本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用视频帧对象检测识别对象
您可以使用视频帧对象检测任务类型,让工作人员使用边界框、折线、多边形或关键点这样的注释工具识别和定位视频帧序列(从视频中提取的图像)中的对象。您选择的工具定义了您创建的视频帧任务类型。例如,您可以使用边界框视频帧对象检测任务类型,让工作人员识别和定位一系列视频帧中的各种对象,例如汽车、自行车和行人。您可以使用 Amazon A SageMaker I Ground Truth 控制台、 SageMaker API 和特定语言 Amazon 的软件开发工具包创建视频帧对象检测标签作业。要了解更多信息,请参阅创建视频帧对象检测标注作业并选择您的首选方法。请参阅任务类型,了解更多关于创建标注作业时可以选择的注释工具的信息。
Ground Truth 提供了工作人员 UI 和工具来完成标注作业任务:预览工作人员 UI。
您可以创建一个作业,以使用视频对象检测调整任务类型调整在视频对象检测标注作业中创建的注释。要了解更多信息,请参阅创建视频帧对象检测调整或验证标注作业。
预览工作人员 UI
Ground Truth 为工作人员提供了一个 Web 用户界面 (UI),用于完成视频帧对象检测注释任务。在控制台中创建标注作业时,您可以预览该工作人员 UI 并与之交互。如果您是新用户,我们建议您使用小型输入数据集通过控制台创建标注作业,以预览工作人员 UI,并确保视频帧、标签和标签属性如预期显示。
UI 为工作人员提供了以下辅助标注工具来完成对象检测任务:
-
对于所有任务,工作人员都可以使用复制到下一帧和复制到所有帧功能,分别将注释复制到下一帧或所有后续帧。
-
对于包含边界框工具的任务,工作人员可以使用预测下一个功能在单帧中绘制边界框,然后让 Ground Truth 预测所有其他帧中具有相同标签的边界框的位置。然后,工作人员可以进行调整以更正预测的边界框位置。
下面的视频展示了工作人员如何使用工作人员用户界面和边界框工具来完成对象检测任务。

创建视频帧对象检测标注作业
您可以使用 SageMaker AI 控制台或 CreateLabelingJobAPI 操作创建视频帧对象检测标签作业。
本部分假设您已经查看视频帧标注作业参考并选择了要使用的输入数据类型和输入数据集连接。
创建标注作业(控制台)
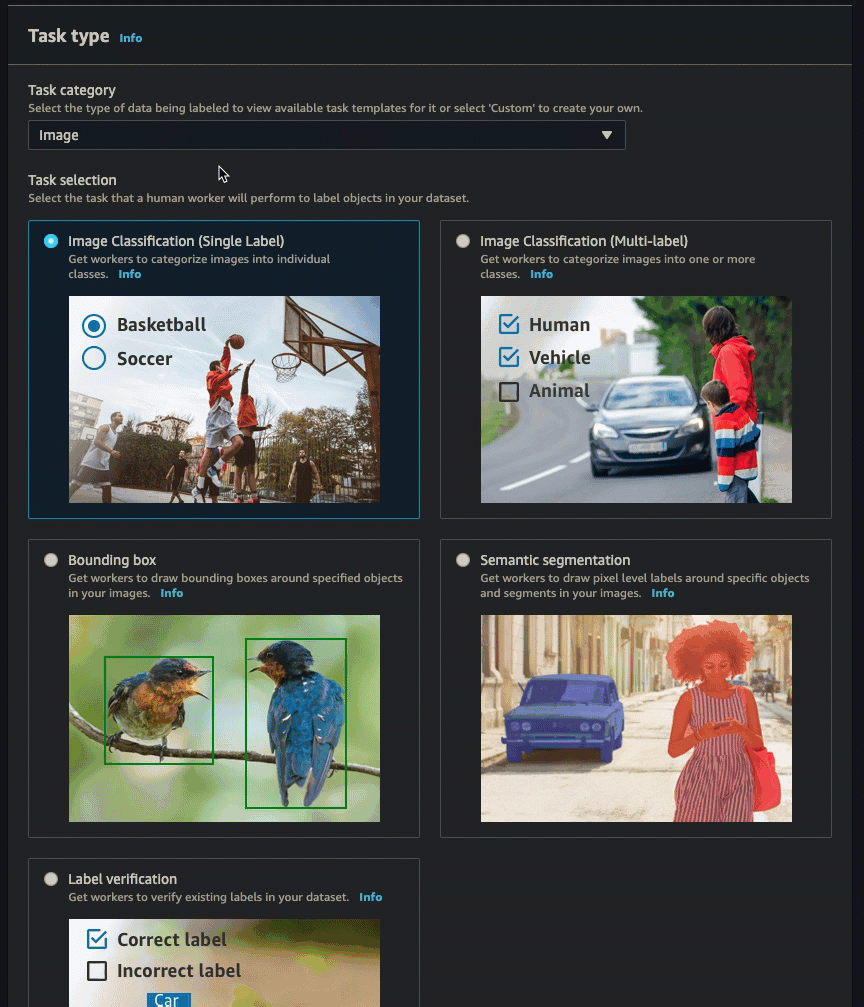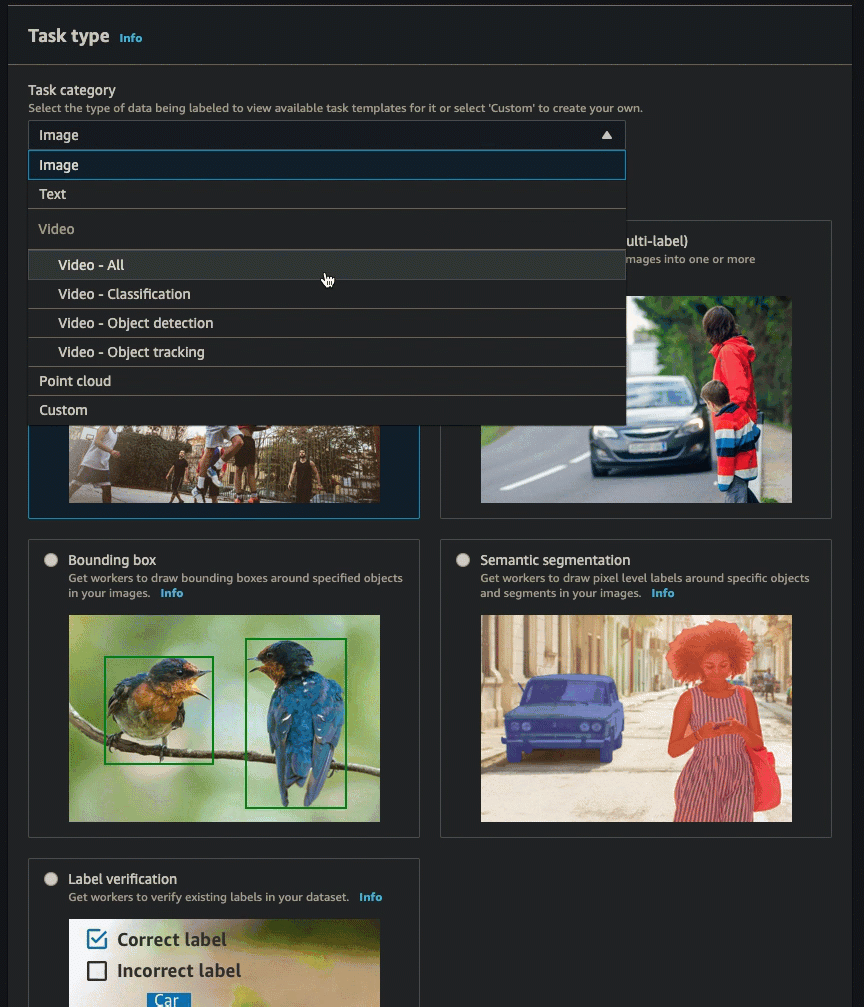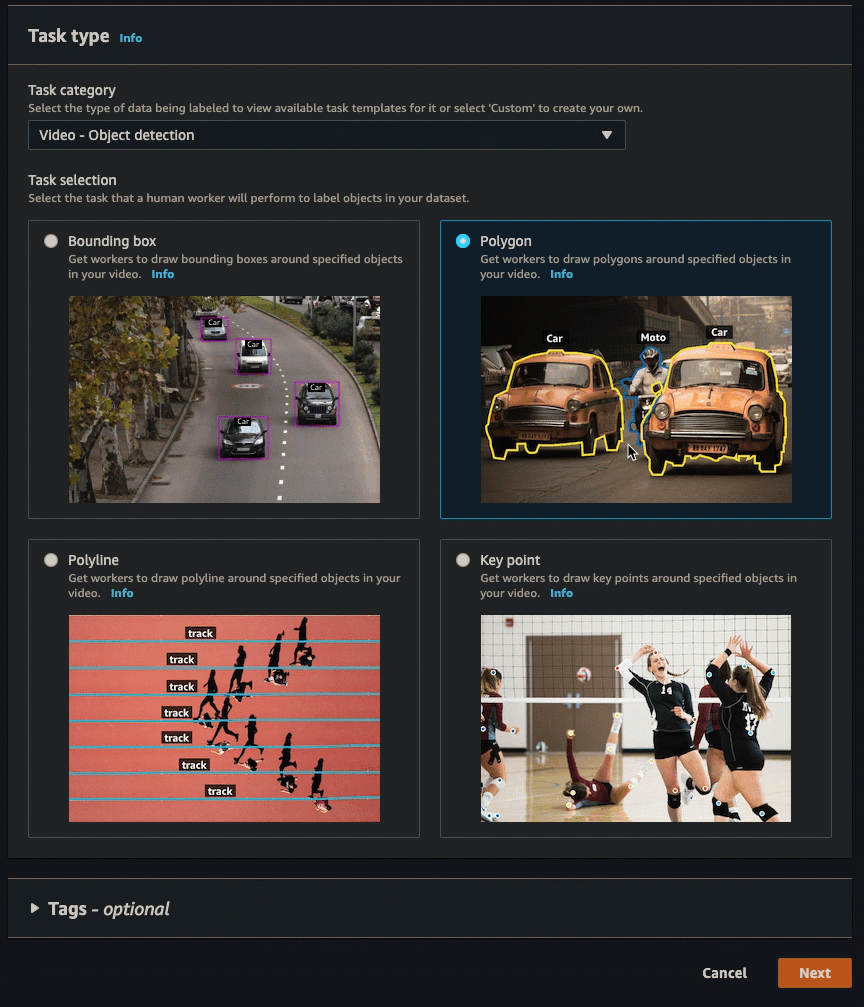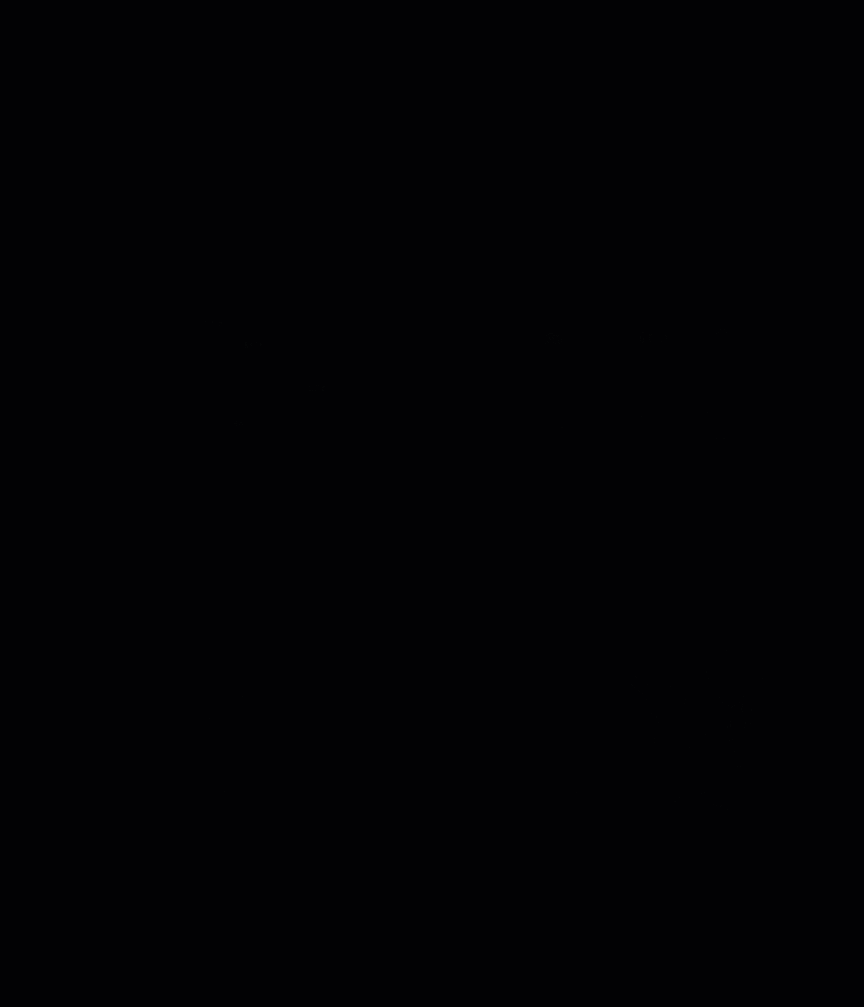
您可以按照中的说明创建标注作业(控制台)来学习如何在 SageMaker AI 控制台中创建视频帧对象跟踪作业。在第 10 步中,从任务类别下拉列表中选择视频 - 对象检测。在任务选择中选择一张卡片,即可选择所需的任务类型。
创建标注作业 (API)
您可以使用 SageMaker API 操作创建对象检测标签作业CreateLabelingJob。此 API 为所有 Amazon SDK 定义了此操作。要查看此操作支持的特定于语言的 SDK 列表,请查看 CreateLabelingJob 的另请参阅部分。
创建标注作业 (API)概述了 CreateLabelingJob 操作。请按照这些说明进行操作,并在配置请求时执行以下操作:
-
您必须为
HumanTaskUiArn输入一个 ARN。使用arn:aws:sagemaker:。将<region>:394669845002:human-task-ui/VideoObjectDetection<region>不要包含
UiTemplateS3Uri参数的条目。 -
LabelAttributeName必须以-ref结尾。例如video-od-labels-ref -
输入清单文件必须是视频帧序列清单文件。您可以使用 SageMaker AI 控制台创建此清单文件,也可以手动创建该文件并将其上传到 Amazon S3。有关更多信息,请参阅 输入数据设置。
-
您只能使用私有或供应商工作团队来创建视频帧对象检测标注作业。
-
您可以在标签类别配置文件中指定标签、标签类别和帧属性、任务类型和工作人员说明。使用
annotationType在标签类别配置文件中指定任务类型(边界框、折线、多边形或关键点)。有关更多信息,请参阅带有标签类别和框架属性参考的标注类别配置文件以了解如何创建此文件。 -
您需要为注释前和注释后 (ACS) Lambda 函数提供预定义的 ARN。这些 ARN 特定于您用于创建标注作业的 Amazon 区域。
-
要查找注释前 Lambda ARN,请参考
PreHumanTaskLambdaArn。请使用您在其中创建标注作业的区域来查找以PRE-VideoObjectDetection结尾的正确 ARN。 -
要查找注释后 Lambda ARN,请参考
AnnotationConsolidationLambdaArn。请使用您在其中创建标注作业的区域来查找以ACS-VideoObjectDetection结尾的正确 ARN。
-
-
NumberOfHumanWorkersPerDataObject中指定的工作人员数必须为1。 -
视频帧标注作业不支持自动数据标注。不要在
LabelingJobAlgorithmsConfig中指定参数值。 -
视频帧对象跟踪标注作业可能需要数小时才能完成。您可以在
TaskTimeLimitInSeconds中为这些标注作业指定更长的时间限制(最多 7 天或 604800 秒)。
以下是一个 Amazon Python SDK (Boto3) 请求
response = client.create_labeling_job( LabelingJobName='example-video-od-labeling-job, LabelAttributeName='label', InputConfig={ 'DataSource': { 'S3DataSource': { 'ManifestS3Uri':'s3://amzn-s3-demo-bucket/path/video-frame-sequence-input-manifest.json'} }, 'DataAttributes': { 'ContentClassifiers': ['FreeOfPersonallyIdentifiableInformation'|'FreeOfAdultContent', ] } }, OutputConfig={ 'S3OutputPath':'s3://amzn-s3-demo-bucket/prefix/file-to-store-output-data', 'KmsKeyId':'string'}, RoleArn='arn:aws:iam::*:role/*, LabelCategoryConfigS3Uri='s3://bucket/prefix/label-categories.json', StoppingConditions={ 'MaxHumanLabeledObjectCount':123, 'MaxPercentageOfInputDatasetLabeled':123}, HumanTaskConfig={ 'WorkteamArn':'arn:aws:sagemaker:us-east-1:*:workteam/private-crowd/*', 'UiConfig': { 'HumanTaskUiArn: 'arn:aws:sagemaker:us-east-1:394669845002:human-task-ui/VideoObjectDetection' }, 'PreHumanTaskLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:PRE-VideoObjectDetection', 'TaskKeywords': ['Video Frame Object Detection', ], 'TaskTitle':'Video frame object detection task', 'TaskDescription':'Classify and identify the location of objects and people in video frames', 'NumberOfHumanWorkersPerDataObject':123, 'TaskTimeLimitInSeconds':123, 'TaskAvailabilityLifetimeInSeconds':123, 'MaxConcurrentTaskCount':123, 'AnnotationConsolidationConfig': { 'AnnotationConsolidationLambdaArn': 'arn:aws:lambda:us-east-1:432418664414:function:ACS-VideoObjectDetection' }, Tags=[ { 'Key':'string', 'Value':'string'}, ] )
创建视频帧对象检测调整或验证标注作业
您可以使用 Ground Truth 控制台或 CreateLabelingJob API 创建调整和验证标注作业。要了解有关调整和验证标注作业的更多信息,以及如何创建标注作业,请参阅标签验证和调整。
输出数据格式
当创建视频帧对象检测标注作业时,会将任务发送给工作人员。在这些工作人员完成其任务时,标签会写入到您创建标注作业时指定的 Amazon S3 输出位置。要了解视频帧对象检测输出数据格式,请参阅视频帧对象检测输出。如果您是 Ground Truth 的新用户,请参阅标注作业输出数据以了解有关 Ground Truth 输出数据格式的更多信息。