本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用筛选条件表达式
使用筛选条件表达式 查看特定请求、服务、两个服务之间的连接(边缘)或满足某个条件的请求的跟踪地图或跟踪。X-Ray 提供筛选表达式语言,根据原始段上请求标头、响应状态和索引字段中的数据筛选请求、服务和边缘。
当您选择某个跟踪时间段以在 X-Ray 控制台中查看时,您获得的结果可能会超出可在控制台中显示的内容。在右上角,控制台显示其扫描的跟踪数量,以及是否有更多跟踪可用。您可以使用筛选条件表达式缩小结果范围,以仅限于您要查找的跟踪。
筛选条件表达式详细信息
当您选择跟踪地图中的节点时,控制台会基于该节点的服务名称以及您的选择中提供的错误类型,来构建筛选条件表达式。要查找显示性能问题的跟踪或与特定请求相关的跟踪,可以调整控制台提供的表达式,或创建您自己的表达式。如果您使用 X-Ray SDK 添加注释,您还可以根据是否存在注释键或根据键值进行筛选。
注意
如果您在跟踪地图中选择相对时间范围并选择一个节点,则控制台会将时间范围转换为绝对开始和结束时间。为了确保节点的跟踪显示在搜索结果中,并避免扫描时间在该节点未处于活动状态的期间内,时间范围只应包含该节点发送跟踪的时间。若要相对于当前时间进行搜索,您可以在跟踪页面中切换回相对时间范围,并重新扫描。
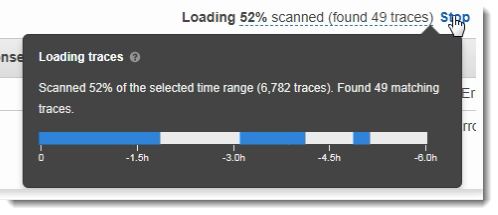
如果结果仍超过控制台可显示的内容,控制台会显示有多少个跟踪匹配,以及扫描的跟踪数。显示的百分比是已扫描选定时间范围的百分比。为确保您会看到在结果中提供所有匹配的跟踪,进一步缩小筛选条件表达式的范围,或选择一个更短的时间范围。
为了先获取最新结果,控制台会从时间范围结尾开始反向扫描。如果有大量的跟踪,但结果很少,控制台会将时间范围分为多个分块并执行并行扫描。进度条显示已扫描的时间范围部分。
将筛选条件表达式与组一起使用
组是由筛选条件表达式定义的跟踪的集合。您可以使用群组来生成其他服务图表并提供 Amazon CloudWatch 指标。
组由其名称或 Amazon 资源名称(ARN)标识,并包含筛选条件表达式。此服务将比较传入到表达式的跟踪并相应地存储它们。
您可以使用筛选条件表达式搜索栏左侧的下拉菜单创建和修改组。
注意
如果服务在限定组时遇到错误,则在处理传入跟踪时不再包含该组,并记录错误指标。
有关组的更多信息,请参阅 配置组。
筛选条件表达式语法
筛选条件表达式可以包含一个关键字、一个一元或二元运算符 和一个值 用于比较。
keyword operator value不同的运算符可用于不同类型的关键字。例如,responsetime 是一个数字关键字,可与数字相关运算符进行比较。
例- 响应时间超过 5 秒的请求
responsetime > 5您可以使用 AND 或 OR 运算符将多个表达式组合成一个复合表达式。
例- 总时长在 5-8 秒之间的请求
duration >= 5 AND duration <= 8简单的关键字和运算符只在跟踪级别查找问题。如果下游发生了错误,但被您的应用程序处理了而未返回给用户,则搜索 error 将找不到它。
要查找下游问题的跟踪,可以使用复杂关键字 service() 和 edge()。这些关键字允许您将筛选条件表达式应用于所有下游节点、单个下游节点或两个节点之间的边缘。要想获得更细的粒度,您可以使用 id() 函数按类型筛选服务和边缘。
布尔值关键字
布尔关键字值可为 true 或 false。使用这些关键字查找导致错误的跟踪。
布尔值关键字
-
ok- 响应状态代码为 2XX,成功。 -
error- 响应状态代码为 4XX,客户端错误。 -
throttle- 响应状态代码为“429 请求过多”。 -
fault- 响应状态代码为 5XX,服务器错误。 -
partial- 请求包含未完成的分段。 -
inferred- 请求具有推断分段。 -
first- 元素是枚举列表中的第一个元素。 -
last- 元素是枚举列表中的最后一个元素。 -
remote- 根本原因实体是远程的。 -
root- 服务是跟踪的入口点或根分段。
布尔运算符查找指定键为 true 或 false 的分段。
布尔运算符
-
none - 如果关键字为 true,则表达式为 true。
-
!- 如果关键字为 false,则表达式为 true。 -
=、!=- 将关键字的值与字符串true或false进行比较。这些运算符与其他运算符的行为相同,但更加明确。
例- 响应状态为 2XX OK
ok例- 响应状态不为 2XX OK
!ok例- 响应状态不为 2XX OK
ok = false例- 上次枚举的错误跟踪具有错误名称“deserialize”
rootcause.fault.entity { last and name = "deserialize" }例- 包含远程分段的请求,其覆盖率大于 0.7 且服务名称为“traces”
rootcause.responsetime.entity { remote and coverage > 0.7 and name = "traces" }例- 具有推断分段(其中,服务类型为“AWS:DynamoDB”)的请求
rootcause.fault.service { inferred and name = traces and type = "AWS::DynamoDB" }例- 将名称为“data-plane”的分段用作根的请求
service("data-plane") {root = true and fault = true}数字关键字
使用数字关键字可以搜索具有特定响应时间、持续时间或响应状态的请求。
数字关键字
-
responsetime- 服务器发送响应所用的时间。 -
duration- 包括所有下游调用的请求总时长。 -
http.status- 响应(状态代码)。 -
index- 元素在枚举列表中的位置。 -
coverage- 实体响应时间占根分段响应时间的小数百分比。仅适用于响应时间根本原因实体。
数字运算符
数字关键字使用标准相等运算符和比较运算符。
-
=、!=- 关键字等于或不等于某个数值。 -
<、<=、>、>=- 关键字小于或大于某个数值。
例- 响应状态不为 200 OK
http.status != 200例- 总时长在 5-8 秒之间的请求
duration >= 5 AND duration <= 8例- 在 3 秒内成功完成的请求,包括所有下游调用
ok !partial duration <3例- 索引大于 5 的枚举列表实体
rootcause.fault.service { index > 5 }例- 其最后一个实体覆盖率大于 0.8 的请求
rootcause.responsetime.entity { last and coverage > 0.8 }字符串关键字
使用字符串关键字查找请求标头中包含特定文本或特定用户的跟踪 IDs。
字符串关键字
-
http.url- 请求 URL。 -
http.method- 请求方法。 -
http.useragent- 请求的用户代理字符串。 -
http.clientip- 请求者 IP 地址。 -
user- 跟踪中任意分段的用户字段的值。 -
name- 服务或异常的名称。 -
type- 服务类型。 -
message- 异常消息。 -
availabilityzone- 跟踪中任意分段上可用区字段的值。 -
instance.id- 跟踪中任意分段上的实例 ID 字段的值。 -
resource.arn- 跟踪中任何分段上的资源 ARN 字段的值。
字符串运算符查找等于或包含特定文本的值。必须始终在引号中指定值。
字符串运算符
-
=、!=- 关键字等于或不等于某个数值。 -
CONTAINS- 关键字包含特定字符串。 -
BEGINSWITH、ENDSWITH- 关键字以特定字符串开头或结尾。
例- http.url 筛选器
http.url CONTAINS "/api/game/"要测试跟踪中是否存在某个字段而不考虑其值,可检查它是否包含空字符串。
例- 用户筛选器
与用户一起查找所有痕迹 IDs。
user CONTAINS ""例- 选择跟踪,跟踪所具有的故障根本原因包含名为“Auth”的服务
rootcause.fault.service { name = "Auth" }例- 选择跟踪,跟踪所具有的响应时间根本原因的最后一个服务的类型为 DynamoDB
rootcause.responsetime.service { last and type = "AWS::DynamoDB" }例- 选择跟踪,跟踪所具有的故障根本原因的最后一个异常具有消息“拒绝 account_id 访问:1234567890”
rootcause.fault.exception { last and message = "Access Denied for account_id: 1234567890" 复杂关键字
使用复杂关键字可根据服务名称、边缘节点名称或注释值查找请求。对于服务和边缘节点,您可以指定应用于服务或边缘节点的附加筛选条件表达式。对于注释,您可以使用布尔值、数字或字符串运算符筛选具有特定键的注释的值。
复杂关键字
-
annotation[-带字段的注释的值key]key。注释的值可以是布尔值、数字或字符串,因此您可以使用任意这些类型的比较运算符。此关键字可以与service或edge关键字组合使用。包含点(句点)的注释键必须用方括号([])括住。 -
edge(—服务source,destination) {filter}source与之间的连接destination. 可选的大括号中可以包含应用于此连接上的分段的筛选条件表达式。 -
group.— 组的筛选条件表达式的值,被组名称或组 ARN 所引用。name/ group.arn -
json- JSON 根本原因对象。有关以编程方式创建 JSON 实体的步骤,请参阅从 Amazon X-Ray 获取数据。 -
service(— 带有名称的服务name) {filter}name。可选的大括号中可以包含应用于服务所创建的分段的筛选条件表达式。
使用服务关键字查找命中跟踪地图上特定节点的请求的跟踪。
复杂关键字运算符可查找其中的指定键已经设置或未设置的分段。
复杂关键字运算符
-
none - 如果关键字已经设置,则表达式为 true。如果关键字为布尔类型,则其计算结果将为布尔值。
-
!- 如果关键字未设置,则表达式为 true。如果关键字为布尔类型,则其计算结果将为布尔值。 -
=、!=— 比较关键字的值。 -
edge(—服务source,destination) {filter}source与之间的连接destination. 可选的大括号中可以包含应用于此连接上的分段的筛选条件表达式。 -
annotation[-带字段的注释的值key]key。注释的值可以是布尔值、数字或字符串,因此您可以使用任意这些类型的比较运算符。此关键字可以与service或edge关键字组合使用。 -
json- JSON 根本原因对象。有关以编程方式创建 JSON 实体的步骤,请参阅从 Amazon X-Ray 获取数据。
使用服务关键字查找命中跟踪地图上特定节点的请求的跟踪。
例- 服务筛选器
包括对 api.example.com 调用的请求出错 (500 系列错误)。
service("api.example.com") { fault }您可以排除服务名称,而将筛选条件表达式应用于服务地图上的所有节点。
例- 服务筛选器
在跟踪地图上的任意位置导致故障的请求。
service() { fault }边缘关键字将筛选条件表达式应用于两个节点之间的连接。
例- 边缘筛选器
服务 api.example.com 对 backend.example.com 进行调用的请求因出现错误而失败。
edge("api.example.com", "backend.example.com") { error }您也可以将 ! 运算符与服务和边缘关键字结合使用来从另一个筛选条件表达式的结果中排除某个服务或边缘。
例- 服务和请求筛选器
请求的 URL 以 http://api.example.com/ 开头且包含 /v2/,但并未到达名为 api.example.com 的服务。
http.url BEGINSWITH "http://api.example.com/" AND http.url CONTAINS "/v2/" AND !service("api.example.com")例— 服务和响应时间筛选器
查找已设置 http url 且呼应时间大于 2 秒的跟踪。
http.url AND responseTime > 2对于注释,您可以调用设置了 annotation[ 的所有跟踪,或使用对应于值的类型的比较运算符。key]
例- 带字符串值的注释
请求的注释名为 gameid,字符串值为 "817DL6VO"。
annotation[gameid] = "817DL6VO"例— 注释已设置
带有名称设置为 age 的注释的请求。
annotation[age]例— 注释未设置
不带有名称设置为 age 的注释的请求。
!annotation[age]例- 带数字值的注释
请求的注释期限数值大于 29。
annotation[age] > 29例— 注释与服务或边缘相结合
service { annotation[request.id] = "917DL6VO" }edge { source.annotation[request.id] = "916DL6VO" }edge { destination.annotation[request.id] = "918DL6VO" }例— 带有用户的组
其的跟踪满足 high_response_time 组筛选条件(例如,responseTime > 3),且用户名为“Alice”的请求。
group.name = "high_response_time" AND user = "alice"例- 具有根本原因实体的 JSON
具有匹配的根本原因实体的请求。
rootcause.json = #[{ "Services": [ { "Name": "GetWeatherData", "EntityPath": [{ "Name": "GetWeatherData" }, { "Name": "get_temperature" } ] }, { "Name": "GetTemperature", "EntityPath": [ { "Name": "GetTemperature" } ] } ] }]id 函数
当您为 service 或 edge 关键字提供服务名称时,您将得到具有该名称的所有节点的结果。要进行更精确的筛选,可以使用 id 函数在名称之外再指定一个服务类型,以区分同名节点。
在监控账户中查看多个账户中的跟踪时,使用 account.id 函数为服务指定一个具体账户。
id(name: "service-name", type:"service::type", account.id:"account-ID")您可以在服务和边缘节点筛选条件中使用 id 函数来代替服务名称。
service(id(name: "service-name", type:"service::type")) { filter }edge(id(name: "service-one", type:"service::type"), id(name: "service-two", type:"service::type")) { filter }例如, Amazon Lambda 函数会在跟踪映射中生成两个节点;一个用于函数调用,另一个用于 Lambda 服务。两个节点的名称相同,但类型不同。标准服务筛选器将查找这两个节点的跟踪。
例- 服务筛选器
在任何名为 random-name的服务上包含错误的请求。
service("random-name") { error }使用 id 函数将搜索范围缩小到函数本身的错误,排除服务的错误。
例- 使用 id 函数的服务筛选器
名为 random-name、类型为 AWS::Lambda::Function 的服务中有错误的请求。
service(id(name: "random-name", type: "AWS::Lambda::Function")) { error }要按类型搜索节点,您还可以完全排除名称。
例— 具有 id 函数和服务类型的服务筛选器
类型为 AWS::Lambda::Function 的服务中有错误的请求。
service(id(type: "AWS::Lambda::Function")) { error }要搜索特定节点 Amazon Web Services 账户,请指定账户 ID。
例- 具有 id 函数和账户 ID 的服务筛选器
包含某个特定账户 ID AWS::Lambda::Function 中某项服务的请求。
service(id(account.id: "account-id"))