本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
转换数据
Amazon SageMaker Data Wrangler 提供大量机器学习数据转换,以简化数据的清理、转换和特征化。当您添加转换时,数据流会增加一个步骤。您添加的每个转换都会修改数据集,并生成新的数据框。所有后续转换都适用于生成的数据框。
Data Wrangler 包括内置转换,可用于转换列而无需任何代码。您还可以使用 Python(User-Defined 函数) PySpark、pandas 和 PySpark SQL 添加自定义转换。有些转换可就地运行,而其他一些转换会在数据集中创建新的输出列。
您可以一次将转换应用于多列。例如,您可以在一个步骤中删除多列。
处理数字和处理缺失值转换只能应用于单列。
可通过本页面了解有关内置转换和自定义转换的更多信息。
转换 UI
大多数内置转换都位于 Data Wrangler UI 的准备选项卡中。您可以通过数据流视图访问联接转换和串联转换。可使用下表预览这两种视图。
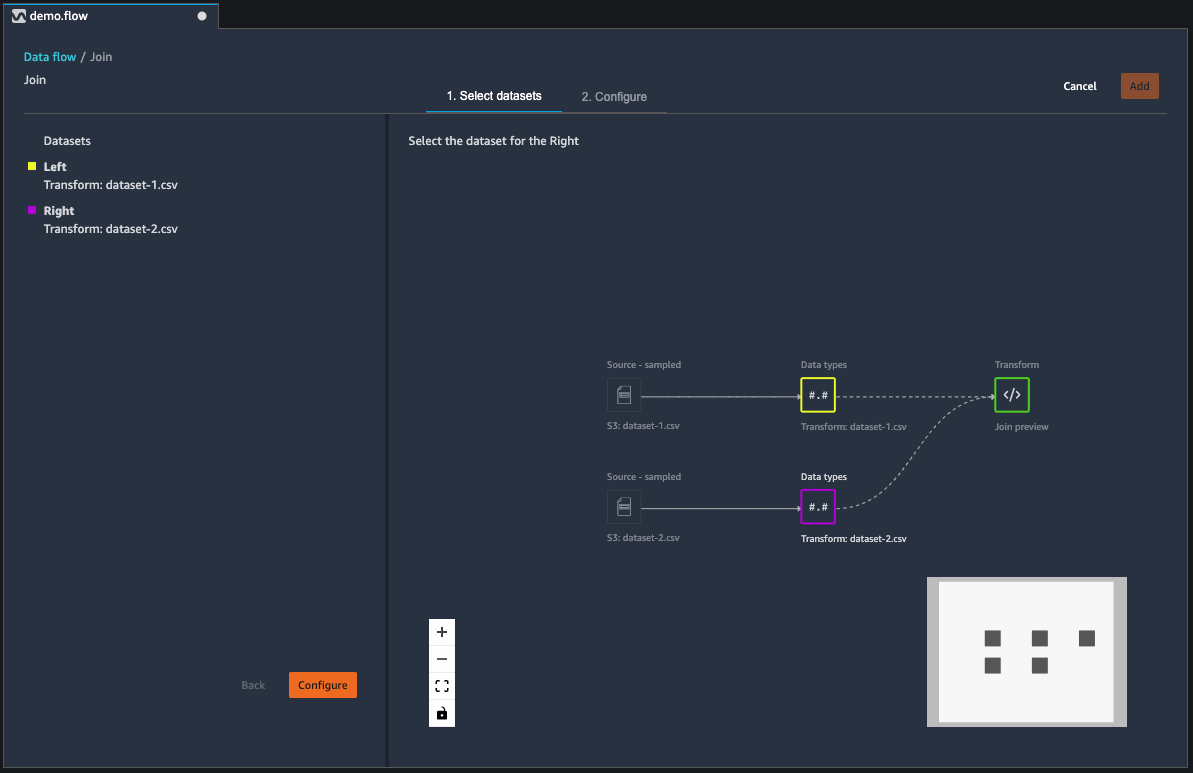

联接数据集
您可以在数据流中直接联接数据框。在联接两个数据集时,生成的联接数据集将显示在流中。Data Wrangler 支持以下联接类型。
-
左外 – 包括左表中的所有行。如果左表行中联接的列值与任何右表行值均不匹配,那么在联接的表中该行为所有右表列显示空值。
-
左反 – 包括左表中不包含右表中联接列的值的行。
-
左半 – 对于满足联接语句中标准的所有相同行,包括左表中的单行。此类型从左表中排除了符合联接标准的重复行。
-
右外 – 包括右表中的所有行。如果右表行中联接的列值与任何左表行值均不匹配,那么在联接的表中该行为所有左表列显示空值。
-
内部 – 包括左表和右表中联接列中包含匹配值的行。
-
全外 – 包括左表和右表中的所有行。如果任一表中联接列的行值不匹配,则会在联接的表中创建单独的行。如果在联接的表中行不包含列的值,则为该列插入空值。
-
笛卡尔交叉 – 包括将第一个表中的每一行与第二个表中的每一行相结合的行。这是联接中表行的笛卡尔乘积
。乘积的结果即左表的大小乘以右表的大小。因此,我们建议在大型数据集之间慎用此联接类型。
可使用以下过程,联接两个数据框。
-
选择要联接的左数据框旁边的 +。您选择的第一个数据框始终是联接中的左表。
-
选择联接。
-
选择右数据框。您选择的第二个数据框始终是联接中的右表。
-
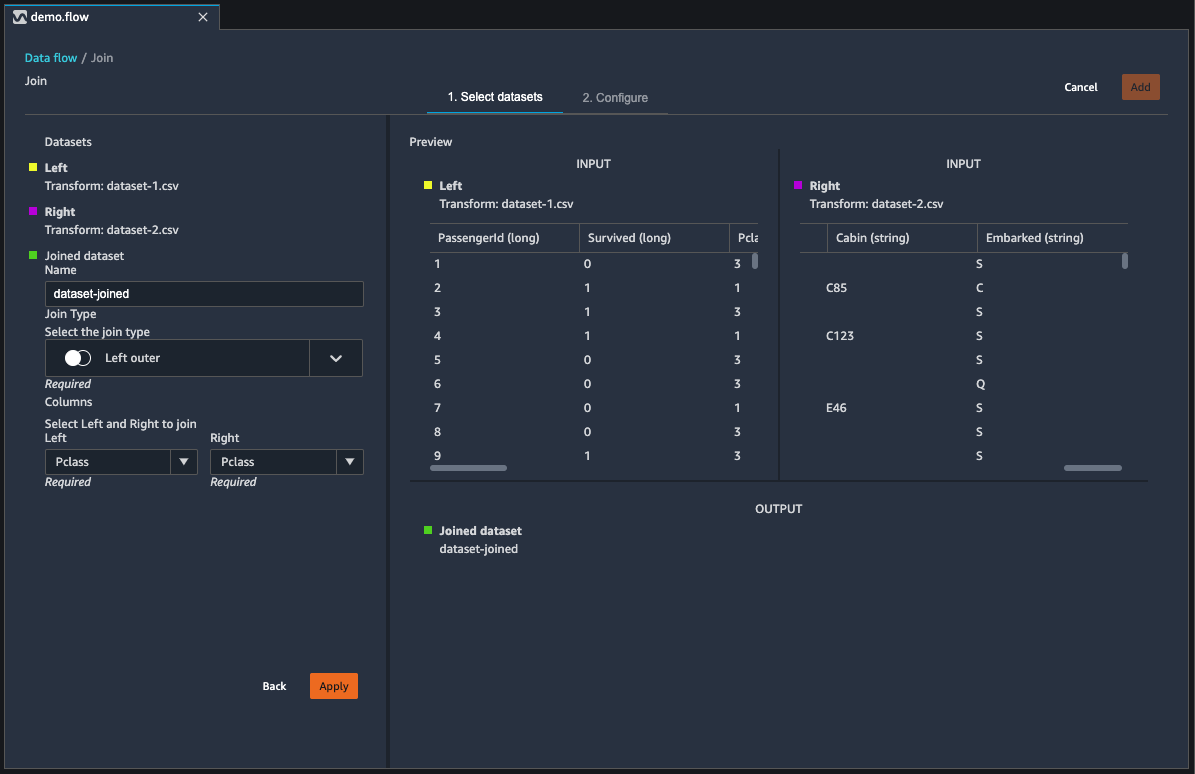
选择配置以配置您的联接。
-
使用名称字段,为联接的数据集命名。
-
选择联接类型。
-
从左表和右表中选择要联接的列。
-
选择应用,在右侧预览联接的数据集。
-
要将联接的表添加到数据流,可选择添加。
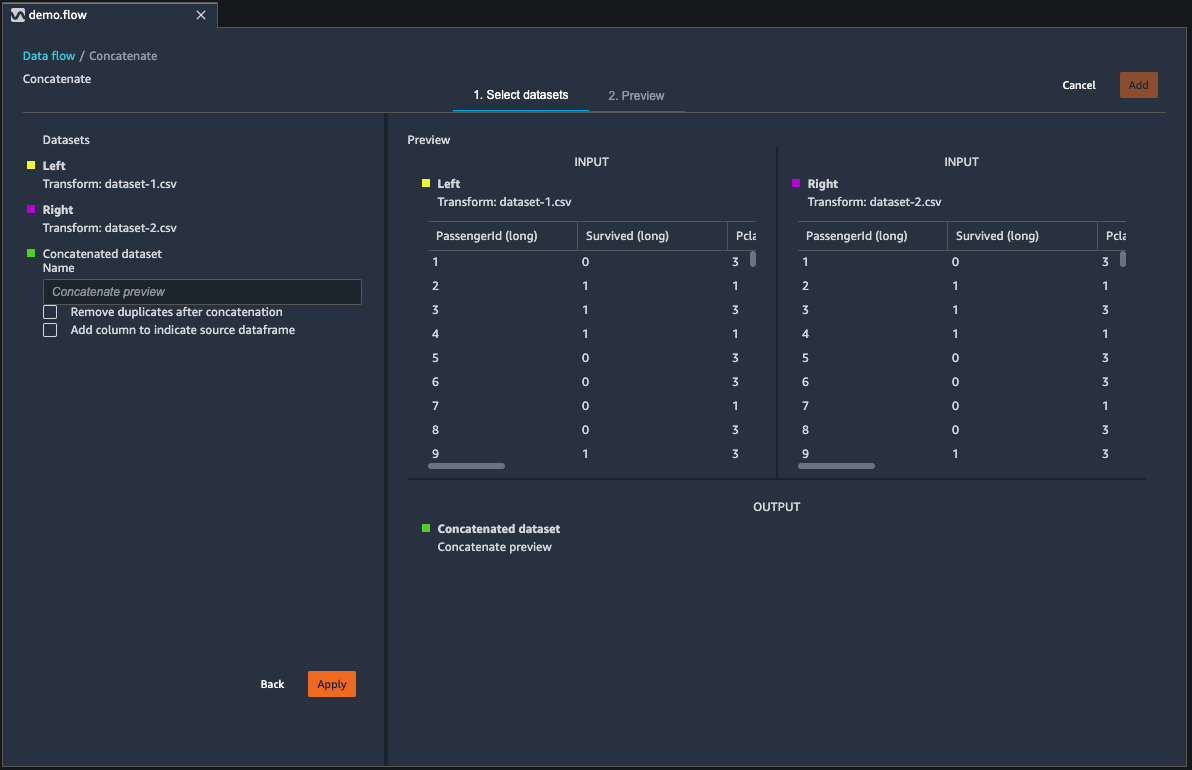
串联数据集
串联两个数据集:
-
选择要串联的左数据框旁边的 +。您选择的第一个数据框始终是串联中的左表。
-
选择串联。
-
选择右数据框。您选择的第二个数据框始终是串联中的右表。
-
选择配置以配置您的串联。
-
使用名称字段,为串联的数据集命名。
-
(可选)选中串联后删除重复项旁边的复选框,以删除重复的列。
-
(可选)如果您希望为新数据集中的每一列添加列源指示器,可选中添加列以指示源数据框旁边的复选框。
-
选择应用,预览新数据集。
-
选择添加,将新数据集添加到数据流中。
平衡数据
对于具代表不足的类别的数据集,您可以平衡其数据。平衡数据集有助于创建更好的二进制分类模型。
注意
包含列向量的数据集无法平衡。
您可以通过平衡数据操作,使用以下运算符之一来平衡数据:
-
随机过采样 – 在少数类别中随机重复样本。例如,如果您尝试检测欺诈行为,但可能只有 10% 的数据存在欺诈案例。为使欺诈案例和非欺诈案例达到同等比例,此运算符将数据集中的欺诈案例随机重复 8 次。
-
随机欠采样 – 大致等同于随机过采样。从过度代表的类别中随机删除样本,以获得您所需的样本比例。
-
合成少数过采样技术 (SMOTE) – 使用代表不足的类别中的样本,插入新的合成少数样本。有关 SMOTE 的更多信息,请参阅以下说明。
对于包含数字和非数字特征的数据集,可以使用所有转换。SMOTE 通过使用相邻样本插入值。Data Wrangler 使用 R-squared 距离来确定邻域来插值其他样本。Data Wrangler 仅使用数字特征来计算代表不足的组中样本之间的距离。
对于代表不足的组中的两个实际样本,Data Wrangler 使用加权平均值插入数字特征。它会为 [0, 1] 范围内的样本随机分配权重。对于数字特征,Data Wrangler 使用样本的加权平均值来插入样本。对于样本 A 和 B,Data Wrangler 可能随机为 A 分配 0.7 的权重,为 B 分配 0.3。插入的样本值为 0.7A + 0.3B。
Data Wrangler 通过复制插入的任一实际样本,插入非数字特征。它按照随机分配给每个样本的概率复制样本。对于样本 A 和 B,它可能为 A 分配概率 0.8,为 B 分配 0.2。按照它所分配的概率,80% 的时间会复制 A。
自定义转换
自定义变换组允许您使用 Python(User-Defined 函数) PySpark、pandas 或 PySpark (SQL) 来定义自定义转换。对于所有三个选项,可以使用变量 df 访问要应用转换的数据框。要将自定义代码应用于数据框,可将已进行转换的数据框分配给 df 变量。如果你不使用 Python(User-Defined 函数),则无需包含返回语句。可选择预览,预览自定义转换的结果。可选择添加,将自定义转换添加到先前的步骤列表中。
您可以在自定义转换代码块中,使用 import 语句导入常用的库,如下所示:
-
NumPy 版本 1.19.0
-
scikit-learn 版本 0.23.2
-
SciPy 版本 1.5.4
-
pandas 版本 1.0.3
-
PySpark 版本 3.0.0
重要
自定义转换不支持名称中包含空格或特殊字符的列。我们建议您指定仅包含字母数字字符和下划线的列名。您可以使用管理列转换组中的重命名列转换,从列名中删除空格。您也可以添加类似如下所示的 Python (Pandas) 自定义转换,在单个步骤中删除多列的空格。以下示例将名为 A
column 和 B column 的列分别更名为 A_column 和 B_column。
df.rename(columns={"A column": "A_column", "B column": "B_column"})
如果在代码块中包含打印语句,那么当您选择预览时会显示结果。您可以调整自定义代码转换器面板的大小。调整面板大小可为编写代码提供更多空间。下图显示了如何调整面板大小。
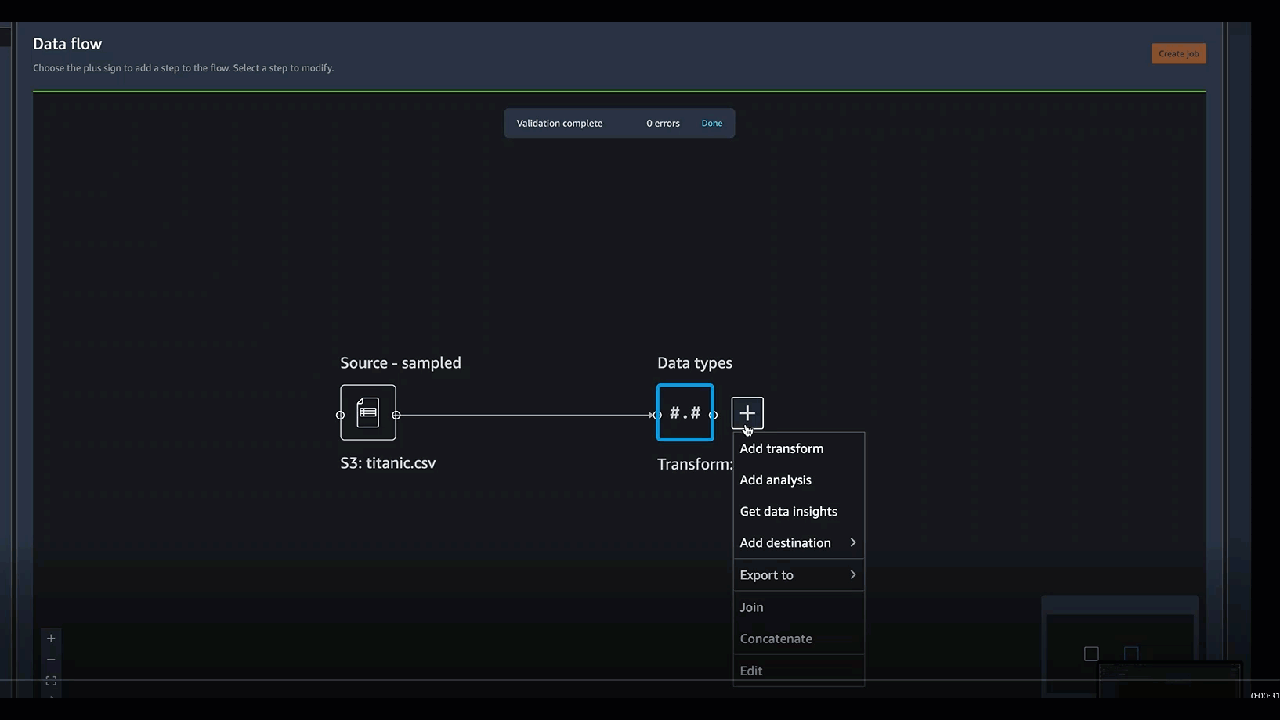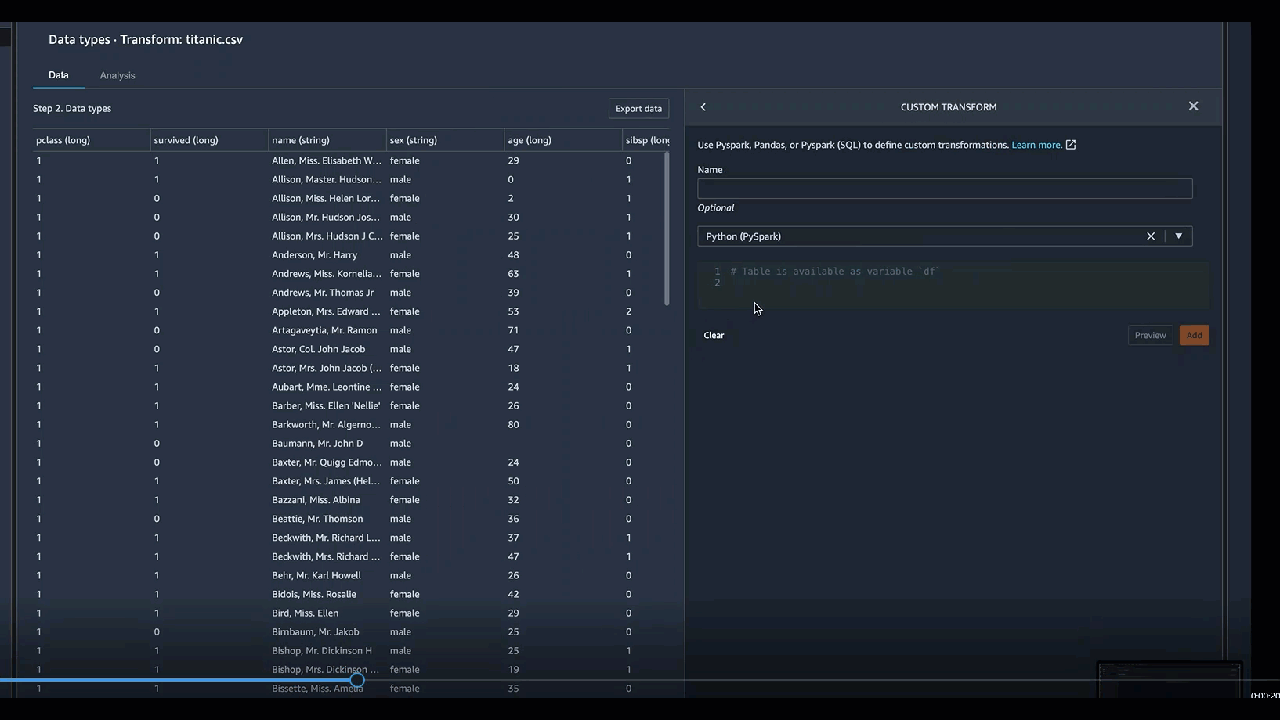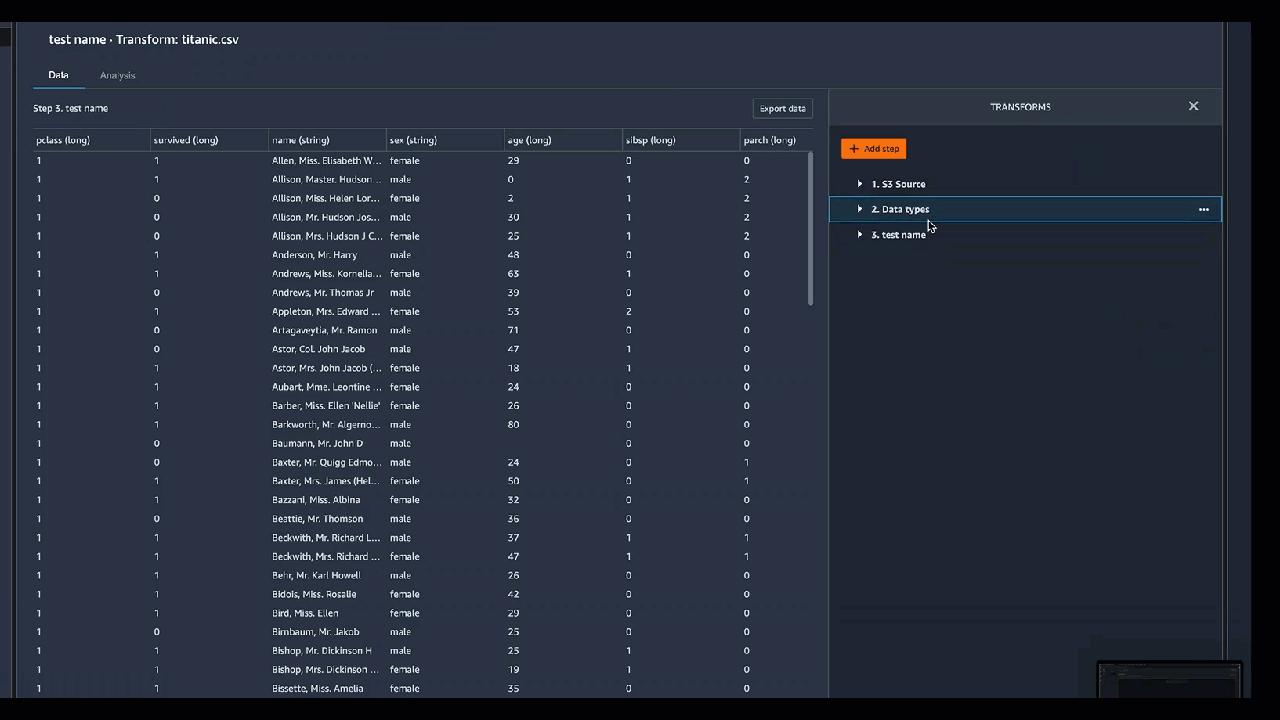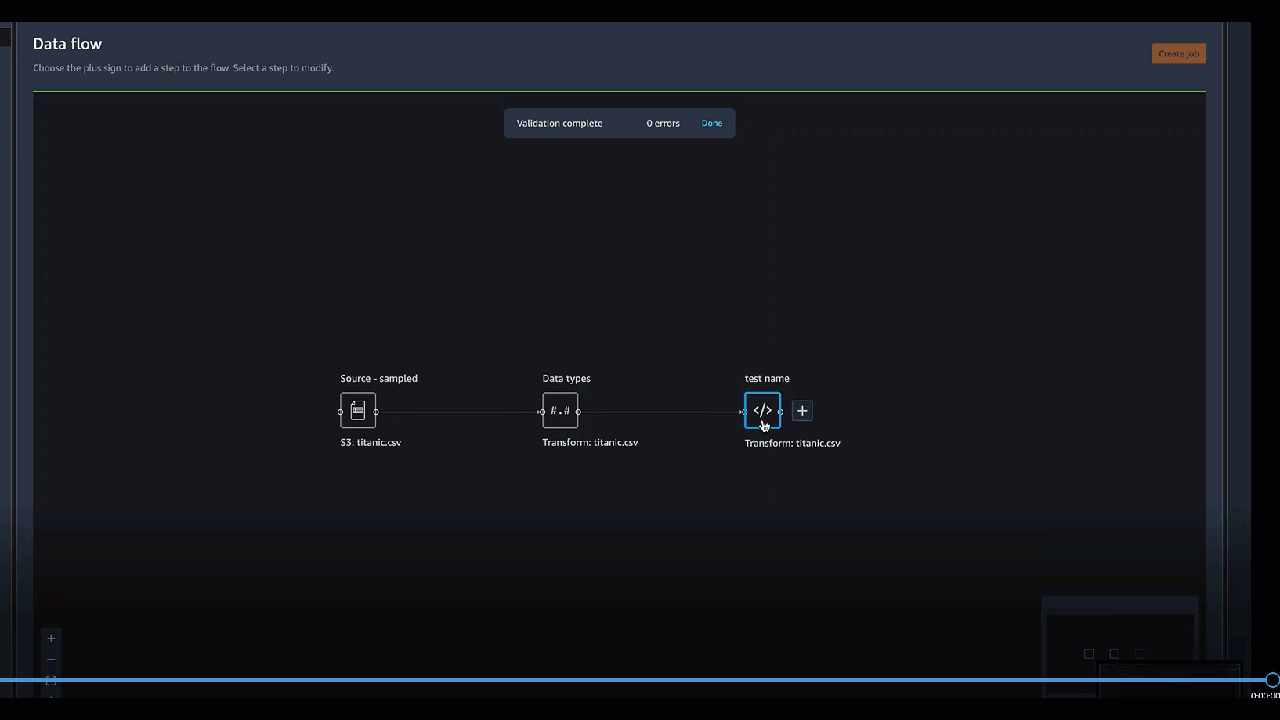
以下各部分提供了更多上下文和示例,以便您编写自定义转换代码。
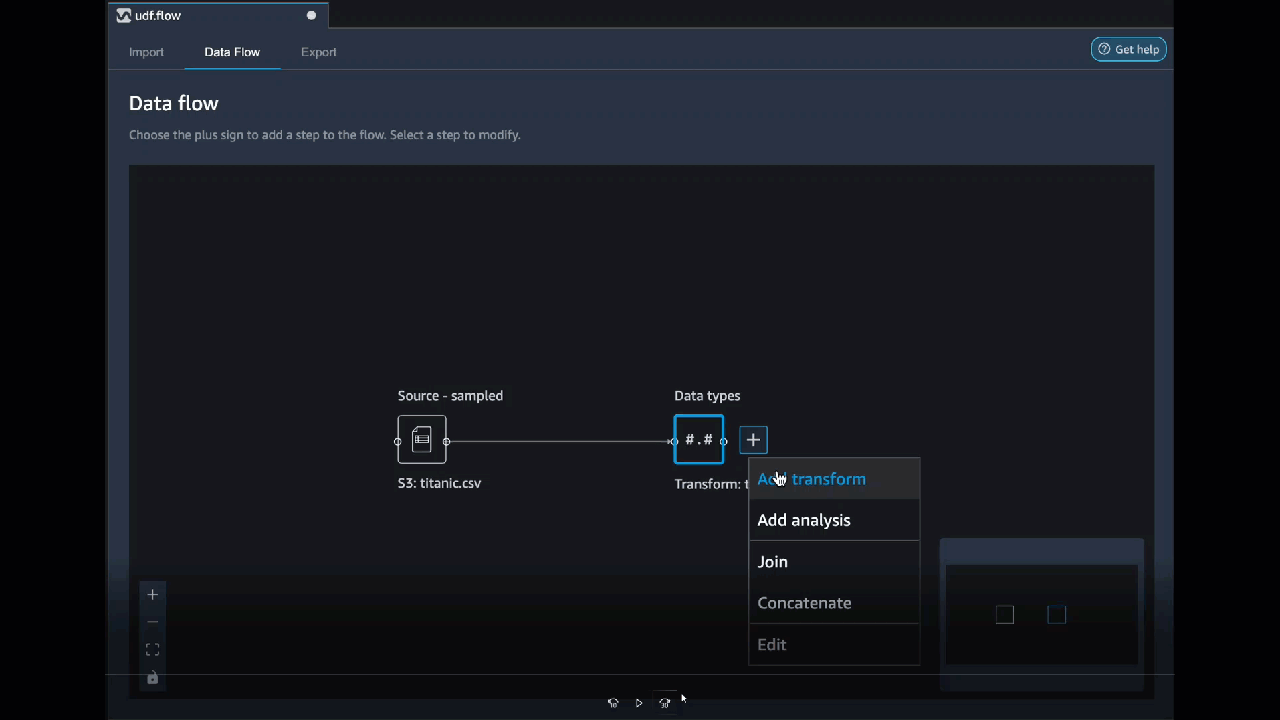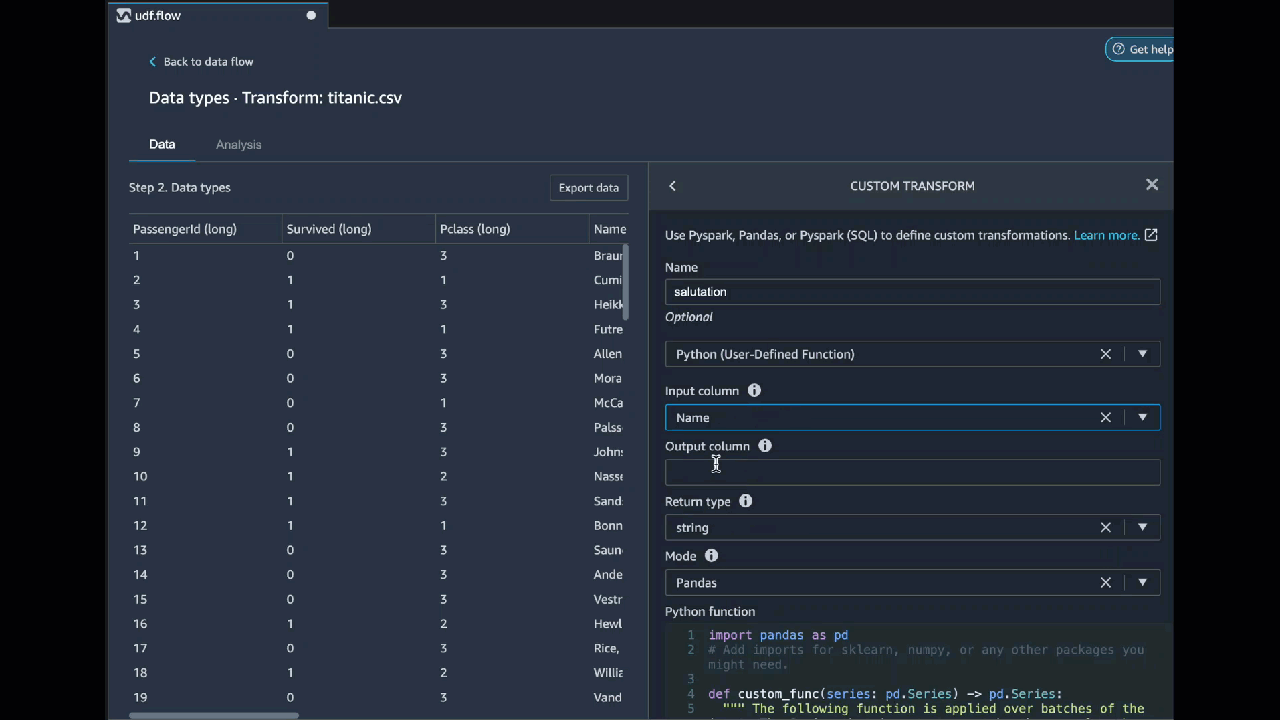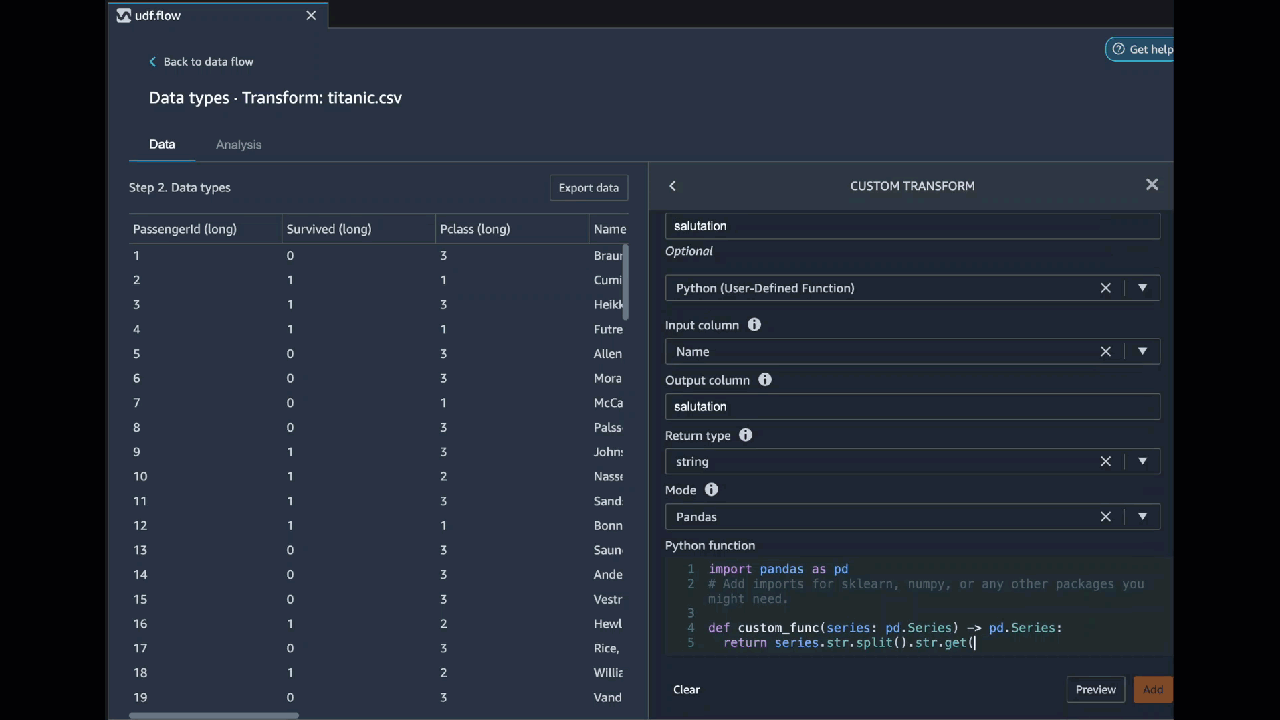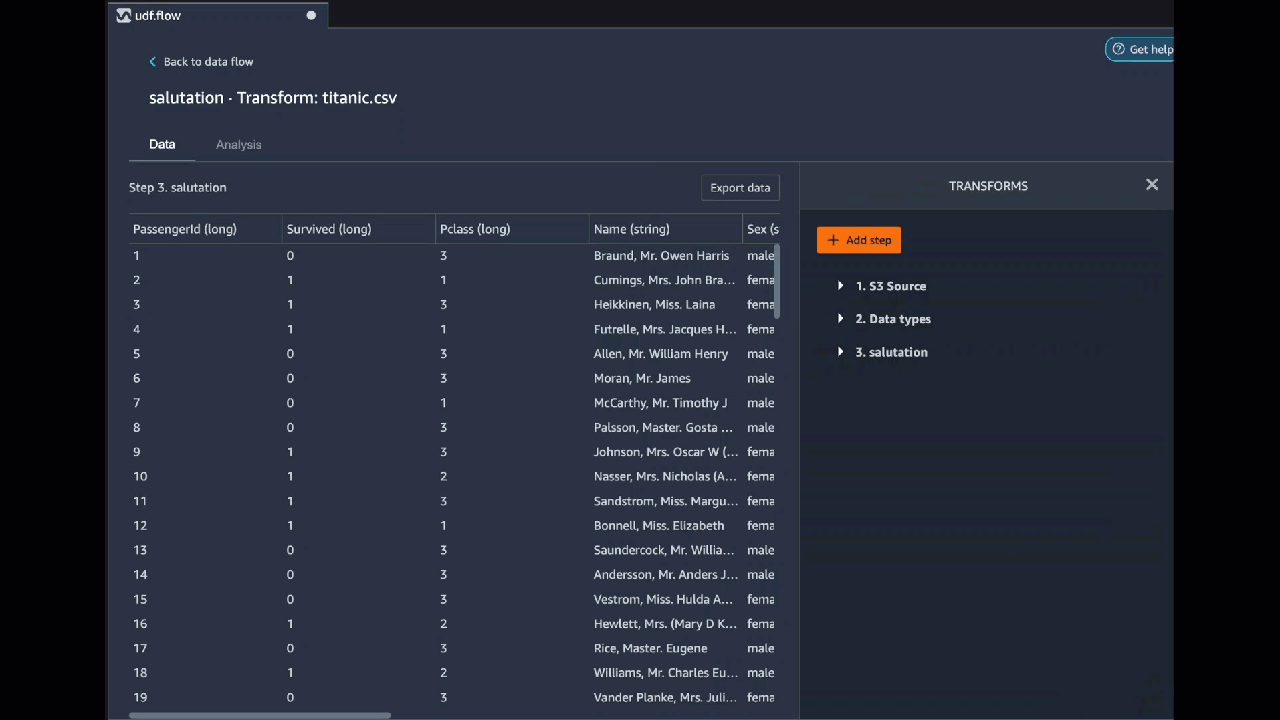
Python(User-Defined 函数)
借助 Python 函数,您无需了解 Apache Spark 或 pandas,即可编写自定义转换。Data Wrangler 经过优化,可快速运行您的自定义代码。通过使用自定义 Python 代码和 Apache Spark 插件,您可以获得类似的性能。
要使用 Python(User-Defined 函数)代码块,请指定以下内容:
-
输入列 – 您要应用转换的输入列。
-
模式 – 脚本模式,可以是 pandas 或 Python。
-
返回类型 – 您要返回的值的数据类型。
使用 pandas 模式可以获得更好的性能。Python 模式更便于您使用纯 Python 函数编写转换。
以下视频显示了如何使用自定义代码创建转换的示例。此示例使用 Titanic 数据集
PySpark
以下示例从时间戳中提取日期和时间。
from pyspark.sql.functions import from_unixtime, to_date, date_format df = df.withColumn('DATE_TIME', from_unixtime('TIMESTAMP')) df = df.withColumn( 'EVENT_DATE', to_date('DATE_TIME')).withColumn( 'EVENT_TIME', date_format('DATE_TIME', 'HH:mm:ss'))
pandas
以下示例提供要向其添加转换的数据框的概述。
df.info()
PySpark (SQL)
以下示例创建一个包含四列的新数据框:name、fare、pclass、survived。
SELECT name, fare, pclass, survived FROM df
如果您不知道如何使用 PySpark,则可以使用自定义代码片段来帮助您入门。
Data Wrangler 有一个可搜索的代码片段集合。您可以使用代码片段执行多种任务,例如删除列、按列分组或建模。
要使用代码片段,可选择搜索示例代码片段,然后在搜索栏中指定查询。您在查询中指定的文本不需要与代码片段的名称完全匹配。
以下示例显示了删除重复行代码片段,该代码片段可以删除数据集中具有相似数据的行。您可以通过搜索以下文本之一,查找该代码片段:
-
重复
-
相同
-
删除
以下代码片段包含注释,有助于您了解需要进行哪些更改。对于大多数代码片段,您必须在代码中指定数据集的列名。
# Specify the subset of columns # all rows having identical values in these columns will be dropped subset = ["col1", "col2", "col3"] df = df.dropDuplicates(subset) # to drop the full-duplicate rows run # df = df.dropDuplicates()
要使用代码片段,请将其内容复制并粘贴到自定义转换字段中。您可以将多个代码片段复制并粘贴到自定义转换字段中。
自定义公式
通过自定义公式,可使用 Spark SQL 表达式定义新列,以查询当前数据框中的数据。查询必须使用 Spark SQL 表达式的约定。
重要
自定义转换不支持名称中包含空格或特殊字符的列。我们建议您指定仅包含字母数字字符和下划线的列名。您可以使用管理列转换组中的重命名列转换,从列名中删除空格。您也可以添加类似如下所示的 Python (Pandas) 自定义转换,在单个步骤中删除多列的空格。以下示例将名为 A
column 和 B column 的列分别更名为 A_column 和 B_column。
df.rename(columns={"A column": "A_column", "B column": "B_column"})
您可以使用此转换对列执行操作,按名称引用列。例如,假设当前数据框包含名为 col_a 和 col_b 的列,您可以使用以下操作生成输出列,该列是上述两列的乘积,代码如下:
col_a * col_b
其他常见操作包括以下操作(假设数据框包含 col_a 和 col_b 列):
-
串联两列:
concat(col_a, col_b) -
两列相加:
col_a + col_b -
两列相减:
col_a - col_b -
两列相除:
col_a / col_b -
取一列的绝对值:
abs(col_a)
有关更多信息,请参阅关于选择数据的 Spark 文档
降低数据集中的维度
可使用主成分分析 (PCA) 降低数据的维度。数据集的维度与特征的数量相对应。如果您在 Data Wrangler 中使用降维,您会得到一组名为“成分”的新特征。每个成分在数据中占一定的可变性。
第一个成分在数据中占最大的变化量。第二个成分在数据中占第二大的变化量,以此类推。
您可以使用降维,减小用于训练模型的数据集大小。您可以使用主成分,替代数据集中的特征。
为了执行 PCA,Data Wrangler 会为数据创建轴。轴是数据集中列的仿射组合。第一个主成分即轴上变化量最大的值。第二个主成分即轴上变化量第二大的值。第 n 个主成分即轴上变化量第 n 大的值。
您可以配置 Data Wrangler 返回的主成得分量。您可以直接指定主成分的数量,也可以指定变化阈值百分比。每个主成分都解释了数据中的变化量。例如,您可能有一个值为 0.5 的主成分。该成分可解释数据中 50% 的变化。如果您指定变化阈值百分比,Data Wrangler 会返回符合所指定百分比的最小数量的成分。
以下示例为各个主成分及其在数据中解释的变化量。
-
成分 1 – 0.5
-
成分 2 – 0.45
-
成分 3 – 0.05
如果将变化阈值百分比指定为 94 或 95,则 Data Wrangler 将返回成分 1 和成分 2。如果将变化阈值百分比指定为 96,则 Data Wrangler 将返回全部三个主成分。
您可以使用以下过程,对数据集运行 PCA。
要对数据集运行 PCA,请执行以下操作。
-
打开 Data Wrangler 数据流。
-
选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择降维。
-
对于输入列,选择要简化为主成分的特征。
-
(可选)对于主成得分量,选择 Data Wrangler 在数据集中返回的主成得分量。如果为该字段指定值,那么无法为变化阈值百分比指定值。
-
(可选)对于变化阈值百分比,指定希望主成分可解释的数据变化百分比。如果没有为变化阈值指定值,Data Wrangler 将使用默认值
95。如果已经为主成得分量指定了值,那么无法指定变化阈值百分比。 -
(可选)取消选择居中,不使用列的平均值作为数据的中心。默认情况下,Data Wrangler 在缩放之前采用平均值将数据居中。
-
(可选)取消选择缩放,不按单位标准差缩放数据。
-
(可选)选择列,将成分输出到单独的列。选择向量,将成分输出为单个向量。
-
(可选)对于输出列,指定输出列的名称。如果要将成分输出到单独的列,则指定的名称为前缀。如果要将成分输出到向量,则指定的名称为向量列的名称。
-
(可选)选择保留输入列。如果您计划仅使用主成分来训练模型,我们不建议您选择此选项。
-
选择预览。
-
选择添加。
对分类数据进行编码
分类数据通常由有限数量的类别组成,其中每个类别用字符串表示。例如,如果您有客户数据表,则表明某人居住的国家/地区的列即为分类数据。类别有 Afghanistan、Albania、Algeria 等等。分类数据可以是标称的或有序的。有序类别有固有的次序,标称类别则没有。获得的最高学位(High school、Bachelors、Masters 等)即有序类别的一个示例。
对分类数据进行编码是为类别创建数字表示形式的过程。例如,如果你的分类是 Dog 和 Cat,则可以将此信息编码为两个向量:[1,0] 表示 Dog,[0,1] 表示 Cat。
对有序类别进行编码时,可能需要将类别的自然顺序转换为编码。例如,您可以采用以下映射表示获得的最高学位:{"High school": 1, "Bachelors": 2,
"Masters":3}。
可使用分类编码,将字符串格式的分类数据编码为整数数组。
Data Wrangler 分类编码器会在定义步骤时,为列中存在的所有类别创建编码。如果在时间 t,您启动 Data Wrangler 作业以处理数据集时,列中添加了新的类别,并且此列在时间 t-1 是 Data Wrangler 分类编码转换的输入,那么这些新类别在 Data Wrangler 中将被视为缺失。您为无效值处理策略所选择的选项将应用于这些缺失值。何时会发生此类情况的示例如下:
-
当您使用 .flow 文件创建 Data Wrangler 作业以处理数据集,而此数据集在数据流创建后更新了的时候。例如,您可能使用数据流每月定期处理销售数据。如果销售数据每周更新一次,对于已定义编码分类步骤的列,可能会有新的类别引入该列中。
-
当您在导入数据集时选择采样,某些类别可能被排除在样本之外的时候。
在上述情况中,这些新的类别在 Data Wrangler 作业中被视为缺失值。
您可以选择有序的或独热编码,并进行配置。可通过以下部分了解有关这些选项的更多信息。
两种转换均创建一个名为输出列的新列。可以使用输出样式,指定此列的输出格式:
-
选择向量,生成包含稀疏向量的单列。
-
选择列,为每个类别创建一列,其中包含一个指示器变量,用于指示原始列中的文本是否包含等于该类别的值。
有序编码
选择有序编码,将类别编码为介于 0 到所选输入列中类别总数之间的整数。
无效值处理策略:选择处理无效值或缺失值的方法。
-
如果您希望忽略含缺失值的行,可选择跳过。
-
选择保留,将缺失值保留为最后一个类别。
-
如果您希望当输入列中遇到缺失值时,Data Wrangler 引发错误,可选择错误。
-
选择替换为 NaN,用 NaN 替换缺失值。如果机器学习算法可以处理缺失值,我们建议使用此选项。否则,此列表中的前三个选项可能会产生更好的结果。
One-Hot 编码
为 “转换” 选择 “One-hot 编码” 以使用单热编码。可通过以下选项配置此转换:
-
删除最后一个类别:如果为
True,则最后一个类别在独热编码中没有相应的索引。当可能存在缺失值时,缺失的类别始终是最后一个,将此选项设置为True意味着缺失值会导致全零向量。 -
无效值处理策略:选择处理无效值或缺失值的方法。
-
如果您希望忽略含缺失值的行,可选择跳过。
-
选择保留,将缺失值保留为最后一个类别。
-
如果您希望当输入列中遇到缺失值时,Data Wrangler 引发错误,可选择错误。
-
-
输入是否为有序编码:如果输入向量包含有序编码的数据,可选择此选项。此选项要求输入数据包含非负整数。如果为真,则输入 i 被编码为在第 i 个位置非零的向量。
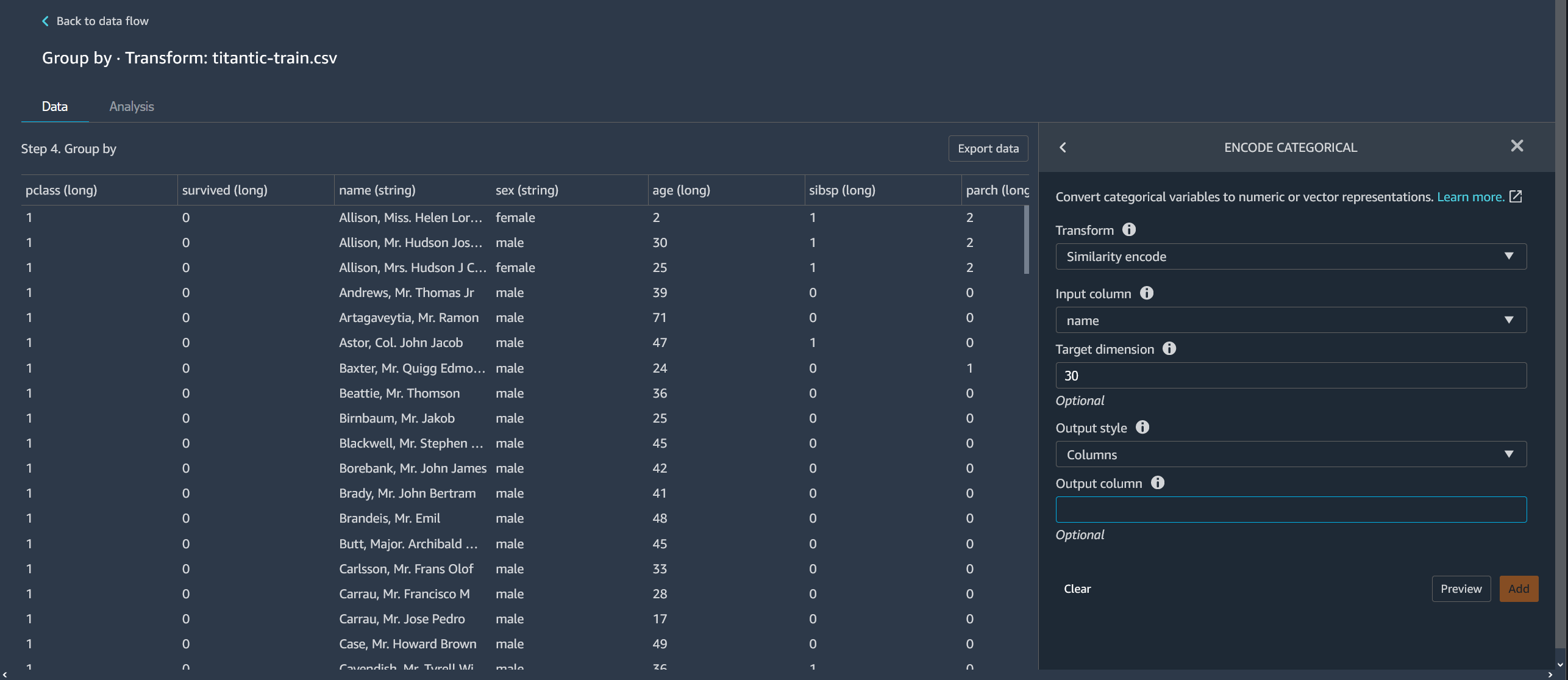
相似性编码
如果您有以下数据,则可使用相似性编码:
-
大量分类变量
-
噪声数据
相似性编码器为包含分类数据的列创建嵌入。嵌入即从离散对象(如单词)到实数向量的映射。该编码器将类似的字符串编码为包含相似值的向量。例如,为“California”和“Calfornia”创建极为相似的编码。
Data Wrangler 使用 3-gram 分词器将数据集中的每个类别转换为一组令牌。该编码器使用最小哈希编码将令牌转换为嵌入。
以下示例显示了相似性编码器如何从字符串创建向量。
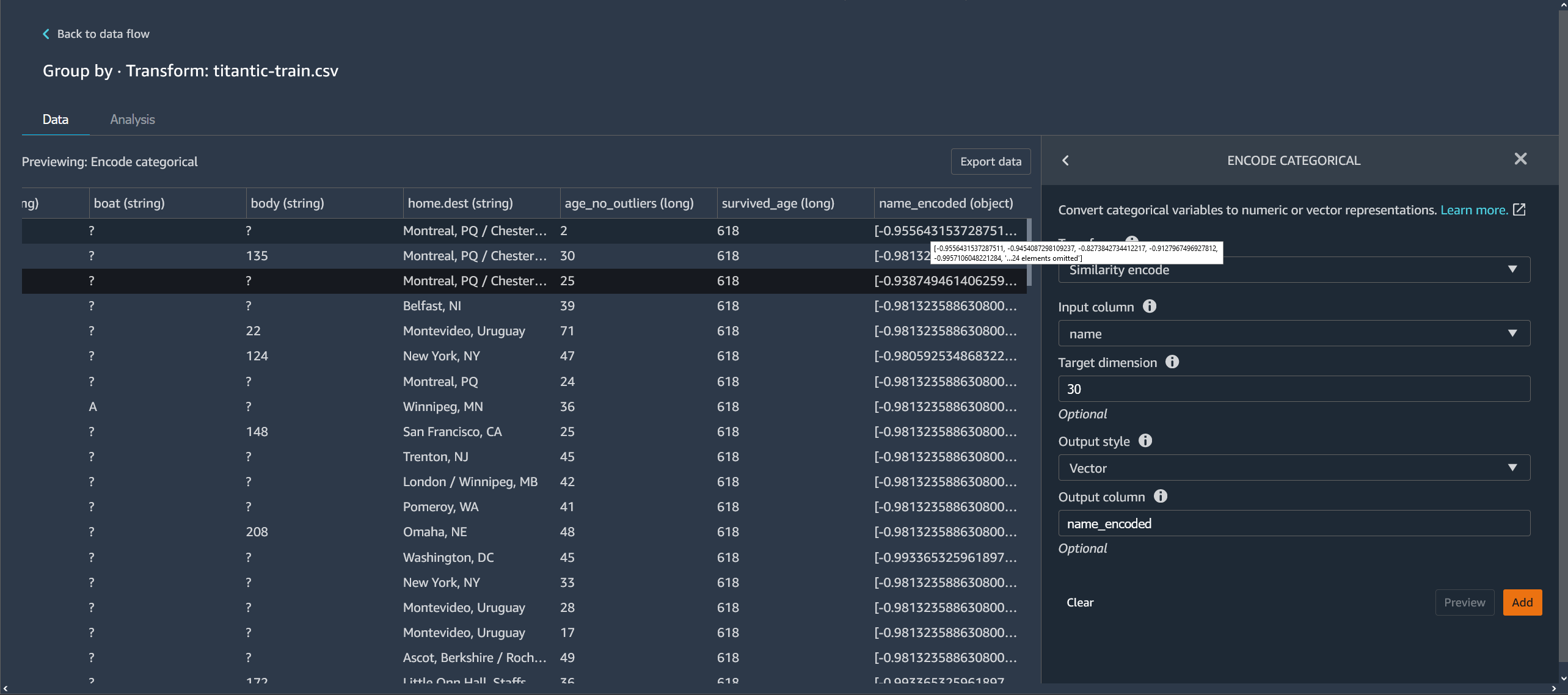
Data Wrangler 创建的相似性编码:
-
具有较低维度
-
可扩展到大量类别
-
稳健且耐噪声
出于上述原因,相似性编码比独热编码更为通用。
要将相似性编码转换添加到数据集中,请按以下过程操作。
要使用相似性编码,请执行以下操作。
-
选择打开 Studio Classic。
-
选择启动应用程序。
-
选择 Studio。
-
指定数据流。
-
选择有转换的步骤。
-
选择添加步骤。
-
选择对分类数据进行编码。
-
指定以下内容:
-
转换 – 相似性编码
-
输入列 – 包含要编码的分类数据的列。
-
目标维度 –(可选)分类嵌入向量的维度。默认值为 30。如果您的大型数据集包含许多类别,我们建议使用较大的目标维度。
-
输出样式 – 选择向量,在单个向量中包含所有编码的值。选择列,将编码的值放在单独的列中。
-
输出列 –(可选)对于向量编码的输出,为输出列的名称。对于列编码的输出,为列名称的前缀,后跟列出的数字。
-
特征化文本
可使用特征化文本转换组,检查字符串类型的列,并使用文本嵌入对这些列特征化。
此特征组包含两个特征:字符统计和向量化。可通过以下部分了解有关这些转换的更多信息。对于这两个选项,输入列必须包含文本数据(字符串类型)。
字符统计
可使用字符统计,为包含文本数据的列中的每一行生成统计信息。
此转换将为每一行计算以下比率和计数,并创建新的列以报告结果。该新列采用输入列名称作为前缀,以及特定于比率或计数的后缀来命名。
-
字数:该行中单词的总数。此输出列的后缀为
-stats_word_count。 -
字符数:该行中字符的总数。此输出列的后缀为
-stats_char_count。 -
大写比率:从 A 到 Z 的大写字符数除以列中的所有字符数。此输出列的后缀为
-stats_capital_ratio。 -
小写比率:从 a 到 z 的小写字符数除以列中的所有字符数。此输出列的后缀为
-stats_lower_ratio。 -
数字比率:单行中的数字与输入列中数字总和的比率。此输出列的后缀为
-stats_digit_ratio。 -
特殊字符比率:非字母数字字符(如 #$&%:@)与输入列中所有字符总和的比率。此输出列的后缀为
-stats_special_ratio。
向量化
文本嵌入涉及将词汇表中的单词或短语映射到实数向量。使用 Data Wrangler 文本嵌入变换将文本数据标记并矢量化为术语频率——反向文档频率 () 向量。TF-IDF
TF-IDF 当计算一列文本数据时,每个句子中的每个单词都将转换为表示其语义重要性的实数。数字越高,与之关联的单词出现频率越低,这些单词往往更有意义。
在定义矢量化变换步骤时,Data Wrangler 会使用数据集中的数据来定义计数向量器和方法。 TF-IDF 运行 Data Wrangler 作业时会使用相同的方法。
您可以使用以下选项配置此转换:
-
输出列名:此转换将创建包含文本嵌入的新列。此字段可用于指定此输出列的名称。
-
分词器:分词器将句子转换为单词或令牌列表。
可选择标准,使用按空格拆分单词并将每个单词转换为小写的分词器。例如,
"Good dog"被令牌化为["good","dog"]。可选择自定义,使用自定义的分词器。如果选择自定义,则可使用以下字段来配置分词器:
-
最小令牌长度:令牌有效的最小长度(以字符为单位)。默认值为
1。例如,如果将最小令牌长度指定为3,那么诸如a, at, in等单词将从令牌化句子中删除。 -
正则表达式是否按间隔拆分:如果选中,则正则表达式按间隔拆分。否则,将与令牌匹配。默认值为
True。 -
正则表达式模式:定义令牌化过程的正则表达式模式。默认值为
' \\ s+'。 -
转换为小写:如果选中,则 Data Wrangler 在令牌化之前将所有字符转换为小写。默认值为
True。
要了解更多信息,请参阅有关分词器
的 Spark 文档。 -
-
向量器:向量器将令牌列表转换为稀疏数字向量。每个令牌对应于向量中的索引,非零表示输入句子中存在该令牌。您可以从两个向量器选项中进行选择:计数和哈希。
-
计数向量化允许自定义筛选不常见或太常见的令牌。计数向量化参数包括以下选项:
-
最低词频:在每一行中,筛选掉频率较低的词(令牌)。如果指定一个整数,那么该值为绝对阈值(含该值)。如果指定一个介于 0(含)到 1 之间的得分,那么阈值是总词数的相对值。默认值为
1。 -
最小文档频率:必须包含词(令牌)的最小行数。如果指定一个整数,那么该值为绝对阈值(含该值)。如果指定一个介于 0(含)到 1 之间的得分,那么阈值是总词数的相对值。默认值为
1。 -
最大文档频率:可以包含词(令牌)的最大文档(行)数。如果指定一个整数,那么该值为绝对阈值(含该值)。如果指定一个介于 0(含)到 1 之间的得分,那么阈值是总词数的相对值。默认值为
0.999。 -
最大词汇量:词汇表的最大大小。词汇表由列所有行中的所有词(令牌)组成。默认值为
262144。 -
二进制输出:如果选中,则向量输出不包括词在文档中的出现次数,而是词是否出现的二进制指示器。默认值为
False。
要了解有关此选项的更多信息,请参阅上的 Spark 文档CountVectorizer
。 -
-
哈希计算速度更快。哈希向量化参数包括以下选项:
-
哈希过程中的特征数:哈希向量器根据令牌的哈希值,将令牌映射到向量索引。此特征决定了可能的哈希值的数量。较大的值会减少哈希值之间的冲突,但会导致较高的维度输出向量。
要了解有关此选项的更多信息,请参阅上的 Spark 文档 FeatureHasher
-
-
-
应用 IDF 会应用 IDF 变换,该变换将术语频率乘以用于 TF-IDF 嵌入的标准反向文档频率。IDF 参数包括以下选项:
-
最小文档频率:必须包含词(令牌)的最小文档(行)数。如果 count _vectorize 是选择的向量器,我们建议您保留默认值,只修改计数向量化参数中的 min_doc_freq 字段。默认值为
5。
-
-
输出格式:每行的输出格式。
-
选择向量,生成包含稀疏向量的单列。
-
选择展平,为每个类别创建一列,其中包含一个指示器变量,以指示原始列中的文本是否包含与该类别相等的值。如果向量器设置为计数向量器,那么只能选择展平。
-
转换时间序列
在 Data Wrangler 中,您可以转换时间序列数据。时间序列数据集中的值按特定时间编制索引。例如,显示一天中每小时商店中的顾客数量的数据集,即时间序列数据集。下表显示了时间序列数据集示例。
商店中每小时的顾客数
| 顾客数 | 时间(小时) |
|---|---|
| 4 | 09:00 |
| 10 | 10:00 |
| 14 | 11:00 |
| 25 | 12:00 |
| 20 | 13:00 |
| 18 | 14:00 |
对于上表,顾客数列中包含时间序列数据。时间序列数据根据时间(小时)列中的每小时数据编制索引。
您可能需要对数据执行一系列转换,才能获得可用于分析的格式。可使用时间序列转换组,对时间序列数据进行转换。有关可执行的转换的详细信息,请参阅以下各节。
主题
按时间序列分组
您可以使用按操作分组,对列中特定值的时间序列数据进行分组。
例如,您通过下表跟踪住户的平均每日用电量:
平均每日住户用电量
| 住户 ID | 每日时间戳 | 用电量 (kWh) | 住户人数 |
|---|---|---|---|
| household_0 | 1/1/2020 | 30 | 2 |
| household_0 | 1/2/2020 | 40 | 2 |
| household_0 | 1/4/2020 | 35 | 3 |
| household_1 | 1/2/2020 | 45 | 3 |
| household_1 | 1/3/2020 | 55 | 4 |
如果您选择按 ID 分组,则可获得下表。
按住户 ID 分组的用电量
| 住户 ID | 用电量序列 (kWh) | 住户人数序列 |
|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] |
| household_1 | [45, 55] | [3, 4] |
时间序列中的每一项按照相应的时间戳排序。序列的第一个元素对应于该序列的第一个时间戳。对于 household_0,30 是用电量序列的第一个值。值 30 对应于第一个时间戳 1/1/2020。
您可以将开始时间戳和结束时间戳包括在内。下表显示了这些信息的显示方式。
按住户 ID 分组的用电量
| 住户 ID | 用电量序列 (kWh) | 住户人数序列 | Start_time | End_time |
|---|---|---|---|---|
| household_0 | [30, 40, 35] | [2, 2, 3] | 1/1/2020 | 1/4/2020 |
| household_1 | [45, 55] | [3, 4] | 1/2/2020 | 1/3/2020 |
您可以使用以下过程,按时间序列列进行分组。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择时间序列。
-
在转换下,选择分组依据。
-
在按此列分组中,指定一列。
-
对于应用于列,指定一个值。
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
重新采样时间序列数据
时间序列数据中通常包含并非定期取得的观测值。例如,数据集中某些观测值是每小时记录的,而其他一些观测值是每两小时记录的。
许多分析(如预测算法)需要定期取得的观测值。您可以通过重新采样,为数据集中的观测值建立定期间隔。
您可以对时间序列进行上采样或下采样。下采样会延长数据集中观测值之间的间隔。例如,如果对每小时或每两小时记录的观测值进行下采样,那么数据集中的每个观测值将每两小时记录一次。对于每小时观测值,将使用聚合方法(如平均值或中位数)聚合为单个值。
上采样则会缩短数据集中观测值之间的间隔。例如,如果将每两小时记录一次的观测值上采样为每小时观测值,那么可以使用插值方法,从每两小时取得的观测值中推断出每小时观测值。有关插值方法的信息,请参阅 pandas。 DataFrame.interpolate
您可以对数字数据和非数字数据重新采样。
可使用重新采样操作,对时间序列数据重新采样。如果数据集中有多个时间序列,Data Wrangler 会标准化每个时间序列的时间间隔。
下表显示了使用平均值聚合方法对时间序列数据进行下采样的示例。数据采样从每两小时一次降到每小时一次。
下采样前一天的每小时温度读数
| Timestamp | 温度(摄氏度) |
|---|---|
| 12:00 | 30 |
| 1:00 | 32 |
| 2:00 | 35 |
| 3:00 | 32 |
| 4:00 | 30 |
延长至每两小时的温度读数
| Timestamp | 温度(摄氏度) |
|---|---|
| 12:00 | 30 |
| 2:00 | 33.5 |
| 4:00 | 35 |
您可以使用以下过程,对时间序列数据重新采样。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择重新采样。
-
对于时间戳,选择时间戳列。
-
对于频率单位,指定要重新采样的频率。
-
(可选)指定频率数量值。
-
指定其余的字段配置转换。
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
处理缺失的时间序列数据
如果数据集中有缺失值,可执行以下操作之一:
-
对于具有多个时间序列的数据集,可删除其缺失值大于指定阈值的时间序列。
-
使用时间序列中的其他值,填补时间序列中的缺失值。
填补缺失值涉及通过指定值或使用推理方法来替换数据。以下是可用于填补的方法:
-
常量值 – 将数据集中所有缺失数据替换为指定值。
-
最常见的值 – 将所有缺失数据替换为数据集中出现频率最高的值。
-
向前填充 – 使用向前填充,将缺失值替换为缺失值前面的非缺失值。对于序列 [2, 4, 7, NaN, NaN, NaN, 8],所有缺失值将替换为 7。采用向前填充产生的序列为 [2, 4, 7, 7, 7, 7, 8]。
-
向后填充 – 使用向后填充,将缺失值替换为缺失值后面的非缺失值。对于序列 [2, 4, 7, NaN, NaN, NaN, 8],所有缺失值将替换为 8。采用向后填充产生的序列为 [2, 4, 7, 8, 8, 8, 8]。
-
插值 – 使用插值函数填补缺失值。有关可用于插值的函数的更多信息,请参阅 pandas。 DataFrame.interpolate
。
某些填补方法可能无法填补数据集中的所有缺失值。例如,向前填充无法填补出现在时间序列开头的缺失值。您可以使用向前填充或向后填充来填补值。
您可以填补单元格内或列中的缺失值。
以下示例显示了如何填补单元格内的值。
含缺失值的用电量
| 住户 ID | 用电量序列 (kWh) |
|---|---|
| household_0 | [30, 40, 35, NaN, NaN] |
| household_1 | [45, NaN, 55] |
采用向前填充填补值的用电量
| 住户 ID | 用电量序列 (kWh) |
|---|---|
| household_0 | [30, 40, 35, 35, 35] |
| household_1 | [45, 45, 55] |
以下示例显示了如何填补列中的值。
含缺失值的平均每日住户用电量
| 住户 ID | 用电量 (kWh) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | NaN |
| household_1 | NaN |
| household_1 | NaN |
采用向前填充填补值的平均每日住户用电量
| 住户 ID | 用电量 (kWh) |
|---|---|
| household_0 | 30 |
| household_0 | 40 |
| household_0 | 40 |
| household_1 | 40 |
| household_1 | 40 |
您可以使用以下过程,处理缺失值。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择处理缺失值。
-
对于时间序列输入类型,选择是按照单元格还是列,处理缺失值。
-
对于填补此列的缺失值,指定包含缺失值的列。
-
对于填补值的方法,选择一种方法。
-
指定其余的字段配置转换。
-
选择预览,生成转换的预览。
-
如果您有缺失值,那么可以在填补值的方法下,指定方法来填补缺失值。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
验证时间序列数据的时间戳
您可能有无效的时间戳数据。您可以使用验证时间戳函数,确定数据集中的时间戳是否有效。时间戳可能因以下一个或多个原因无效:
-
时间戳列包含缺失值。
-
时间戳列中的值格式不正确。
如果数据集中有无效的时间戳,则无法成功执行分析。您可以使用 Data Wrangler 来识别无效的时间戳,并了解需要在哪里清理数据。
时间序列验证按下面的两种方式之一运行:
可以配置 Data Wrangler,使之在数据集中遇到缺失值时执行以下操作之一:
-
删除含缺失值或无效值的行。
-
识别含缺失值或无效值的行。
-
如果在数据集中发现任何缺失值或无效值,则引发错误。
可以对包含 timestamp 类型或 string 类型的列,验证时间戳。如果列包含 string 类型,Data Wrangler 会将列的类型转换为 timestamp,然后执行验证。
您可以使用以下过程,验证数据集中的时间戳。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择验证时间戳。
-
对于时间戳列,选择时间戳列。
-
对于策略,选择是否要处理缺失的时间戳。
-
(可选)对于输出列,指定输出列的名称。
-
如果日期时间列的格式为字符串类型,可选择转为日期时间。
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
标准化时间序列的长度
如果将时间序列数据存储为数组,那么可以将每个时间序列标准化为相同的长度。通过标准化时间序列数组的长度,您或许能更轻松地执行数据分析。
对于需要固定数据长度的数据转换,您可以对时间序列进行标准化。
许多机器学习算法要求您在使用时间序列数据之前,对数据进行展平。展平时间序列数据是在数据集中,将时间序列的每个值分隔到自己的列中。数据集中的列数不能更改,因此需要在将每个数组展平为一组特征的过程中,对时间序列的长度进行标准化。
每个时间序列的长度可设置为指定的时间序列集的分位数或百分位数。例如,您可能拥有三个长度如下的序列:
-
3
-
4
-
5
您可以将所有序列的长度设置为长度为第 50 个百分位数的序列的长度。
小于指定长度的时间序列数组会添加缺失值。以下示例格式将时间序列标准化为更长的长度:[2, 4, 5, NaN, NaN, NaN]。
您可以使用不同的方法处理缺失值。有关这些方法的信息,请参阅处理缺失的时间序列数据。
大于指定长度的时间序列数组将被截断。
您可以使用以下过程,对时间序列的长度进行标准化。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择标准化长度。
-
对于为此列标准化时间序列长度,选择一列。
-
(可选)对于输出列,指定输出列的名称。如果未指定名称,则转换将就地完成。
-
如果日期时间列的格式为字符串类型,可选择转为日期时间。
-
选择截止分位数,指定一个分位数以设置序列的长度。
-
选择展平输出,将时间序列的值输出到单独的列中。
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
从时间序列数据中提取特征
如果对时间序列数据运行分类或回归算法,我们建议在运行算法之前,从时间序列中提取特征。提取特征可能会提高算法的性能。
可使用以下选项,选择要从数据中提取特征的方式:
-
使用最小子集,指定提取您认为在下游分析中有用的 8 个特征。如果需要快速执行计算,则可使用最小子集。如果机器学习算法有过度拟合的高风险,并且您希望为其提供较少的特征,那么也可以使用此方式。
-
使用高效子集,指定在不提取分析中计算密集型特征的情况下,尽可能提取最多的特征。
-
使用所有特征,指定从调整序列中提取所有特征。
-
使用手动子集,选择您认为可充分解释数据变化的特征列表。
可使用以下过程,从时间序列数据中提取特征。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择提取特征。
-
对于为此列提取特征,选择一列。
-
(可选)选择展平,将特征输出到单独的列中。
-
对于策略,选择提取特征的策略。
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
使用时间序列数据的滞后特征
对于许多使用案例来说,预测时间序列未来行为的最佳方法,是使用其最近的行为。
滞后特征最常见的用途如下:
-
收集少许过去的值。例如,对于时间 t + 1,收集 t、t - 1、t - 2 和 t - 3。
-
收集与数据中的周期性行为对应的值。例如,要预测下午 1:00 餐厅的上座率,您可能要使用前一天下午 1:00 的特征。如果使用当天中午 12:00 或上午 11:00 的特征,可能不像使用前几天的特征那样具有预测性。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择滞后特征。
-
对于为此列生成滞后特征,选择一列。
-
对于时间戳列,选择包含时间戳的列。
-
对于滞后,指定滞后的持续时间。
-
(可选)可使用以下选项之一配置输出:
-
包括整个滞后窗口
-
展平输出
-
删除无历史记录的行
-
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
在时间序列中创建日期时间范围
您可能有不含时间戳的时间序列数据。如果您知道观测值是定期取得的,那么可以在单独的列中为时间序列生成时间戳。要生成时间戳,请指定开始时间戳的值和时间戳的频率。
例如,您可能有以下时间序列数据,一家餐厅的顾客数量。
餐厅顾客数的时间序列数据
| 顾客数 |
|---|
| 10 |
| 14 |
| 24 |
| 40 |
| 30 |
| 20 |
如果您知道餐厅下午 5:00 开始营业,并且每小时记录一次观测值,那么可以添加与时间序列数据对应的时间戳列。您可以在下表中看到时间戳列。
餐厅顾客数的时间序列数据
| 顾客数 | Timestamp |
|---|---|
| 10 | 1:00 PM |
| 14 | 2:00 PM |
| 24 | 3:00 PM |
| 40 | 4:00 PM |
| 30 | 5:00 PM |
| 20 | 6:00 PM |
可使用以下过程,向数据添加日期时间范围。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择日期时间范围。
-
对于频率类型,选择用于衡量时间戳频率的单位。
-
对于开始时间戳,指定开始的时间戳。
-
对于输出列,指定输出列的名称。
-
(可选)使用其余的字段配置输出。
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
在时间序列中使用滚动窗口
您可以提取一段时间内的特征。例如,给定时间 t,时间窗口长度为 3,以及表示第 t 个时间戳的行,我们可追加时间 t - 3、t -2 和 t - 1 时从时间序列提取的特征。有关提取特征的信息,请参阅从时间序列数据中提取特征。
您可以使用以下过程,提取一段时间内的特征。
-
打开 Data Wrangler 数据流。
-
如果尚未导入数据集,在导入数据选项卡下进行导入。
-
在数据流中,在数据类型下,选择 +,然后选择添加转换。
-
选择添加步骤。
-
选择滚动窗口特征。
-
对于为此列生成滚动窗口特征,选择一列。
-
对于时间戳列,选择包含时间戳的列。
-
(可选)对于输出列,指定输出列的名称。
-
对于窗口大小中,指定窗口大小。
-
对于策略,选择提取策略。
-
选择预览,生成转换的预览。
-
选择添加,将转换添加到 Data Wrangler 数据流中。
特征化日期时间
使用 Featuriz date/time e 创建表示日期时间字段的矢量嵌入。要使用此转换,日期时间数据必须采用以下格式之一:
-
描述日期时间的字符串:例如,
"January 1st, 2020, 12:44pm"。 -
Unix 时间戳:Unix 时间戳描述了从 /19700 开始的秒数、毫秒数、微秒数或纳秒数。 1/1
您可以选择推断日期时间格式,或者提供日期时间格式。如果提供日期时间格式,则必须使用 Python 文档
-
手动程度最高且计算速度最快的选项是指定日期时间格式,并为推断日期时间格式选择否。
-
要减少手动工作量,可以选择推断日期时间格式,而不是指定日期时间格式。此操作的计算速度也很快,不过,此配置会假定在输入列中遇到的第一个日期时间格式是整个列的格式。如果列中还有其他格式,这些值在最终输出中会显示为 NaN。推断日期时间格式可为您提供未解析的字符串。
-
如果未指定格式,并且为推断日期时间格式选择了否,那么您会得到最稳健的结果。所有有效的日期时间字符串都将进行解析。但是,此操作可能会比列表中的前两个选项慢一个数量级。
使用此转换时,应指定包含上述格式之一的日期时间数据的输入列。转换会创建名为输出列名的输出列。输出列的格式取决于通过以下选项进行的配置:
-
向量:将单列输出为向量。
-
列:为每个特征创建新的列。例如,如果输出包含年、月和日,那么将会为年、月和日创建三个单独的列。
此外,必须选择嵌入模式。对于线性模型和深度网络,我们建议选择循环的。对于基于树的算法,我们建议选择有序的。
格式化字符串
格式化字符串转换包含标准的字符串格式化操作。例如,您可以使用这些操作删除特殊字符、规范化字符串长度以及更新字符串大小写。
此特征组包含以下转换。所有转换都将在输入列中返回字符串副本,然后将结果添加到新的输出列。
| Name | 函数 |
|---|---|
| 左侧填充 |
Left-pad 具有给定宽度的给定填充字符的字符串。如果字符串的长度超过宽度,则返回值将缩短至宽度字符。 |
| 右侧填充 |
Right-pad 具有给定宽度的给定填充字符的字符串。如果字符串的长度超过宽度,则返回值将缩短至宽度字符。 |
| 中心(两侧填充) |
Center-pad 带有给定宽度的给定填充字符的字符串(在字符串的两边添加填充)。如果字符串的长度超过宽度,则返回值将缩短至宽度字符。 |
| 前面加零 |
Left-fill 一个带零的数字字符串,宽度不超过给定的宽度。如果字符串的长度超过宽度,则返回值将缩短至宽度字符。 |
| 左右剥离 |
返回删除了前导字符和尾随字符的字符串副本。 |
| 左侧字符剥离 |
返回删除了前导字符的字符串副本。 |
| 右侧字符剥离 |
返回删除了尾随字符的字符串副本。 |
| 小写 |
将文本中的所有字母转换为小写。 |
| 大写 |
将文本中的所有字母转换为大写。 |
| 首字母大写 |
将每个句子的第一个字母大写。 |
| 交换大小写 | 将给定字符串的所有大写字符转换为小写,将所有小写字符转换为大写,然后返回。 |
| 添加前缀或后缀 |
为字符串列添加前缀和后缀。必须指定至少一个前缀和后缀。 |
| 删除符号 |
从字符串中删除给定符号。列出的所有字符都将删除。默认值为空格。 |
处理异常值
机器学习模型对特征值的分布和范围很敏感。异常值或稀有值可能会对模型准确性产生负面影响,并导致更长的训练时间。可使用此特征组,检测并更新数据集中的异常值。
在定义处理异常值转换步骤时,用于检测异常值的统计数据是在定义此步骤时,根据 Data Wrangler 中的可用数据生成的。运行 Data Wrangler 作业时,也会用到这些统计数据。
可通过以下部分,了解有关此组所包含的转换的更多信息。指定输出名称以及以下转换中的每一个,都会生成含结果数据的输出列。
稳健标准差数字异常值
此转换使用对异常值而言稳健的统计数据,检测并修复数字特征中的异常值。
您必须为用于计算异常值的统计数据,定义上分位数和下分位数。还必须指定一个标准差数,值必须偏离平均值此数额,才能被视为异常值。例如,如果指定标准差为 3,那么值必须偏离平均值 3 个标准差以上,才会被视为异常值。
修复方法是在检测到异常值后,用于处理异常值的方法。可从以下选项中进行选择:
-
裁剪:使用此选项可将异常值剪裁到相应的异常值检测边界。
-
删除:使用此选项可从数据框中删除含异常值的行。
-
失效:使用此选项可用无效值替换异常值。
标准差数字异常值
此转换使用平均值和标准差检测并修复数字特征中的异常值。
您可以指定一个标准差数,值必须偏离平均值此数额,才能被视为异常值。例如,如果指定标准差为 3,那么值必须偏离平均值 3 个标准差以上,才会被视为异常值。
修复方法是在检测到异常值后,用于处理异常值的方法。可从以下选项中进行选择:
-
裁剪:使用此选项可将异常值剪裁到相应的异常值检测边界。
-
删除:使用此选项可从数据框中删除含异常值的行。
-
失效:使用此选项可用无效值替换异常值。
分位数数字异常值
可使用此转换,通过分位数检测并修复数字特征中的异常值。您可以定义上分位数和下分位数。所有高于上分位数或低于下分位数的值,均被视为异常值。
修复方法是在检测到异常值后,用于处理异常值的方法。可从以下选项中进行选择:
-
裁剪:使用此选项可将异常值剪裁到相应的异常值检测边界。
-
删除:使用此选项可从数据框中删除含异常值的行。
-
失效:使用此选项可用无效值替换异常值。
Min-Max 数值异常值
此转换使用上限和下限阈值检测并修复数字特征中的异常值。如果您知道区分异常值的阈值,可使用此方法。
您应指定上限阈值和下限阈值,如果值分别高于或低于这些阈值,则被视为异常值。
修复方法是在检测到异常值后,用于处理异常值的方法。可从以下选项中进行选择:
-
裁剪:使用此选项可将异常值剪裁到相应的异常值检测边界。
-
删除:使用此选项可从数据框中删除含异常值的行。
-
失效:使用此选项可用无效值替换异常值。
替换稀有值
使用替换稀有值转换时,您指定一个阈值,Data Wrangler 会查找符合该阈值的所有值,然后将其替换为您指定的字符串。例如,您可能希望使用此转换,将列中的所有异常值归类到“其他”类别中。
-
替换字符串:用来替换异常值的字符串。
-
绝对阈值:如果实例数小于或等于此绝对阈值,则类别为稀有。
-
得分阈值:如果实例数小于或等于此得分阈值乘以行数,则类别为稀有。
-
最大常见类别:操作后保留的最大非稀有类别。如果阈值未筛选足够多的类别,那么出现频率最多的类别将被归为非稀有类别。如果设置为 0(默认值),那么类别数量没有硬性限制。
处理缺失值
在机器学习数据集中,缺失值属于常见情况。在某些情况下,使用计算值(如平均值或绝对普通值)来填补缺失的数据是合适的。您可以使用处理缺失值转换组来处理缺失值。此组包含以下转换。
填充缺失值
可使用填充缺失值转换,将缺失值替换为您所定义的填充值。
填补缺失值
可使用填补缺失值转换,创建新的列,其中包含在输入分类数据和数字数据中发现的缺失值的填补值。配置取决于您的数据类型。
对于数字数据,可选择一个填补策略,用于确定要填补的新值。您可以选择填补数据集中所存在值的平均值或中位数。Data Wrangler 使用它所计算的值来填补缺失值。
对于分类数据,Data Wrangler 使用列中最常见的值来填补缺失值。如果要填补自定义字符串,可改用填充缺失值转换。
添加缺失值指示器
可使用添加缺失值指示器转换,创建包含布尔值的新的指示器列:如果行中包含值,则为 "false";如果行中包含缺失值,则为 "true"。
删除缺失值
可使用删除缺失值选项,从输入列中删除包含缺失值的行。
管理列
您可以使用以下转换,快速更新和管理数据集中的列:
| Name | 函数 |
|---|---|
| 删除列 | 对列进行删除。 |
| 复制列 | 对列进行复制。 |
| 重命名列 | 对列进行重命名。 |
| 移动列 |
移动列在数据集中的位置。可选择将列移动到数据集的起始或结尾、参考列之前或之后,或特定索引。 |
管理行
可使用此转换组,对行快速执行排序和打乱操作。此组包含以下转换:
-
排序:按给定列对整个数据框进行排序。可为此选项选中升序旁边的复选框。或者,取消选中该复选框并按降序进行排列。
-
打乱:随机打乱数据集中的所有行。
管理向量
可使用此转换组,合并或展平向量列。此组包含以下转换。
-
组合:可使用此转换,将 Spark 向量和数字数据合并到单列中。例如,您可以合并三列:两列包含数字数据,另一列包含向量。在输入列中添加要合并的所有列,然后为合并的数据指定输出列名称。
-
展平:可使用此转换,对包含向量数据的单列进行展平。输入列必须包含 PySpark 向量或类似数组的对象。您可以通过指定检测输出数量的方法,控制创建的列数。例如,如果您选择第一个向量的长度,那么在列中找到的第一个有效向量或数组中的元素数量,决定了创建的输出列的数量。包含太多项的所有其他输入向量将被截断。项目太少的输入会被填满 NaNs。
您还可以指定输出前缀,用作每个输出列的前缀。
处理数字
可使用处理数字特征组,处理数字数据。此组中的每个缩放器均使用 Spark 库定义。支持以下缩放器:
-
标准缩放器:通过从每个值中减去平均值并缩放到单位方差,对输入列进行标准化。要了解更多信息,请参阅 Spark 文档StandardScaler。
-
稳健缩放器:使用对异常值而言稳健的统计数据缩放输入列。要了解更多信息,请参阅 Spark 文档RobustScaler
。 -
最小最大缩放器:通过将每个特征缩放到给定范围来转换输入列。要了解更多信息,请参阅 Spark 文档MinMaxScaler
。 -
最大绝对缩放器:通过将每个值除以最大绝对值来缩放输入列。要了解更多信息,请参阅 Spark 文档MaxAbsScaler
。
采样
导入数据后,您可以使用采样转换器,抽取数据的一个或多个样本。使用采样转换器时,Data Wrangler 会对原始数据集进行采样。
您可以选择以下采样方法之一:
-
限制:从第一行开始对数据集采样,直到指定的限制。
-
随机化:随机提取指定大小的样本。
-
分层:随机提取分层样本。
您可以对随机样本进行分层,以确保样本代表数据集的原始分布。
您可能正在为多个使用案例执行数据准备。对于每个使用案例,您可以抽取不同的样本并应用一组不同的转换。
以下过程描述了创建随机样本的过程。
从数据中抽取随机样本。
-
选择导入的数据集右侧的 +。数据集名称位于 + 下方。
-
选择添加转换。
-
选择采样。
-
对于采样方法,选择采样方法。
-
对于近似样本量,选择样本中所需的近似观测值数量。
-
(可选)为随机种子指定一个整数以创建可重现的样本。
以下过程描述了创建分层样本的过程。
从数据中抽取分层样本。
-
选择导入的数据集右侧的 +。数据集名称位于 + 下方。
-
选择添加转换。
-
选择采样。
-
对于采样方法,选择采样方法。
-
对于近似样本量,选择样本中所需的近似观测值数量。
-
对于分层列,指定要对其分层的列的名称。
-
(可选)为随机种子指定一个整数以创建可重现的样本。
搜索和编辑
可使用此部分,搜索和编辑字符串中的特定模式。例如,您可以查找并更新句子或文档中的字符串、按分隔符拆分字符串,以及查找特定字符串的多次出现。
搜索和编辑支持以下转换。所有转换都将在输入列中返回字符串副本,然后将结果添加到新的输出列。
| Name | 函数 |
|---|---|
|
查找子字符串 |
返回您搜索的子字符串第一次出现的索引。您可以分别在开始和结束处开始和结束搜索。 |
|
查找子字符串(从右起) |
返回您搜索的子字符串最后一次出现的索引。您可以分别在开始和结束处开始和结束搜索。 |
|
匹配前缀 |
如果字符串包含给定模式,则返回布尔值。模式可以是字符序列或正则表达式。您可以选择让模式区分大小写。 |
|
查找所有出现 |
返回一个数组,其中包含给定模式的所有出现。模式可以是字符序列或正则表达式。 |
|
使用正则表达式提取 |
返回一个与给定正则表达式模式相匹配的字符串。 |
|
在分隔符之间提取 |
返回一个字符串,其中包含在左分隔符与右分隔符之间找到的所有字符。 |
|
从位置提取 |
返回一个字符串,以输入字符串的开始位置开头,包含开始位置加上长度之前的所有字符。 |
|
查找并替换子字符串 |
返回一个字符串,其中给定模式(正则表达式)的所有匹配项均替换为替换字符串。 |
|
在分隔符之间替换 |
返回一个字符串,其中在左分隔符的第一次出现与右分隔符的最后一次出现之间找到的字符串,替换为替换字符串。如果未找到匹配项,则不进行任何替换。 |
|
从位置替换 |
返回一个字符串,其中开始位置与开始位置加上长度之间的子字符串,替换为替换字符串。如果开始位置加上长度大于替换字符串的长度,则输出包含 ...。 |
|
将正则表达式转换为缺失值 |
如果无效则将字符串转换为 |
|
按分隔符拆分字符串 |
返回输入字符串的一个字符串数组,按分隔符拆分,最多可以达到最大拆分数量(可选)。分隔符默认为空格。 |
拆分数据
可使用拆分数据转换,将数据集拆分为两个或三个数据集。例如,您可以将数据集拆分为用于训练模型的数据集,以及用于测试模型的数据集。您可以决定每次拆分的数据集比例。例如,如果您要将一个数据集拆分为两个数据集,则训练数据集可以包含 80% 的数据,测试数据集包含 20% 的数据。
您可以将数据拆分为三个数据集,以便创建训练、验证和测试数据集。您可以通过删除目标列,来查看模型在测试数据集上的表现。
您的使用场景决定了每个数据集可获得多少原始数据集,以及用于拆分数据的方法。例如,您可能希望使用分层拆分,确保目标列中观测值在数据集中的分布相同。您可以使用以下拆分转换:
-
随机拆分 – 每个拆分都是原始数据集的随机、非重叠样本。对于较大的数据集,使用随机拆分的计算成本可能很高,而且比有序拆分花费的时间更长。
-
有序拆分:根据观测值的顺序拆分数据集。例如,对于 80/20 训练测试拆分,占数据集 80% 的第一批观测值将进入训练数据集。后面 20% 的观测结果去到测试数据集。有序拆分可有效保持拆分之间数据的现有顺序。
-
分层拆分:拆分数据集以确保输入列中的观测值数量按比例代表。对于具有观测值 1、1、1、1、1、1、1、2、2、2、2、2、2、2、2、2、2、3、3、3、3、3、3、3、3、3、3、3、3、3、3、3、1、1、1、1、1、1、1、80% 的 2 和 80% 的 3 进入训练集。 80/20 大约 20% 的每种类型的观测值去到测试集。
-
按键拆分 – 避免具有相同键的数据出现在多个拆分中。例如,如果数据集中包含“customer_id”列,并且您将该列用作键,则客户 ID 不会出现在多个拆分中。
拆分数据之后,您可以对每个数据集应用其他转换。对于大多数使用案例而言,并不是必需的。
Data Wrangler 会计算拆分的比例,以提高性能。您可以选择误差阈值来设置拆分的准确性。较低的误差阈值可以更准确地反映您指定的拆分比例。如果设置较高的误差阈值,则性能会更好,但准确性会降低。
要获得完美拆分的数据,可将误差阈值设置为 0。您可以指定介于 0 与 1 之间的阈值,以提高性能。如果指定的值大于 1,则 Data Wrangler 将该值解释为 1。
如果您的数据集中有 10000 行,并且指定了误差为 0.001 的 80/20 拆分,则观测值将接近以下结果之一:
-
训练集中有 8010 个观测值,测试集中有 1990 个观测值
-
训练集中有 7990 个观测值,测试集中有 2010 个观测值
在上述示例中,训练集的观测值数量在 8010 到 7990 之间的区间内。
默认情况下,Data Wrangler 使用随机种子来使拆分可重现。您可以为种子指定不同的值,以创建不同的可重现拆分。
将值解析为类型
可使用此转换,将列转为新的类型。支持的 Data Wrangler 数据类型包括:
-
长整型
-
浮点型
-
布尔值
-
日期,格式为 dd-MM-yyyy,分别表示日、月和年。
-
字符串
验证字符串
可使用验证字符串转换,创建新列以指示文本数据行是否符合指定的条件。例如,您可以使用验证字符串转换,验证字符串是否只包含小写字符。验证字符串支持以下转换。
此转换组中包括以下转换。如果转换输出布尔值,则 True 用 1 表示,False 用 0 表示。
| Name | 函数 |
|---|---|
|
字符串长度 |
如果字符串长度等于指定长度,则返回 |
|
开始字符 |
如果字符串以指定前缀开头,则返回 |
|
结束字符 |
如果字符串长度等于指定长度,则返回 |
|
是字母数字 |
如果字符串仅包含数字和字母,则返回 |
|
是字母 |
如果字符串仅包含字母,则返回 |
|
是数字 |
如果字符串仅包含数字,则返回 |
|
是空格 |
如果字符串仅包含数字和字母,则返回 |
|
是标题 |
如果字符串包含任何空格,则返回 |
|
是小写 |
如果字符串仅包含小写字母,则返回 |
|
是大写 |
如果字符串仅包含大写字母,则返回 |
|
是数值 |
如果字符串仅包含数值,则返回 |
|
是十进制 |
如果字符串仅包含十进制数字,则返回 |
取消嵌套 JSON 数据
如果您有 .csv 文件,则数据集中的值可能是 JSON 字符串。同样地,Parquet 文件或 JSON 文档的列中可能存在嵌套数据。
可使用展平结构运算符,将第一级键分隔到单独的列中。第一级键即没有嵌套在值中的键。
例如,您可能有一个数据集,其中包含 person 列,且每个人的人口统计信息存储为 JSON 字符串。JSON 字符串可能类似如下所示。
"{"seq": 1,"name": {"first": "Nathaniel","last": "Ferguson"},"age": 59,"city": "Posbotno","state": "WV"}"
展平结构运算符会将以下第一级键转换到数据集中的其他列:
-
seq
-
name
-
age
-
city
-
状态
Data Wrangler 将键的值作为值放在列下。下面显示了 JSON 的列名和值。
seq, name, age, city, state 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV
对于数据集中包含 JSON 的每个值,展平结构运算符会为第一级键创建列。要为嵌套键创建列,可再次调用运算符。对于上述示例,调用运算符将创建以下列:
-
name_first
-
name_last
以下示例显示了再次调用操作后产生的数据集。
seq, name, age, city, state, name_first, name_last 1, {"first": "Nathaniel","last": "Ferguson"}, 59, Posbotno, WV, Nathaniel, Ferguson
可选择要展平的键,指定要提取为单独列的第一级键。如果未指定任何键,默认情况下 Data Wrangler 会提取所有键。
爆炸数组
可使用爆炸数组,将数组的值扩展为单独的输出行。例如,此操作可提取如下数组中的每个值:[[1, 2, 3,], [4, 5, 6], [7, 8, 9]],并创建包含以下行的新列:
[1, 2, 3] [4, 5, 6] [7, 8, 9]
Data Wrangler 将新列命名为 input_column_name_flatten。
您可以多次调用爆炸数组操作,将数组的嵌套值放入单独的输出列中。以下示例显示了对包含嵌套数组的数据集多次调用此操作的结果。
将嵌套数组的值放入单独的列中
| id | array | id | array_items | id | array_items_items |
|---|---|---|---|---|---|
| 1 | [ [cat, dog], [bat, frog] ] | 1 | [cat, dog] | 1 | cat |
| 2 |
[[rose, petunia], [lily, daisy]] |
1 | [bat, frog] | 1 | dog |
| 2 | [rose, petunia] | 1 | bat | ||
| 2 | [lily, daisy] | 1 | frog | ||
| 2 | 2 | rose | |||
| 2 | 2 | petunia | |||
| 2 | 2 | lily | |||
| 2 | 2 | daisy |
转换图像数据
可使用 Data Wrangler 导入并转换用于机器学习 (ML) 管线的图像。准备好图像数据后,可以将其从 Data Wrangler 流导出至机器学习管线。
您可以使用此处提供的信息,来熟悉如何在 Data Wrangler 中导入并转换图像数据。Data Wrangler 使用 OpenCV 导入图像。有关支持的图像格式的更多信息,请参阅图像文件读取和写入
熟悉转换图像数据的概念后,请阅读以下教程 “使用 Amazon Data Wrangler 准备图像 SageMaker 数据
以下是将机器学习应用于转换后的图像数据的行业和使用案例,这些示例可能会有帮助:
-
制造业 – 识别装配线中物品的缺陷
-
食品业 – 识别变质或腐烂的食物
-
医学 – 识别组织中的病变
在 Data Wrangler 中处理图像数据时,会经历以下过程:
-
导入 – 通过在 Amazon S3 存储桶中选择包含图像的目录来选择图像。
-
转换 – 使用内置的转换,为机器学习管线准备图像。
-
导出 – 将转换后的图像导出至可从管线访问的位置。
可使用以下过程,导入图像数据。
导入图像数据
-
导航至创建连接页面。
-
选择 Amazon S3。
-
指定包含图像数据的 Amazon S3 文件路径。
-
对于文件类型,选择图像。
-
(可选)选择导入嵌套目录,从多个 Amazon S3 路径导入图像。
-
选择导入。
Data Wrangler 使用开源 imgaug
-
ResizeImage
-
EnhanceImage
-
CorruptImage
-
SplitImage
-
DropCorruptedImages
-
DropImageDuplicates
-
Brightness
-
ColorChannels
-
Grayscale
-
Rotate
使用以下过程,无需编写代码即可转换图像。
无需编写代码即可转换图像数据
-
在 Data Wrangler 流中,选择代表已导入图像的节点旁边的 +。
-
选择添加转换。
-
选择添加步骤。
-
选择转换并进行配置。
-
选择预览。
-
选择添加。
除了使用 Data Wrangler 提供的转换之外,您还可以使用自己的自定义代码片段。有关使用自定义代码片段的更多信息,请参阅自定义转换。您可以在代码片段中导入 OpenCV 和 imgaug 库,并使用与之相关的转换。以下是一个用于检测图像边缘的代码片段示例。
# A table with your image data is stored in the `df` variable import cv2 import numpy as np from pyspark.sql.functions import column from sagemaker_dataprep.compute.operators.transforms.image.constants import DEFAULT_IMAGE_COLUMN, IMAGE_COLUMN_TYPE from sagemaker_dataprep.compute.operators.transforms.image.decorators import BasicImageOperationDecorator, PandasUDFOperationDecorator @BasicImageOperationDecorator def my_transform(image: np.ndarray) -> np.ndarray: # To use the code snippet on your image data, modify the following lines within the function HYST_THRLD_1, HYST_THRLD_2 = 100, 200 edges = cv2.Canny(image,HYST_THRLD_1,HYST_THRLD_2) return edges @PandasUDFOperationDecorator(IMAGE_COLUMN_TYPE) def custom_image_udf(image_row): return my_transform(image_row) df = df.withColumn(DEFAULT_IMAGE_COLUMN, custom_image_udf(column(DEFAULT_IMAGE_COLUMN)))
在 Data Wrangler 流中应用转换时,Data Wrangler 仅对数据集中的图像样本应用转换。为了优化应用程序体验,Data Wrangler 不会对所有图像应用转换。
要将转换应用于所有图像,可将 Data Wrangler 流导出至 Amazon S3 位置。您可以在训练或推理管线中使用导出的图像。可使用目标节点或 Jupyter 笔记本导出数据。您可以通过任一方法从 Data Wrangler 流导出数据。有关使用这些方法的信息,请参阅导出到 Amazon S3。
筛选数据
可使用 Data Wrangler 筛选列中的数据。筛选列中的数据时,需要指定以下字段:
-
列名 – 用于筛选数据的列的名称。
-
条件 – 要对列中的值应用的筛选器类型。
-
值 – 要应用筛选器的列中的值或类别。
您可以按以下条件进行筛选:
-
= – 返回与指定值或类别相匹配的值。
-
!= – 返回与指定值或类别不匹配的值。
-
>= – 对于长整型或浮点型数据,筛选大于或等于指定值的值。
-
<= – 对于长整型或浮点型数据,筛选小于或等于指定值的值。
-
> – 对于长整型或浮点型数据,筛选大于指定值的值。
-
< – 对于长整型或浮点型数据,筛选小于指定值的值。
对于包含类别 male 和 female 的列,可以筛选出所有 male 值。也可以筛选出所有 female 值。由于列中只有 male 和 female 值,因此筛选器返回仅包含 female 值的列。
您还可以添加多个筛选器。筛选器可应用于多列或同一列。例如,如果您要创建仅包含特定范围内的值的列,那么可添加两个不同的筛选器。一个筛选器指定列的值必须大于提供的值。另一个筛选器指定列的值必须小于提供的值。
可使用以下过程,将筛选转换添加到数据。
筛选数据
-
在 Data Wrangler 流中,选择包含要筛选的数据的节点旁边的 +。
-
选择添加转换。
-
选择添加步骤。
-
选择筛选数据。
-
指定以下字段:
-
列名 – 要筛选的列。
-
条件 – 筛选器的条件。
-
值 – 要应用筛选器的列中的值或类别。
-
-
(可选)选择创建的筛选器后面的 +。
-
配置筛选器。
-
选择预览。
-
选择添加。
为 Amazon Personalize 映射列
Data Wrangler 可与 Amazon Personalize 集成,后者是一项完全托管的机器学习服务,可生成项目建议和用户细分。您可以使用为 Amazon Personalize 映射列转换,将数据转换为 Amazon Personalize 可以解释的格式。有关特定于 Amazon Personalize 的转换的更多信息,请参阅使用 Amazon Data Wrangler 导入 SageMaker 数据。有关 Amazon Personalize 的更多信息,请参阅 Amazon Personalize 是什么?