本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
SageMaker JumpStart 预训练模型
Amazon SageMaker JumpStart 为各种问题类型提供预训练的开源模型,以帮助您开始使用机器学习。在部署之前,您可以逐步训练和调整这些模型。 JumpStart 还提供了用于为常见用例设置基础架构的解决方案模板,以及用于通过 SageMaker AI 进行机器学习的可执行示例笔记本。
在更新后的 Studio 体验中,您可以通过模型登录页面部署、微调和评估来自热门模型中心的预训练模型。
您还可以通过 Amazon SageMaker Studio Classic 中的模型登录页面访问预训练模型、解决方案模板和示例。
以下步骤展示了如何使用亚马逊 SageMaker Studio 和 Amazon Studio Class SageMaker ic 访问 JumpStart 模型。
您也可以使用 SageMaker Python 软件开发工具包访问 JumpStart 模型。有关如何以编程方式使用 JumpStart 模型的信息,请参阅在预训练模型中使用 SageMaker JumpStart 算法
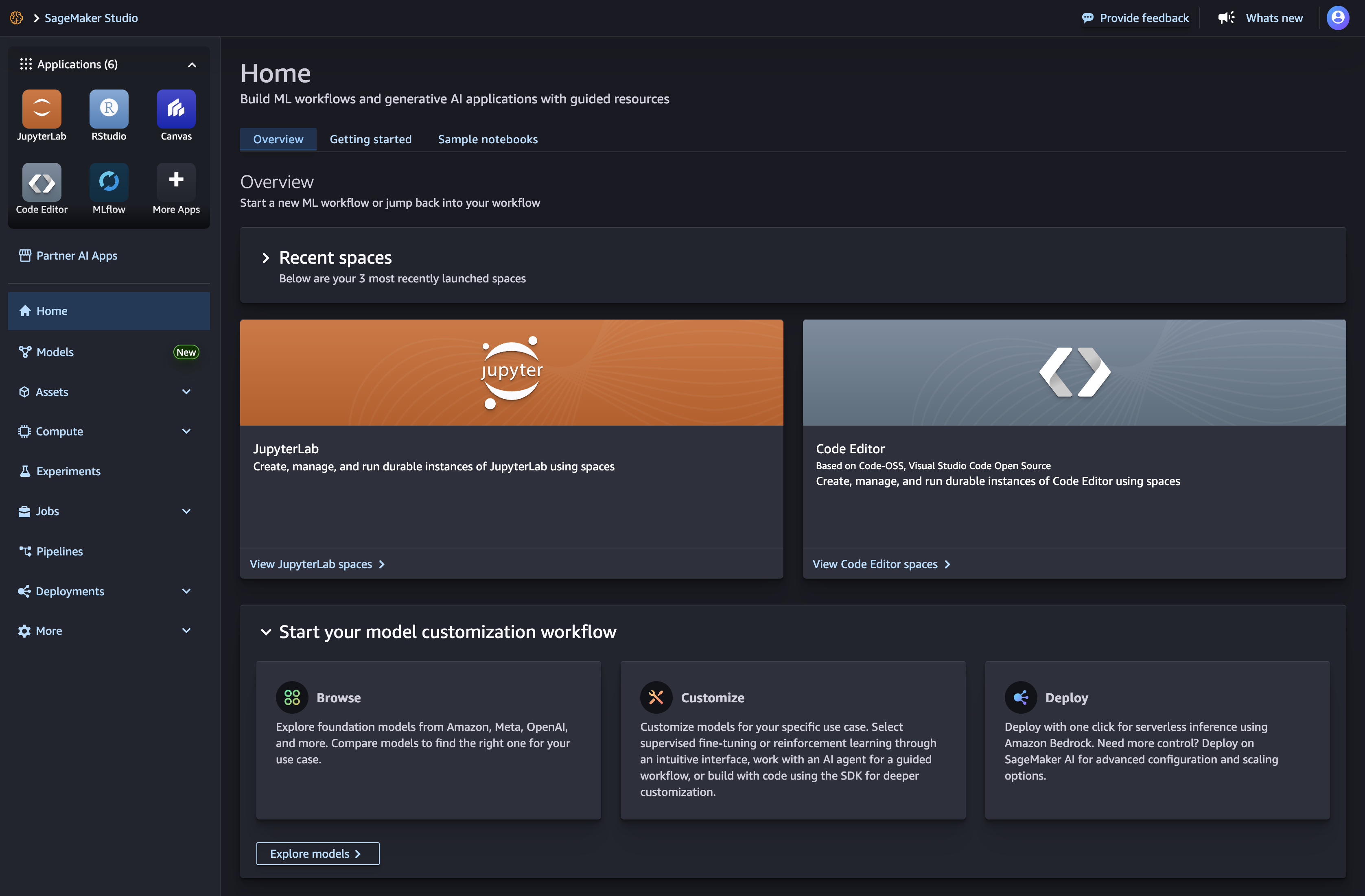
JumpStart 在工作室中打开
在 Amazon SageMaker Studio 中,通过主页或左侧面板中的演员项目打开演员登录页面。这将打开SageMaker 模型登录页面,您可以在其中浏览中的模型 SageMakerPublicHub、Private Hubs 或 Curated Hubs 中的模型以及自定义模型。
-
在主页上,在启动模型自定义工作流程窗格中选择浏览模型。
-
从左侧面板的菜单中导航到模型节点。
有关开始使用 Amazon SageMaker Studio 的更多信息,请参阅亚马逊 SageMaker Studio。
JumpStart 在工作室中使用
重要
在下载或使用第三方内容之前:您有责任查看和遵守任何适用的许可证条款,并确保您的使用案例可以接受这些条款。
3/132026 年 1 月,我们从 JumpStart 目录中删除了多个不同地区的模型,以提高可发现性,并专注于高质量、支持良好的选项。除名模型的现有端点将保持正常运行。有关已除名的开放式车型的许可信息,请参阅相应型号的 Hugging Face 清单。
在 Studio 的SageMaker 模型登录页面上,您可以浏览专有和公开模型提供商提供的 JumpStart 基础模型。您可以直接搜索模型,按特定模型提供商进行筛选,或者根据提供的用例和操作列表进行筛选。
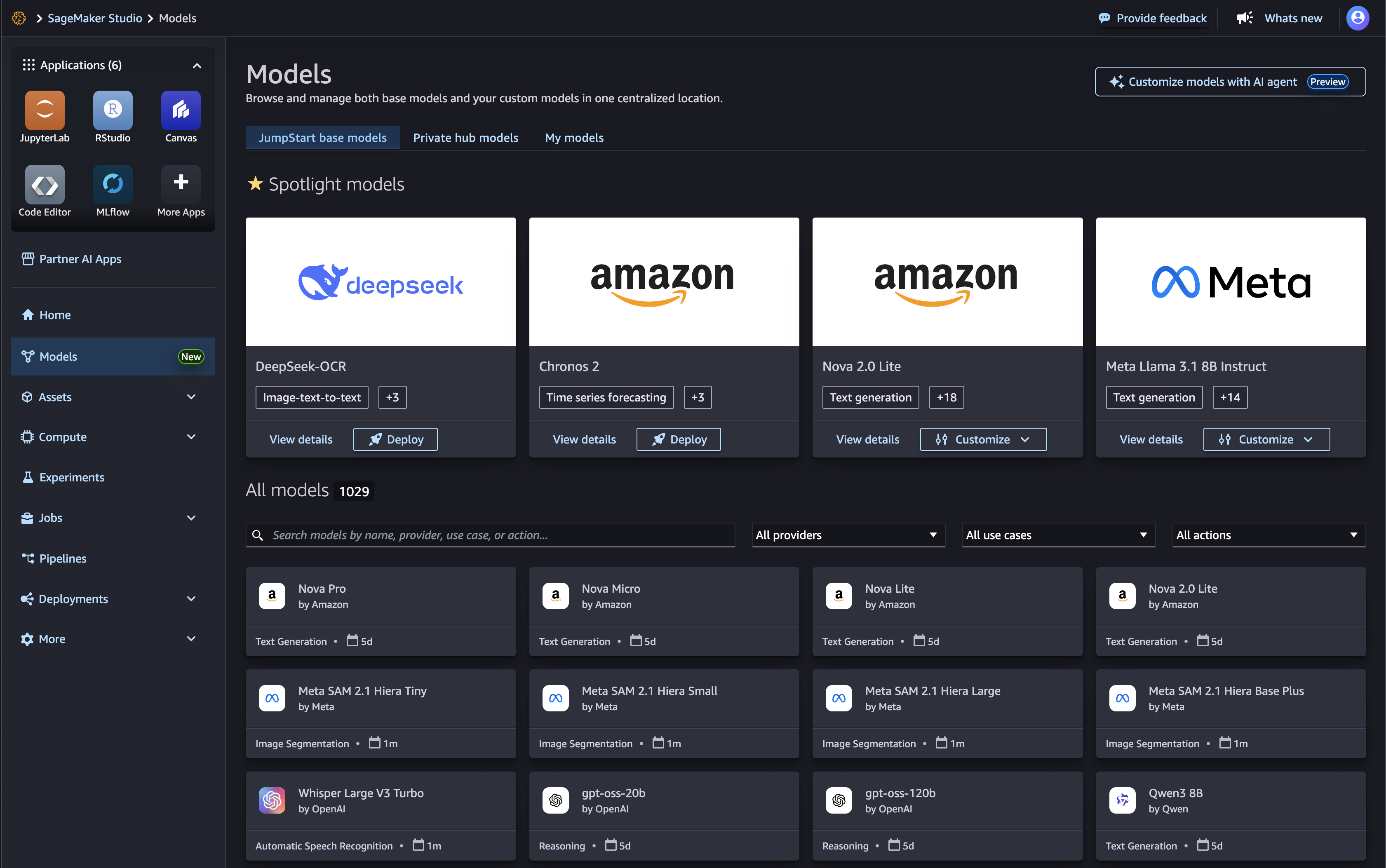
选择一个模型,查看其模型详情卡。在模型详细信息卡的右上角,选择 “Fine-tune自定义”、“部署” 或 “评估”,分别开始微调、部署或评估工作流程。请注意,并非所有型号都可用于定制、微调或评估。有关这些选项的更多信息,请参阅 在 Studio 中使用基础模型。
您还可以通过专用选项卡访问 “专用” 或 “策划中心” 模型。它们的工作原理与 JumpStart 基础模型完全一样,单击模型卡片将带您进入详细信息页面,那里有可用的操作。
此外,选择 “我的模型” 以访问经过微调和注册的模型。自定义作业的输出可以在此处的 “已记录的模型” 选项卡下找到。也可以在此处找到可@@ 部署的模型。
JumpStart 在 Studio 经典版中打开并使用
以下各节提供了有关如何通过 Amazon SageMaker Studio Classic 用户界面打开、使用和管理 JumpStart 的信息。
重要
截至 2023 年 11 月 30 日,之前的亚马逊 SageMaker Studio 体验现在被命名为 Amazon St SageMaker udio Classic。以下部分专门介绍如何使用 Studio Classic 应用程序。有关使用更新的 Studio 体验的信息,请参阅 亚马逊 SageMaker Studio。
Studio Classic 仍针对现有工作负载进行维护,但不再可供入门使用。您只能停止或删除现有的 Studio Classic 应用程序,不能创建新的应用程序。我们建议您将工作负载迁移到全新 Studio 体验。
JumpStart 在经典工作室中打开
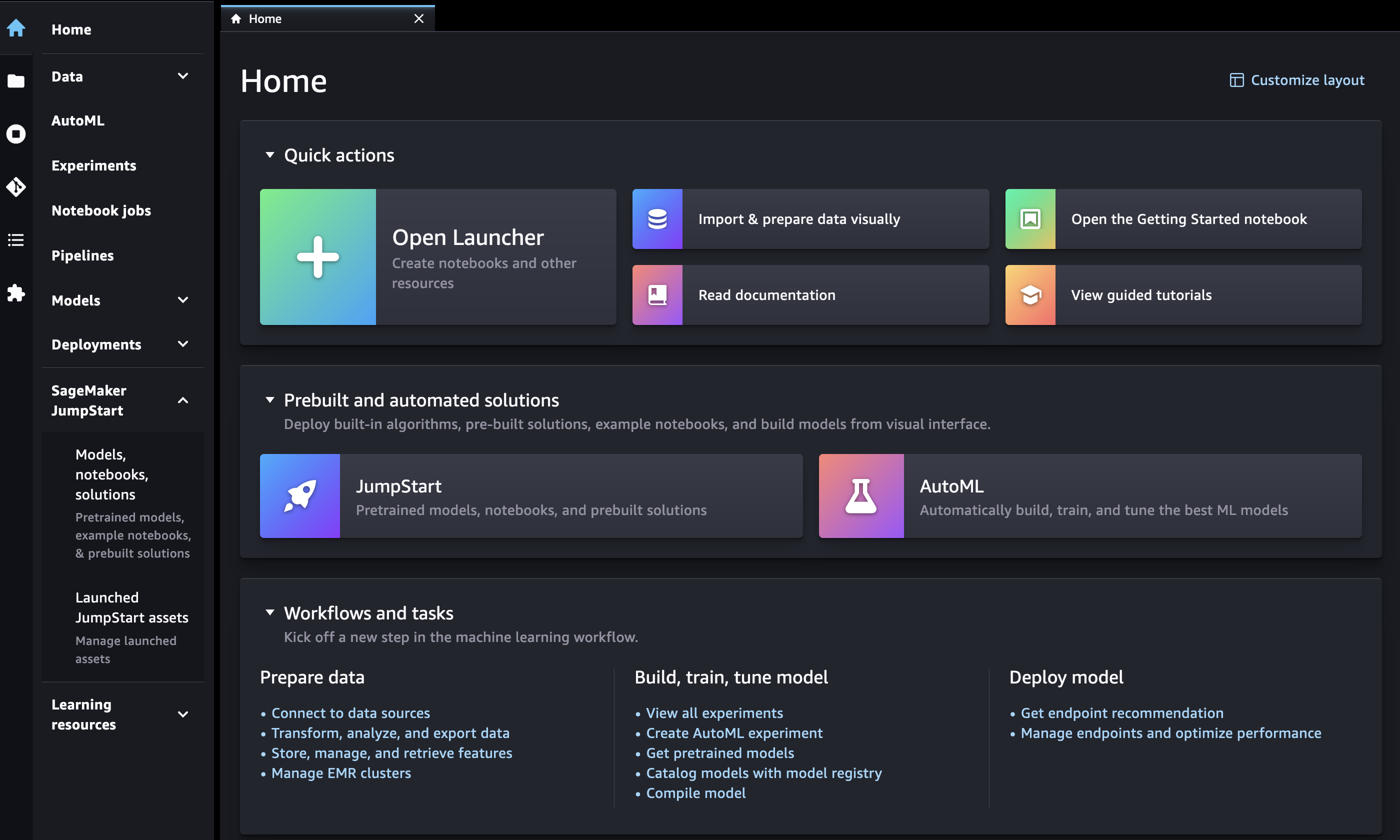
在 Amazon SageMaker Studio Classic 中,通过左侧面板上的主页或主页菜单打开 JumpStart 登录页面。
-
在主页上,您可以:
-
JumpStart在 “预构建和自动解决方案” 窗格中进行选择。这将打开SageMaker JumpStart登录页面。
-
直接在SageMaker JumpStart登录页面中选择一个模型,或者选择 “全部浏览” 选项以查看可用的解决方案或特定类型的模型。
-
-
在左侧面板的主页菜单中,您可以:
-
导航到SageMaker JumpStart节点,然后选择 “模型”、“笔记本”、“解决方案”。这将打开SageMaker JumpStart登录页面。
-
导航到该JumpStart节点,然后选择已启动的 JumpStart 资产。
已启动的 JumpStart 资产页面列出了您当前启动的解决方案、已部署的模型端点以及使用创建的训练作业 JumpStart。您可以通过单击该选项卡右上角的 “浏览 JumpStart” 按钮从该选项卡访问 JumpStart 登录页面。
-
JumpStart 登录页面列出了可用的端到端机器学习解决方案、预训练模型和示例笔记本。在任何单独的解决方案或模型页面中,您可以选择选项卡右上角的 “浏览” JumpStart 按钮 (
 ) 返回该SageMaker JumpStart页面。
) 返回该SageMaker JumpStart页面。
重要
在下载或使用第三方内容之前:您有责任查看和遵守任何适用的许可证条款,并确保您的使用案例可以接受这些条款。
3/132026 年 1 月,我们从 JumpStart 目录中删除了多个不同地区的模型,以提高可发现性,并专注于高质量、支持良好的选项。除名模型的现有端点将保持正常运行。有关已除名的开放式车型的许可信息,请参阅相应型号的 Hugging Face 清单。
JumpStart 在经典工作室中使用
在SageMaker JumpStart登录页面上,您可以浏览解决方案、型号、笔记本和其他资源。
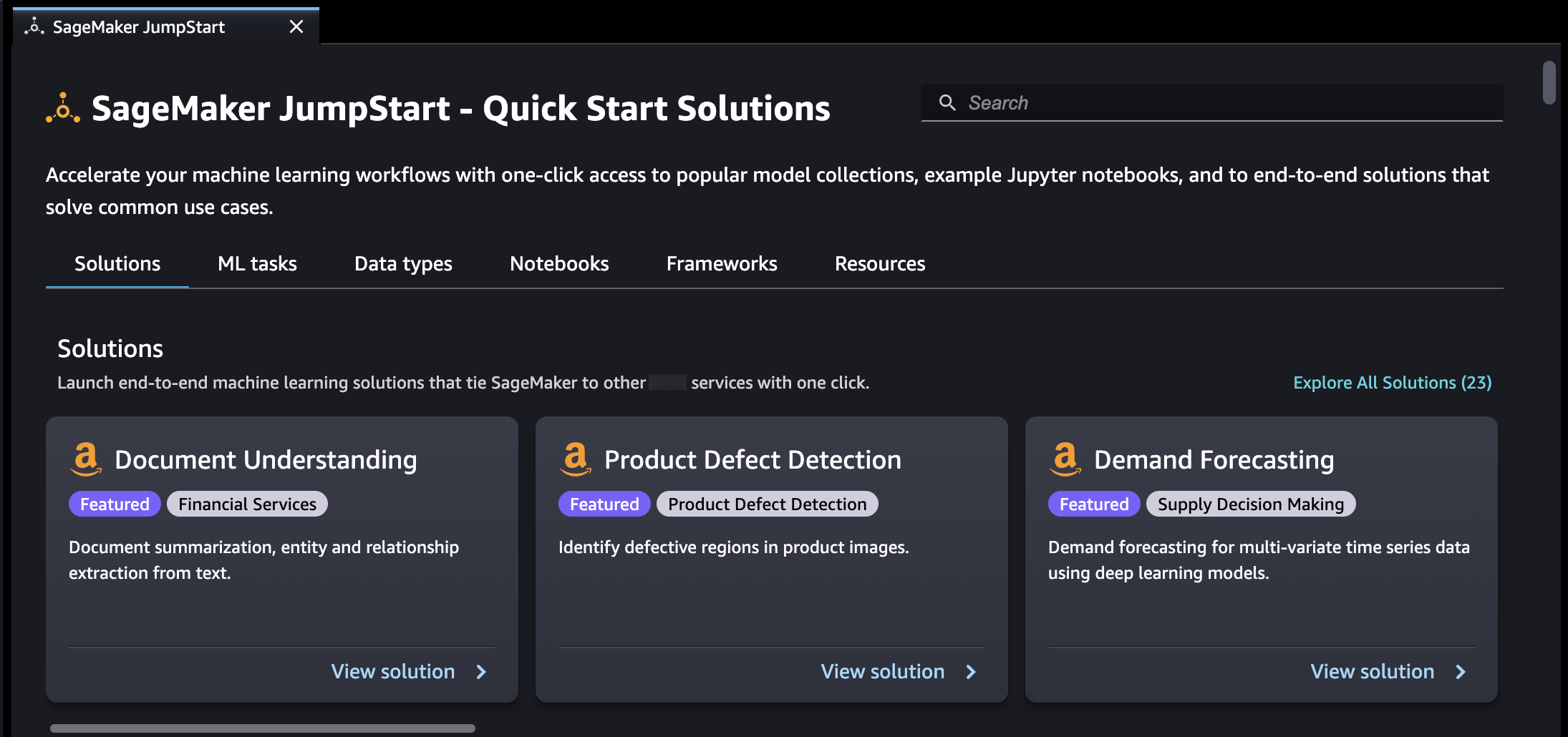
您可以使用搜索栏或浏览每个类别来查找 JumpStart 资源。使用选项卡按类别筛选可用的解决方案:
-
解决方案 — 只需一个步骤,即可启动将 SageMaker AI 与其他解决方案联系起来的全面机器学习解决方案 Amazon Web Services 服务。选择浏览所有解决方案以查看所有可用的解决方案。
-
资源 – 使用示例笔记本、博客和视频教程来了解和开始处理您的问题类型。
-
博客 – 阅读机器学习专家提供的详细信息和解决方案。
-
视频教程 — 观看来自机器学习专家的 SageMaker AI 功能和机器学习用例的视频教程。
-
示例笔记本 — 运行使用 SageMaker AI 功能(例如 Spot Instance 训练和实验)的示例笔记本,对各种模型类型和用例进行实验。
-
-
数据类型 – 按数据类型(例如,视觉、文本、表格、音频、文本生成)查找模型。选择浏览所有模型以查看所有可用的模型。
-
ML 任务 – 按问题类型(例如,图像分类、图像嵌入、对象检测、文本生成)查找模型。选择浏览所有模型以查看所有可用的模型。
-
笔记本电脑 — 查找在多种型号类型和用例中使用 SageMaker AI 功能的示例笔记本电脑。选择浏览所有笔记本以查看所有可用的示例笔记本。
-
框架 — 按框架查找模型(例如,, PyTorch TensorFlow,Hugging Face)。
使用 Stud JumpStart io 经典版管理
在左侧面板的主页菜单中,导航到 SageMaker JumpStart,然后选择已启动的 JumpStart 资源,以列出您当前启动的解决方案、部署的模型端点以及使用创建的训练作业 JumpStart。