本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
自动设置标注作业的数据
您可以使用自动数据设置,在 Ground Truth 控制台中使用存储在 Amazon S3 中的图像、视频、视频帧、文本 (.txt) 文件和逗号分隔值 (.csv) 文件创建标注作业的清单文件。使用自动数据设置时,您需要指定存储输入数据的 Amazon S3 位置和输入数据类型,然后 Ground Truth 会在您指定的位置查找与该类型相匹配的文件。
注意
Ground Truth 不会使用 Amazon KMS 密钥访问您的输入数据或将输入清单文件写入您指定的 Amazon S3 位置。创建标注作业的用户或角色必须拥有访问 Amazon S3 中输入数据对象的权限。
在使用以下过程之前,请确保输入图像或文件的格式正确:
-
图像文件 – 图像文件必须遵守输入文件大小限额中的表列出的大小和分辨率限制。
-
文本文件 – 文本数据可以存储在一个或多个 .txt 文件中。要标注的每个项目必须用标准换行符分隔。
-
CSV 文件 – 文本数据可以存储在一个或多个 .csv 文件中。要标注的每个项目必须位于单独的行中。
-
视频 – 视频文件可以是以下任何一种格式:.mp4、.ogg 和 .webm。如果要从视频文件中提取视频帧以进行对象检测或对象跟踪,请参阅提供视频文件。
-
视频帧 – 视频帧是从视频中提取的图像。从单个视频中提取的所有图像称为视频帧序列。在 Amazon S3 中,每个视频帧序列必须具有唯一的前缀键。请参阅提供视频帧。有关此数据类型,请参阅设置自动视频帧输入数据
重要
有关视频帧对象检测和视频帧对象跟踪标注作业,请参阅设置自动视频帧输入数据,了解如何使用自动数据设置。
使用这些说明自动设置与 Ground Truth 的输入数据集连接。
使用 Ground Truth 自动连接 Amazon S3 中的数据
-
在 Amazon A SageMaker I 控制台中导航至 “创建标签任务” 页面,网址为https://console.aws.amazon.com/sagemaker/
。 此链接将您带到北弗吉尼亚州 (us-east- Amazon 1) 区域。如果输入数据在另一个区域的 Amazon S3 存储桶中,请切换到该区域。要更改您的 Amazon 区域,请在导航栏上选择当前显示的区域的名称。
-
选择创建标注作业。
-
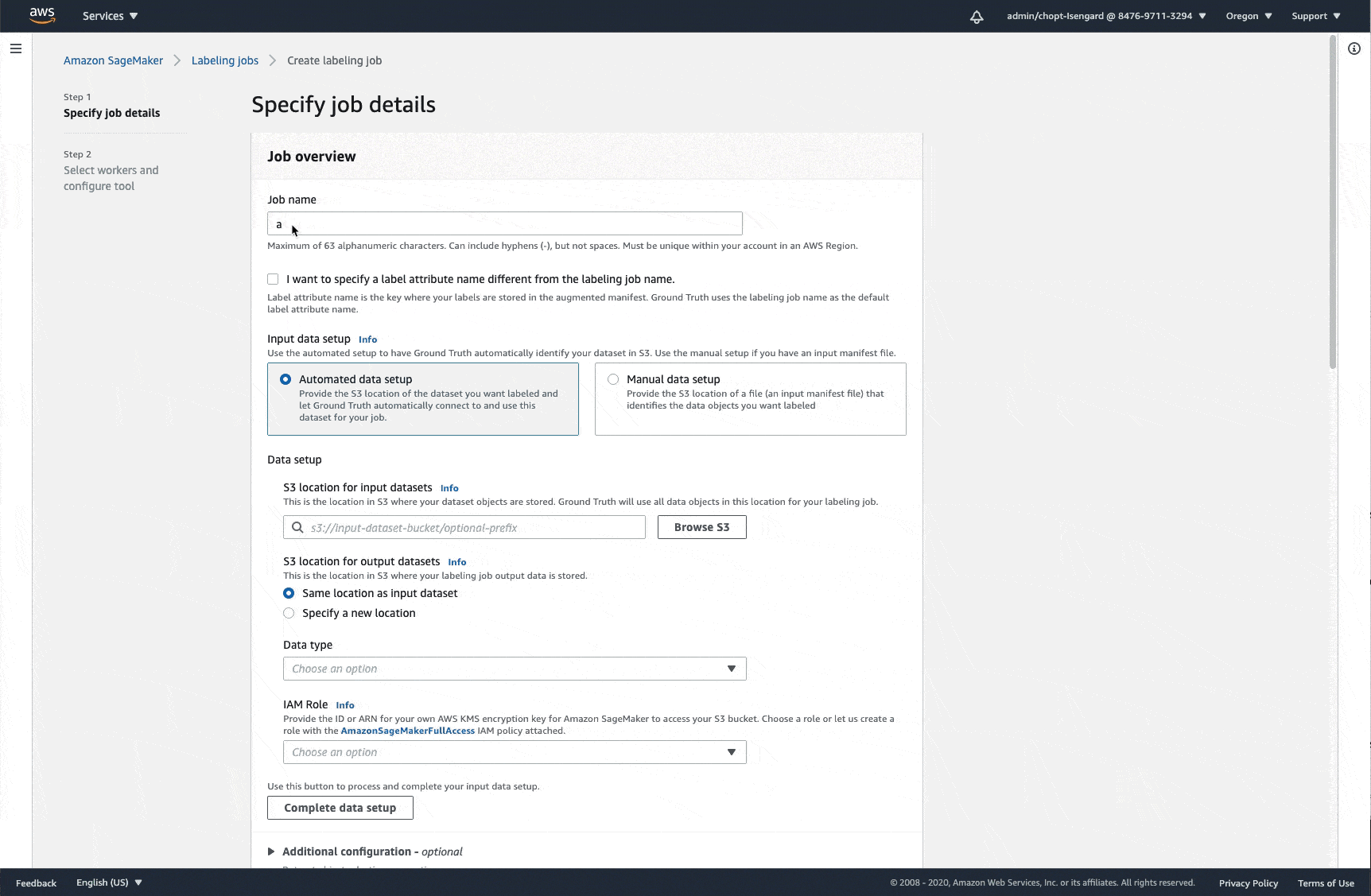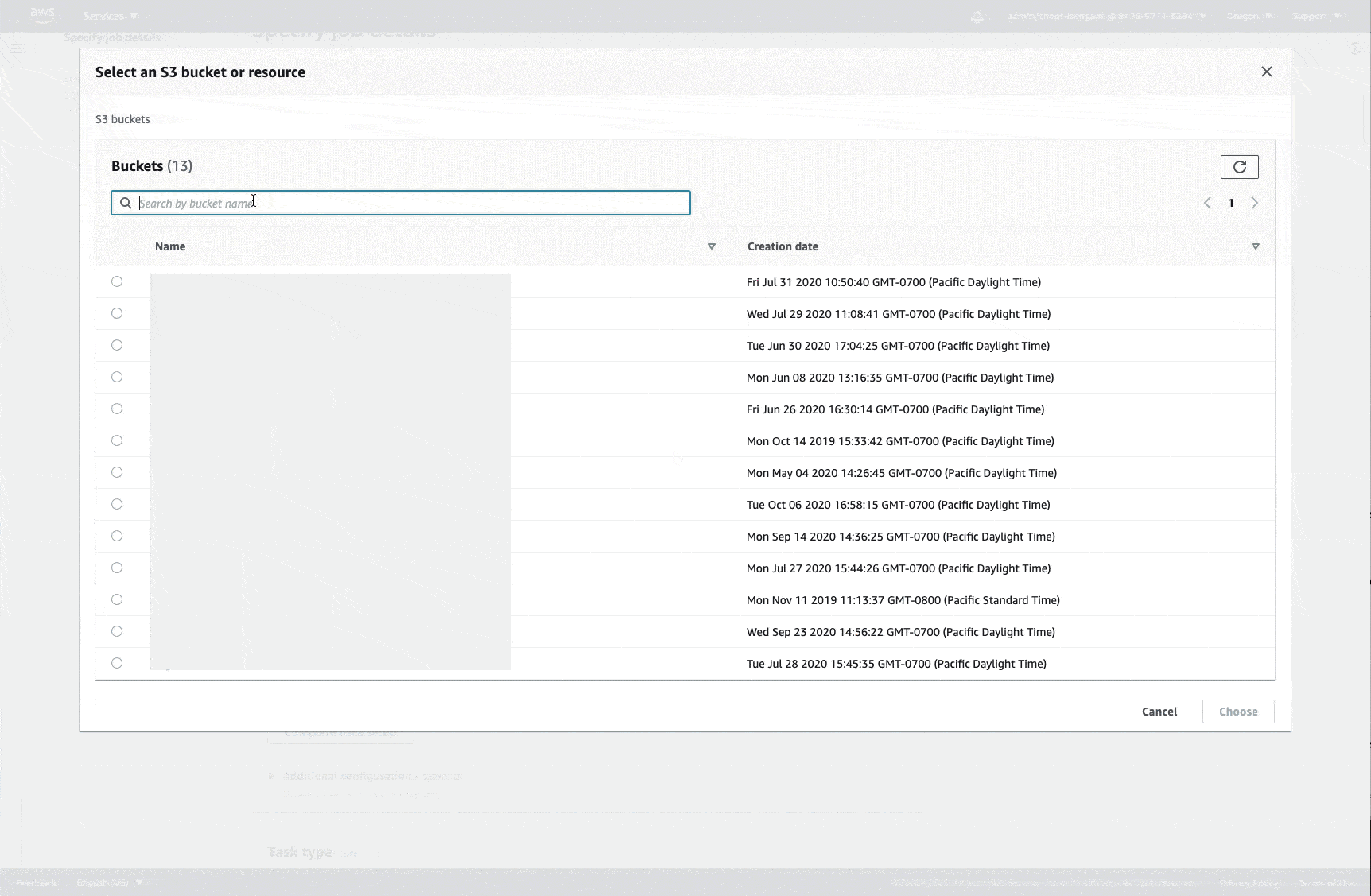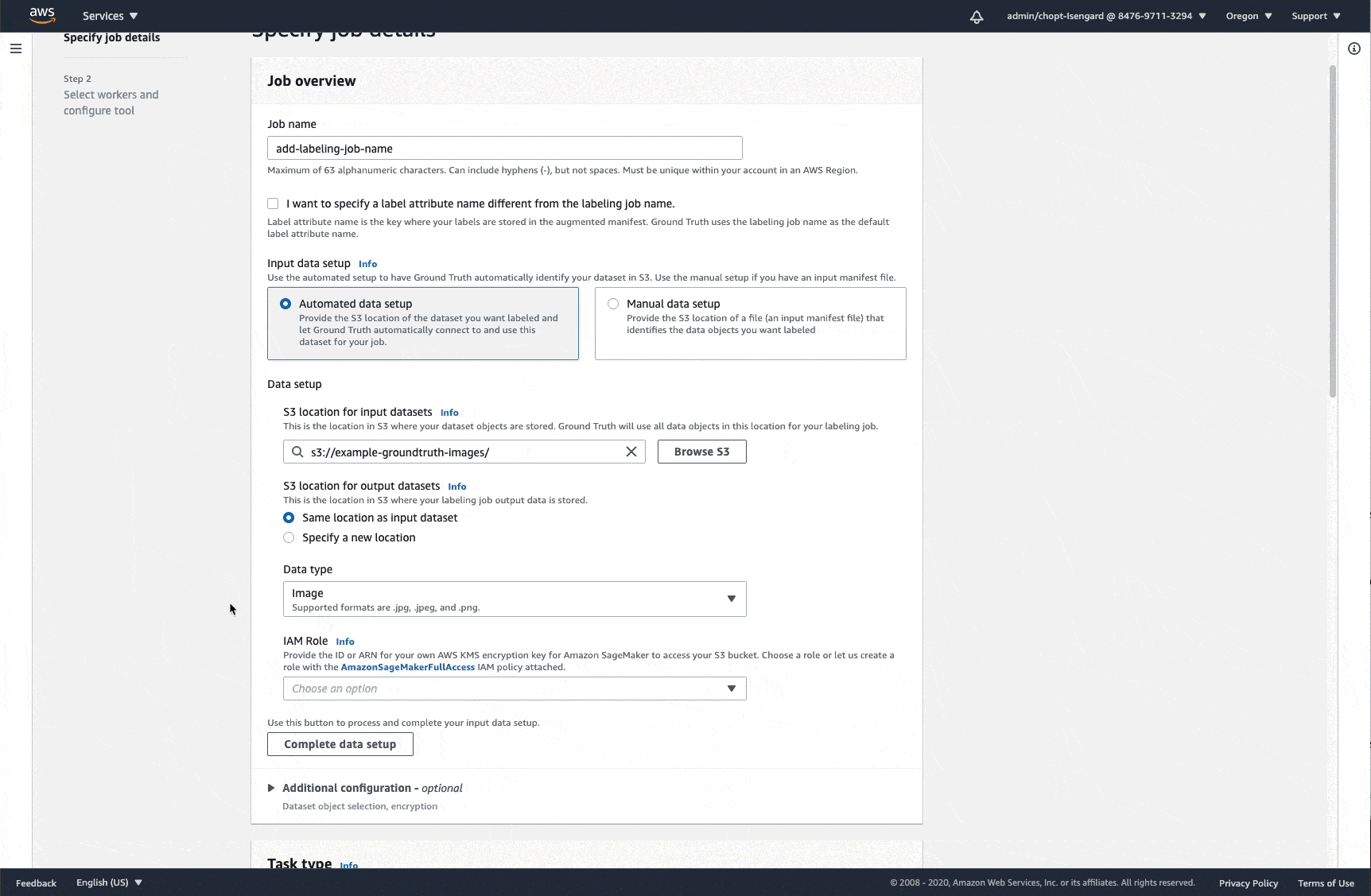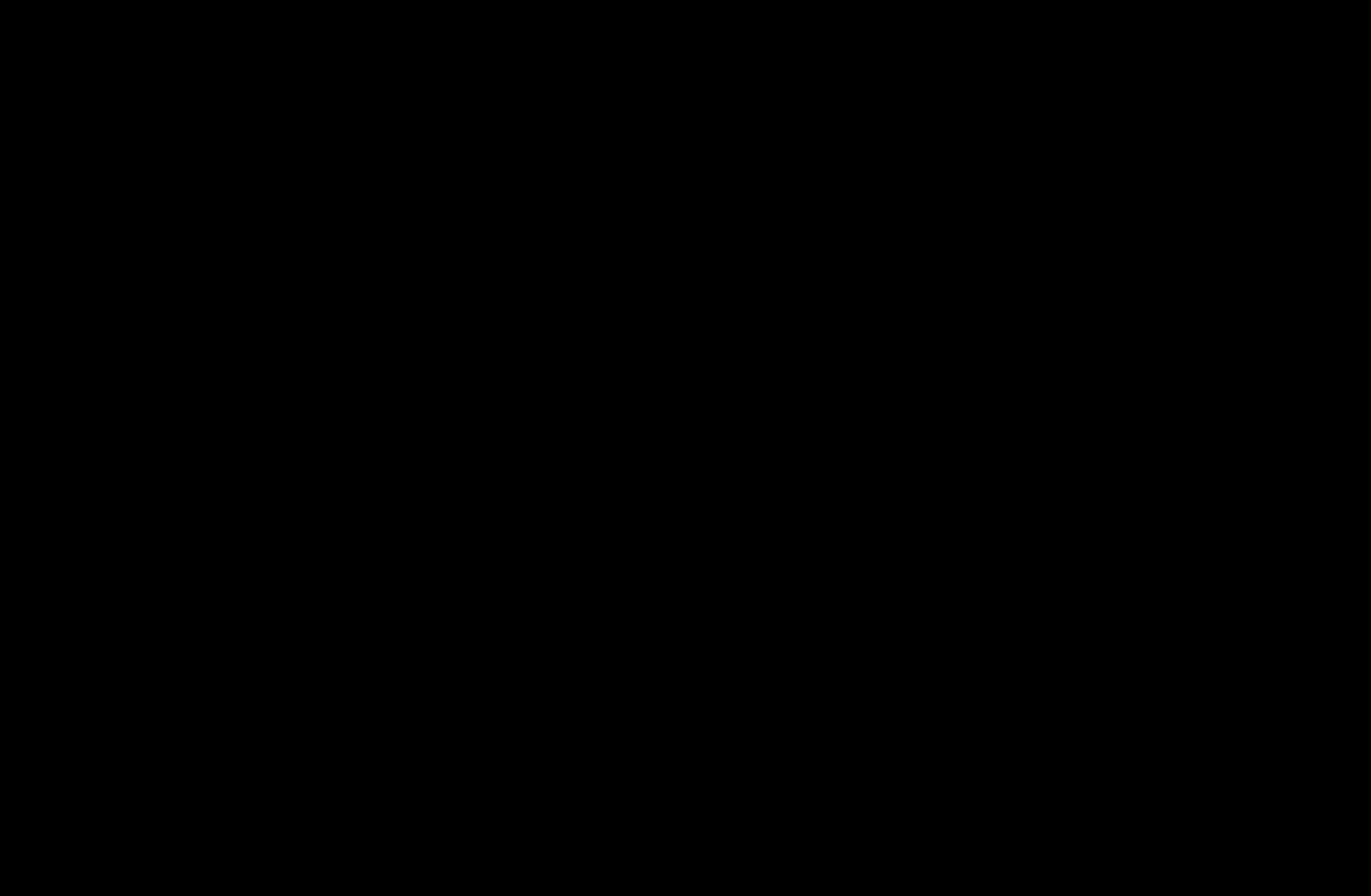
输入作业名称。
-
在输入数据设置部分,选择自动数据设置。
-
输入 Amazon S3 URI 作为输入数据集的 S3 位置。
-
指定输出数据集的 S3 位置。这是存储输出数据的位置。
-
使用下拉列表选择数据类型。
-
使用 IAM 角色下的下拉菜单选择执行角色。如果选择创建新角色,请指定要授予此角色访问权限的 Amazon S3 存储桶。此角色必须有权访问您在步骤 5 和 6 中指定的 S3 存储桶。
-
选择完成数据设置。
这将在您在步骤 5 中指定的输入数据集的 Amazon S3 位置创建输入清单。如果您要使用 SageMaker API 或、或 Amazon SDK 创建标签任务 Amazon CLI,请使用此输入清单文件的 Amazon S3 URI 作为参数的输入ManifestS3Uri。
以下 GIF 演示了如何将自动数据设置用于图像数据。此示例将在 Amazon S3 存储桶 example-groundtruth-images 中创建一个文件 dataset-,其中 YYMMDDTHHMMSS.manifestYYMMDDTHHmmSSYY)、月 (MM)、日 (DD) 和时 (HH)、分 (mm)、秒 (ss)。