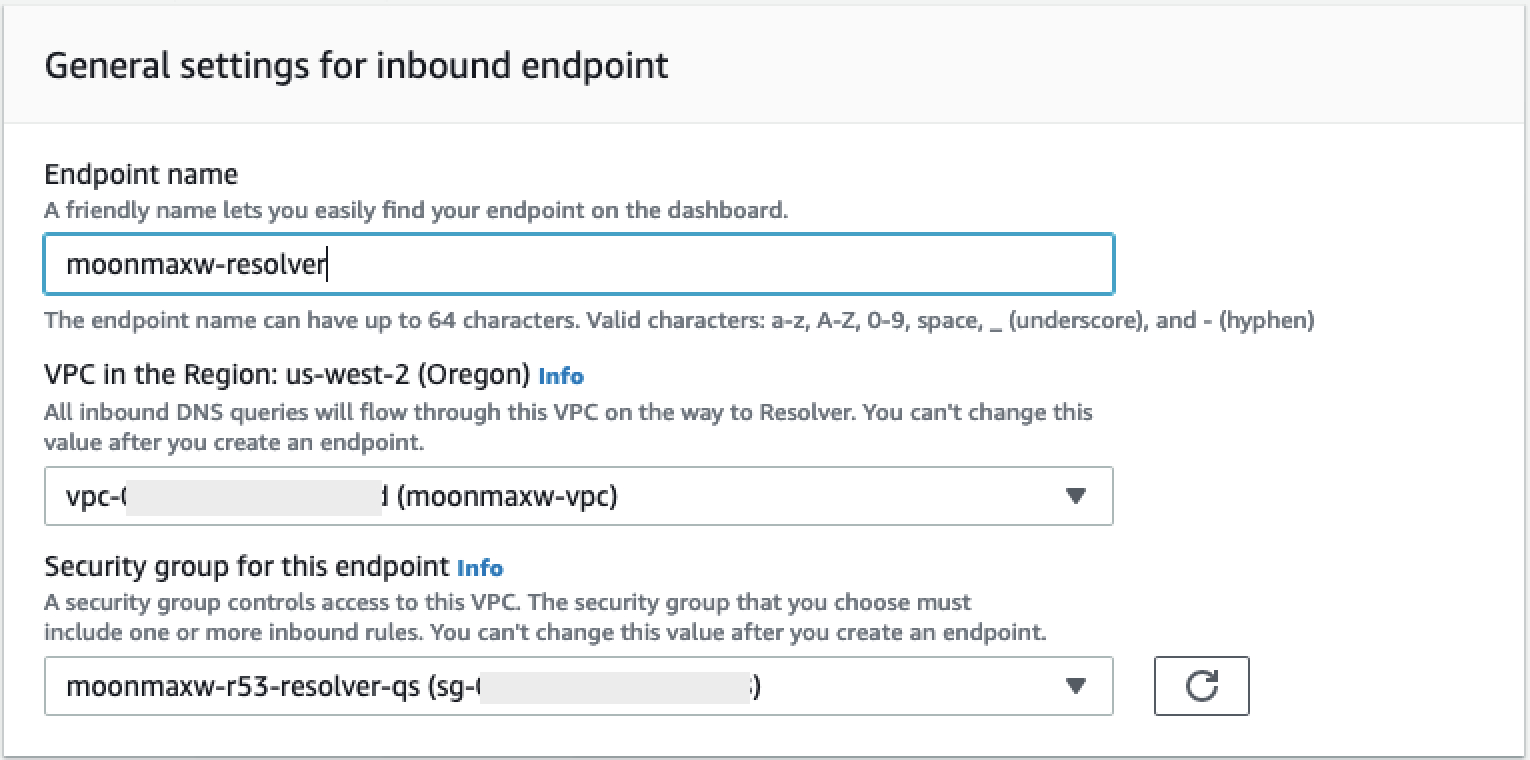
-
在 IP 地址部分中,选择可用区,选择一个子网,然后保留为每个 IP 地址选择的使用自动选择的 IP 地址单选按钮。
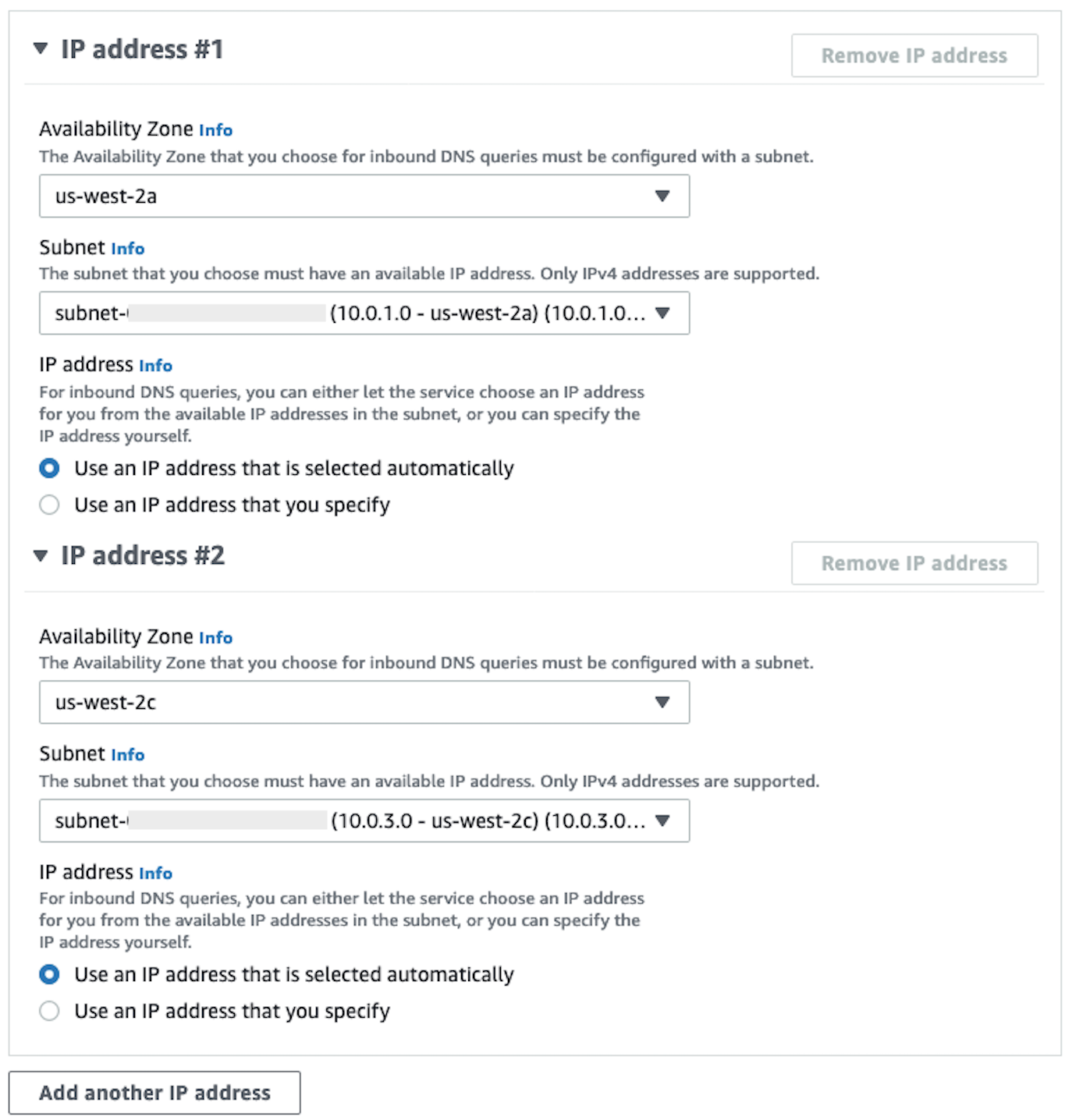
-
选择提交。
-
-
创建入站端点后,选择入站端点。
-
创建入站端点后,记录解析器的两个 IP 地址。

SageMaker AI VPC 终端节点
本节介绍如何为以下设备创建 VPC 终端节点:Amazon SageMaker Studio Classic、 SageMaker 笔记本电脑、 SageMaker API、 SageMaker 运行时和亚马逊 SageMaker 功能商店运行时。
创建应用于所有端点的安全组。
-
导航到 Amazon 控制台中的 EC2 菜单
。 -
在网络和安全部分中,选择安全组选项。
-
选择创建安全组。
-
提供安全组的名称和描述(例如
datawrangler-doc-sagemaker-vpce-sg)。稍后会添加一条规则,允许通过 HTTPS 从 SageMaker AI 向该群组发送流量。
创建端点
-
导航到 Amazon 控制台中的 VPC 菜单
。 -
选择端点选项。
-
选择创建端点。
-
通过在搜索字段中输入服务名称,来搜索服务。
-
从 VPC 下拉列表中,选择存在您的 Snowflake Amazon PrivateLink 连接的 VPC。
-
在子网部分中,选择有权访问 Snow PrivateLink flake 连接的子网。
-
将启用 DNS 名称复选框保留选中状态。
-
在安全组部分中,选择您在上一节中创建的安全组。
-
选择创建端点。
配置 Studio Classic 和 Data Wrangler
本节介绍如何配置 Studio Classic 和 Data Wrangler。
-
配置安全组。
-
在 Amazon 控制台中导航至 Amazon EC2 菜单。
-
在网络和安全部分中,选择安全组选项。
-
选择创建安全组。
-
提供您的安全组(例如
datawrangler-doc-sagemaker-studio)的名称和描述。 -
创建以下入站规则。
-
与您为在设置 Snowflake 集成步骤中创建的 Snowflake PrivateLink 连接配置的安全组的 HTTPS 连接。 PrivateLink
-
与您为在设置 Snowflake 集成步骤中创建的 Snowflake PrivateLink 连接配置的安全组的 HTTP 连接。 PrivateLink
-
到 Route 53 解析器入站端点安全组的 DNS(端口 53)的 UDP 和 TCP 连接,该安全组是您在为 VPC 配置 Route 53 解析器入站端点的步骤 2 中创建的。
-
-
选择右下角的创建安全组按钮。
-
-
配置 Studio Classic。
-
导航到 Amazon 控制台中的 SageMaker AI 菜单。
-
在左侧控制台中,选择 SageMaker AI Studio Classic 选项。
-
如果您未配置任何域,则会出现开始使用菜单。
-
从开始使用菜单中,选择标准安装选项。
-
对于身份验证方法,选择 Amazon Identity and Access Management (IAM)。
-
从权限菜单中,可以创建新角色或使用预先存在的角色,具体取决于您的使用案例。
-
如果选择创建新角色,则可以选择提供 S3 存储桶名称,并且系统会为您生成策略。
-
如果已经创建了一个角色,该角色对您需要访问的 S3 存储桶拥有权限,请从下拉列表中选择该角色。该角色应附加有
AmazonSageMakerFullAccess策略:
-
-
选择网络和存储下拉列表以配置 SageMaker AI 使用的 VPC、安全和子网。
-
在 VPC 下,选择存在您的 Snowflake PrivateLink 连接的 VPC。
-
在 “子网” 下,选择有权访问 S nowfl PrivateLink ake 连接的子网。
-
在 Studio Classic 的网络访问权限下,选择仅 VPC。
-
在安全组下,选择在步骤 1 中创建的安全组。
-
-
选择提交。
-
-
编辑 A SageMaker I 安全组。
-
创建以下入站规则:
-
将 2049 端口连接到 SageMaker AI 在步骤 2 中自动创建的入站和出站 NFS 安全组(安全组名称包含 Studio Classic 域 ID)。
-
访问其自身的所有 TCP 端口(仅适用于 VPC 的 SageMaker AI 需要)。
-
-
-
编辑 VPC 端点安全组:
-
在 Amazon 控制台中导航至 Amazon EC2 菜单。
-
找到您在前一个步骤中创建的安全组。
-
添加一条入站规则,允许来自步骤 1 中创建的安全组的 HTTPS 流量。
-
-
创建用户配置文件。
-
从 SageMaker Studio Classic 控制面板中,选择添加用户。
-
提供用户名称。
-
然后,对于执行角色,选择创建新的角色或使用现有角色。
-
如果选择创建新角色,则可以选择提供 Amazon S3 存储桶名称,并且系统会为您生成策略。
-
如果已经创建了一个角色,该角色对您需要访问的 Amazon S3 存储桶拥有权限,请从下拉列表中选择该角色。该角色应附加有
AmazonSageMakerFullAccess策略:
-
-
选择提交。
-
-
创建数据流(按照上一节中概述的数据科学家指南执行操作)。
-
添加 Snowflake 连接时,在 Snowflake 帐户名
privatelink-account-name(字母数字)字段中输入值(来自设置 Snowflake PrivateLink 集成步骤),而不是普通的 Snowflake 帐户名。其他所有内容都保持不变。
-
向数据科学家提供信息
向数据科学家提供从亚马逊 AI Data Wrangler 访问 Snowfl SageMaker ake 所需的信息。
重要
您的用户需要运行 Amazon SageMaker Studio 经典版 1.3.0 或更高版本。有关检查 Studio Classic 版本和更新的信息,请参阅 使用 Amazon Data Wrangler 准备机器学习 SageMaker 数据。
-
要允许您的数据科学家从 SageMaker Data Wrangler 访问 Snowflake,请为他们提供以下内容之一:
-
对于基本身份验证,提供 Snowflake 账户名称、用户名和密码。
-
对于 OAuth,提供身份提供商中的用户名和密码。
-
对于 ARN,提供 Secrets Manager 密钥的 Amazon 资源名称 (ARN)。
-
使用 Amazon Secrets Manager 创建的密钥以及密钥的 ARN。如果您选择此选项,请通过以下步骤为 Snowflake 创建密钥。
重要
如果您的数据科学家使用 Snowflake 凭证(用户名和密码)选项连接到 Snowflake,则可以使用 Secrets Manager 将凭证存储在密钥中。Secrets Manager 会作为最佳实践安全计划的一部分轮换密钥。只有在设置 Studio Classic 用户配置文件时配置了 Studio Classic 角色,才能访问在 Secrets Manager 中创建的密文。这需要在 Studio Classic 角色的附加策略中添加
secretsmanager:PutResourcePolicy权限。我们强烈建议您确定角色策略的范围,以便对不同的 Studio Classic 用户组使用不同的角色。可以为 Secrets Manager 密钥添加其他基于资源的权限。有关您可以使用的条件密钥,请参阅管理密钥策略。
有关创建密钥的信息,请参阅创建密钥。您需要为自己创建的密钥付费。
-
-
(可选)向数据科学家提供您使用以下过程创建的存储集成的名称:在 Snowflake 中创建云存储集成
。这是新集成的名称,在您运行的 CREATE INTEGRATIONSQL 命令中称为integration_name,如以下代码段所示:CREATE STORAGE INTEGRATION integration_name TYPE = EXTERNAL_STAGE STORAGE_PROVIDER = S3 ENABLED = TRUE STORAGE_AWS_ROLE_ARN = 'iam_role' [ STORAGE_AWS_OBJECT_ACL = 'bucket-owner-full-control' ] STORAGE_ALLOWED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') [ STORAGE_BLOCKED_LOCATIONS = ('s3://bucket/path/', 's3://bucket/path/') ]
《数据科学家指南》
通过以下过程在 Data Wrangler 中连接 Snowflake 并访问您的数据。
重要
您的管理员需要使用上述部分中的信息来设置 Snowflake。如果您遇到问题,请与他们联系,以获得故障排除帮助。
可以使用以下方法之一连接到 Snowflake:
-
在 Data Wrangler 中指定 Snowflake 凭证(账户名称、用户名称和密码)。
-
提供包含凭证的密钥的 Amazon 资源名称 (ARN)。
-
对连接到 Snowflake 的访问委托 (OAuth) 提供商使用开放标准。您的管理员会授予您访问以下 OAuth 提供商之一的权限:
请咨询您的管理员,了解连接到 Snowflake 要使用的方法。
下面各个部分提供了有关您如何使用上述方法连接到 Snowflake 的信息。
连接到 Snowflake 后,可以开始从 Snowflake 导入数据。
在 Data Wrangler 中,可以查看您的数据仓库、数据库和架构,还会看到可用于预览表的眼睛图标。选择预览表图标后,将生成该表的架构预览。必须先选择数据仓库,然后才能预览表。
重要
如果您要导入的数据集包含的列类型为 TIMESTAMP_TZ 或 TIMESTAMP_LTZ,请在查询的列名中添加 ::string。有关更多信息,请参阅方法:将 TIMESTAMP_TZ 和 TIMESTAMP_LTZ 数据卸载到 Parquet 文件
选择数据仓库、数据库和架构后,现在可以编写并运行查询。查询输出显示在查询结果下方。
确定查询输出后,可以将查询的输出导入到 Data Wrangler 流中,以执行数据转换。
在导入数据后,导航到 Data Wrangler 流,并开始向该流中添加转换。有关可用转换的列表,请参阅 转换数据。
从软件即服务 (SaaS) 平台导入数据
可以使用 Data Wrangler,从四十多个软件即服务 (SaaS) 平台导入数据。要从 SaaS 平台导入数据,您或您的管理员必须使用亚马逊 AppFlow 将数据从该平台传输到亚马逊 S3 或 Amazon Redshift。有关亚马逊的更多信息 AppFlow,请参阅什么是亚马逊 AppFlow? 如果不需要使用 Amazon Redshift,我们建议您将数据传输到 Amazon S3,以便简化流程。
Data Wrangler 支持从以下 SaaS 平台传输数据:
上述列表包含指向有关设置数据来源的更多信息的链接。阅读以下信息后,您或您的管理员可以参考前面的链接。
导航到 Data Wrangler 流的导入选项卡时,您将在以下部分下看到数据来源:
-
可用
-
设置数据来源
不需要进行额外配置,即可连接到可用下的数据来源。您可以选择数据来源并导入数据。
“设置数据源” 下的数据源要求您或您的管理员使用亚马逊将数据从 SaaS 平台传输 AppFlow 到 Amazon S3 或 Amazon Redshift。有关执行传输的信息,请参阅 使用 Amazon AppFlow 传输您的数据。
执行数据传输后,SaaS 平台将作为数据来源显示在可用下。可以选择该数据来源,然后将您传输的数据导入到 Data Wrangler 中。您传输的数据会以表形式出现,可供您查询。
使用 Amazon AppFlow 传输您的数据
亚马逊 AppFlow 是一个无需编写任何代码即可将数据从 SaaS 平台传输到 Amazon S3 或 Amazon Redshift 的平台。要执行数据传输,您可以使用 Amazon Web Services 管理控制台。
重要
必须确保已设置执行数据传输的权限。有关更多信息,请参阅 亚马逊 AppFlow 权限。
添加权限后,可以传输数据。在 Amazon 中 AppFlow,您可以创建一个用于传输数据的流程。流是一系列配置。您可以使用流来指定是否按计划运行数据传输,或者是否要将数据分区为单独的文件。配置完流后,运行该流来传输数据。
有关创建流程的信息,请参阅在 Amazon 中创建流程 AppFlow。有关运行流程的信息,请参阅激活 Amazon AppFlow 流程。
数据传输完成后,使用以下步骤访问 Data Wrangler 中的数据。
重要
尝试访问数据之前,请确保您的 IAM 角色具有以下策略:
默认情况下,用于访问 Data Wrangler 的 IAM 角色是 SageMakerExecutionRole。有关添加策略的更多信息,请参阅添加 IAM 身份权限(控制台)。
要连接到数据来源,请执行以下操作。
-
选择 Studio。
-
选择启动应用程序。
-
从下拉列表中选择 Studio。
-
选择主页图标。
-
选择数据。
-
选择 Data Wrangler。
-
选择导入数据。
-
在可用下,选择数据来源。
-
在名称字段中,指定连接名称。
-
(可选)选择高级配置。
-
选择一个工作组。
-
如果您的工作组尚未强制使用 Amazon S3 输出位置,或者您没有使用工作组,请为查询结果的 Amazon S3 位置指定一个值。
-
(可选)对于数据留存期,选中该复选框以设置数据留存期,并指定在删除数据之前存储数据的天数。
-
(可选)默认情况下,Data Wrangler 会保存连接。可以选择取消选中该复选框,此时不保存连接。
-
-
选择连接。
-
指定查询。
注意
为了协助您指定查询,可以在左侧导航面板上选择一个表。Data Wrangler 将显示表名和表的预览。选择表名称旁边的图标来复制名称。可以在查询中使用表名。
-
选择运行。
-
选择导入查询。
-
对于数据集名称,指定数据集的名称。
-
选择添加。
导航到导入数据屏幕时,您会看到已创建的连接。可以使用该连接来导入更多数据。
导入的数据存储
重要
我们强烈建议您采用安全最佳实践,遵循有关保护 Amazon S3 存储桶的最佳实践。
当您查询来自 Amazon Athena 或 Amazon Redshift 的数据时,查询的数据集会自动存储在 Amazon S3 中。数据存储在您使用 Studio Classic 的 Amazon 区域的默认 SageMaker AI S3 存储桶中。
默认 S3 存储桶的命名约定如下:sagemaker-。例如,如果您的账号是 111122223333,并且在 region-account
numberus-east-1 中使用 Studio Classic,那么导入的数据集将存储在 sagemaker-us-east-1-111122223333 中。
Data Wrangler 流依赖于此 Amazon S3 数据集位置,因此在使用依赖流时,不应在 Amazon S3 中修改此数据集。如果您确实修改了此 S3 位置,并且希望继续使用您的数据流,则必须移除 .flow 文件的 trained_parameters 中的所有对象。为此,请从 Studio Classic 下载 .flow 文件,然后删除 trained_parameters 的每个实例中的所有条目。完成操作后,trained_parameters 应该是一个空的 JSON 对象:
"trained_parameters": {}
当您导出数据流并使用数据流来处理数据时,导出的 .flow 文件会引用 Amazon S3 中的此数据集。使用以下部分了解更多信息。
Amazon Redshift 导入存储
Data Wrangler 将您的查询结果的数据集存储在默认 SageMaker AI S3 存储桶中的 Parquet 文件中。
此文件存储在以下前缀(目录)下:redshift/ uuid /data/,其中uuid是为每个查询创建的唯一标识符。
例如,如果您的默认存储桶是sagemaker-us-east-1-111122223333,则从 Amazon Redshift 查询的单个数据集位于 s3://sagemaker-us-east-1 111122223333/redshift-//data/。uuid
Amazon Athena 导入存储
在查询 Athena 数据库并导入数据集时,Data Wrangler 会将数据集以及该数据集的子集(或称预览文件)存储在 Amazon S3 中。
您通过选择导入数据集导入的数据集,将以 Parquet 格式存储在 Amazon S3 中。
在 Athena 导入屏幕上选择运行时,预览文件将以 CSV 格式写入,并且最多可包含来自所查询数据集的 100 行。
您查询的数据集位于前缀(目录)下:athena/ uuid /data/,其中uuid是为每个查询创建的唯一标识符。
例如,如果您的默认存储桶是sagemaker-us-east-1-111122223333,则从 Athena 查询的单个数据集位于 /athena/ /data/ 中。s3://sagemaker-us-east-1-111122223333 uuid example_dataset.parquet
用于在 Data Wrangler 中预览数据框架的数据集子集则存储在以下前缀下:athena/。