本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
亚马逊中的亚马逊 A SageMaker I 指标 CloudWatch
您可以使用 Amazon 监控 Amazon A SageMaker I CloudWatch,亚马逊会收集原始数据并将其处理为可读的近乎实时的指标。这些统计数据保存 15 个月。利用它们,您就可以访问历史信息,更好地了解网络应用程序或服务的运行情况。但是,Amazon CloudWatch 控制台将搜索范围限制在过去 2 周内更新的指标。此限制可确保显示您命名空间中最新的作业。
要列出指标图形而不使用搜索,请在源视图中指定其确切名称。还可以设置特定阈值监视警报,在达到对应阈值时发送通知或采取行动。有关更多信息,请参阅 Amazon CloudWatch 用户指南。
SageMaker AI 指标和维度
SageMaker AI 终端节点指标
/aws/sagemaker/Endpoints命名空间包括终端节点实例的以下指标。
指标按 1 分钟一次的频率提供。
注意
Amazon CloudWatch 支持高分辨率的自定义指标,其最佳分辨率为 1 秒。但是,分辨率越高, CloudWatch 指标的寿命越短。对于 1 秒频率分辨率,这些 CloudWatch 指标的可用时间为 3 小时。有关分辨率和 CloudWatch 指标寿命的更多信息,请参阅 Amazon CloudWatch API 参考GetMetricStatistics中的。
| 指标 | 说明 |
|---|---|
CPUReservation |
容器在实例上 CPUs 预留的总和。 此指标仅适用于托管主动推理组件的端点。 数值范围在 0%-100% 之间。在推理组件的设置中,您可以使用 |
CPUUtilization |
每个单独的 CPU 核心利用率的总和。每个核心的 CPU 利用率范围均为 0 – 100。例如,如果有四个 CPUs,则 对于端点变体,该值是实例上的主容器和辅助容器的 CPU 利用率的总和。 单位:百分比 |
CPUUtilizationNormalized |
每个 CPU 内核利用率的标准化总和。 此指标仅适用于托管主动推理组件的端点。 数值范围在 0%-100% 之间。例如,如果有四个 CPUs, |
DiskUtilization |
实例上容器所使用的磁盘空间的百分比。此值范围为 0%–100%。 对于端点变体,该值是实例上的主容器和辅助容器的磁盘空间利用率的总和。单位:百分比 |
GPUMemoryUtilization |
实例上的容器所使用的 GPU 内存的百分比。值范围为 0—100,并乘以数字。 GPUs例如,如果有四个 GPUs,则 对于端点变体,该值是实例上的主容器和辅助容器的 GPU 内存利用率的总和。 单位:百分比 |
GPUMemoryUtilizationNormalized |
实例上的容器所使用的 GPU 内存的标准化百分比。 此指标仅适用于托管主动推理组件的端点。 数值范围在 0%-100% 之间。例如,如果有四个 GPUs, |
GPUReservation |
容器在实例上 GPUs 预留的总和。 此指标仅适用于托管主动推理组件的端点。 数值范围在 0%-100% 之间。在推理组件的设置中,您可以通过 |
GPUUtilization |
实例上的容器所使用的 GPU 单位的百分比。该值的范围可以介于 0—100 之间,并乘以的数量。 GPUs例如,如果有四个 GPUs,则 对于端点变体,该值是实例上的主容器和辅助容器的 GPU 利用率的总和。 单位:百分比 |
GPUUtilizationNormalized |
实例上的容器使用 GPU 单位的标准化百分比。 此指标仅适用于托管主动推理组件的端点。 数值范围在 0%-100% 之间。例如,如果有四个 GPUs, |
MemoryReservation |
容器在实例上保留的内存总和。 此指标仅适用于托管主动推理组件的端点。 数值范围在 0%-100% 之间。在推理组件的设置中,您可以使用 |
MemoryUtilization |
实例上的容器所使用的内存的百分比。此值范围为 0% – 100%。 对于端点变体,该值是实例上的主容器和辅助容器的内存利用率的总和。 单位:百分比 |
| 维度 | 说明 |
|---|---|
EndpointName, VariantName |
筛选指定端点和变体的终端节点指标。 |
SageMaker AI 终端节点调用指标
AWS/SageMaker 命名空间包含通过调用 InvokeEndpoint 获得的以下请求指标。
指标按 1 分钟一次的频率提供。
下图显示了 SageMaker AI 终端节点如何与 Amazon SageMaker Runtime API 交互。从向端点发送请求到收到响应之间的总时间长度取决于以下三个组成部分。
-
网络延迟 — 从向 Runtime Runt SageMaker ime API 发出请求到收到回复所花费的时间。
-
开销延迟 — 将请求从模型容器传输到模型容器并将响应传输回 SageMaker 运行时运行时 API 所花费的时间。
-
模型延迟 – 模型容器处理请求并返回响应所花费的时间。
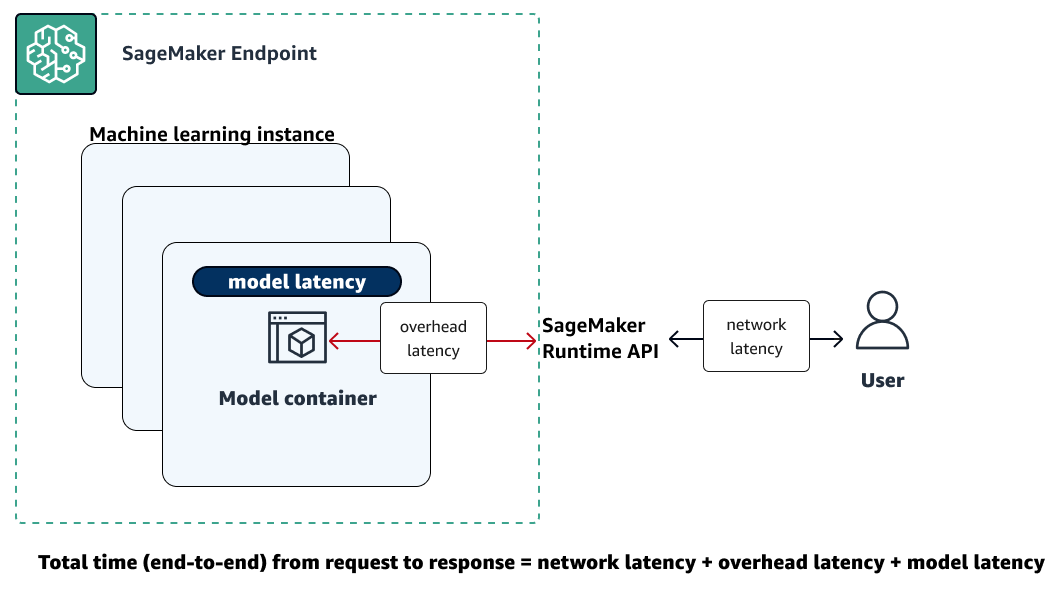
有关总延迟的更多信息,请参阅负载测试 Amazon A SageMaker I 实时推理终端节点的最佳实践
| 指标 | 说明 |
|---|---|
ConcurrentRequestsPerCopy |
推理组件收到的并发请求数,按推理组件的每个副本进行标准化处理。 有效统计数据:最小值、最大值 |
ConcurrentRequestsPerModel |
模型收到的并发请求数。 有效统计数据:最小值、最大值 |
Invocation4XXErrors |
模型在其中返回 4xx HTTP 响应代码的 单位:无 有效统计数据:Average、Sum |
Invocation5XXErrors |
模型在其中返回 5xx HTTP 响应代码的 单位:无 有效统计数据:Average、Sum |
InvocationModelErrors |
未导致 2XX HTTP 响应的模型调用请求的数量。这包括 4XX/5XX 状态代码、低级套接字错误、格式错误的 HTTP 响应和请求超时。对于每个错误响应,发送 1;否则,发送 0。 单位:无 有效统计数据:Average、Sum |
Invocations |
发送到模型端点的 要获取发送到模型端点的请求总数,请使用 Sum 统计数据。 单位:无 有效统计数据:Sum |
InvocationsPerCopy |
按推理组件每个副本标准化的调用次数。 有效统计数据:Sum |
InvocationsPerInstance |
发送到模型的调用次数,按 单位:无 有效统计数据:Sum |
ModelLatency |
模型响应 SageMaker 运行时 API 请求所用的时间间隔。此时间间隔包括发送请求以及从模型容器提取响应的本地通信时间。它还包括在容器中完成推理所需的时间。 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count、Percentiles |
ModelSetupTime |
为无服务器端点启动新的计算资源所花费的时间。时间可能会有所不同,具体取决于模型大小、下载模型所需的时间以及容器的启动时间。 单位:微秒 有效统计数据:Average、Min、Max、Sample Count、Percentiles |
OverheadLatency |
SageMaker AI 管理费用加上响应客户请求所花费的时间间隔。此间隔是从 SageMaker AI 收到请求到向客户端返回响应的时间减去 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count |
MidStreamErrors
|
在向客户发送初始响应后,在响应流中发生的错误数量。 单位:无 有效统计数据:Average、Sum |
FirstChunkLatency
|
从请求到达 SageMaker AI 端点到将响应的第一部分发送给客户所经过的时间。该指标适用于双向流式推理请求。 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count、Percentiles |
FirstChunkModelLatency
|
模型容器处理请求并返回响应的第一块所花费的时间。这是从请求发送到模型容器直到从模型收到第一个字节开始计算的。该指标适用于双向流式推理请求。 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count、Percentiles |
FirstChunkOverheadLatency
|
第一个区块的开销延迟,不包括模型处理时间。计算 单位:微秒 有效统计数据:平均值、总和、最小值、最大值、样本数、百分位数 |
| 维度 | 说明 |
|---|---|
EndpointName, VariantName |
针对指定端点和变体的 |
InferenceComponentName |
筛选推理组件调用指标。 |
SageMaker AI 推理组件指标
/aws/sagemaker/InferenceComponents命名空间包括以下指标,这些指标来自 InvokeEndpoint对托管推理组件的端点的调用。
指标按 1 分钟一次的频率提供。
| 指标 | 说明 |
|---|---|
CPUUtilizationNormalized |
每个推理组件副本报告的 |
GPUMemoryUtilizationNormalized |
每个推理组件副本报告的 |
GPUUtilizationNormalized |
每个推理组件副本报告的 |
MemoryUtilizationNormalized |
每个推理组件副本报告的 |
| 维度 | 说明 |
|---|---|
InferenceComponentName |
筛选推理组件指标。 |
SageMaker AI 多模型终端节点指标
AWS/SageMaker命名空间包括以下模型从对的调用加载指标 InvokeEndpoint。
指标按 1 分钟一次的频率提供。
有关 CloudWatch 指标保留多长时间的信息,请参阅 Amazon CloudWatch API 参考GetMetricStatistics中的。
| 指标 | 说明 |
|---|---|
ModelLoadingWaitTime |
调用请求等待下载、加载或同时下载、加载目标模型以运行推理的时间间隔。 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count |
ModelUnloadingTime |
通过容器的 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count |
ModelDownloadingTime |
从 Amazon Simple Storage Service (Amazon S3) 下载模型所花费的时间间隔。 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count |
ModelLoadingTime |
通过容器的 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count |
ModelCacheHit |
发送到已加载模型的多模型端点的 “Average”统计数据显示已加载模型的请求的比率。 单位:无 有效统计数据:Average、Sum、Sample Count |
| 维度 | 说明 |
|---|---|
EndpointName, VariantName |
针对指定端点和变体的 |
/aws/sagemaker/Endpoints 命名空间包含通过调用 InvokeEndpoint 获得的以下实例指标。
指标按 1 分钟一次的频率提供。
有关 CloudWatch 指标保留多长时间的信息,请参阅 Amazon CloudWatch API 参考GetMetricStatistics中的。
| 指标 | 说明 |
|---|---|
LoadedModelCount |
多模型端点的容器中加载的模型数。此指标是按实例发射的。 周期为 1 分钟的“Average”统计数据指示每个实例加载的平均模型数。 “Sum”统计数据指示在端点中的所有实例上加载的模型总数。 此指标跟踪的模型不一定是唯一的,因为可能在端点的多个容器中加载模型。 单位:无 有效统计数据:Average、Sum、Min、Max、Sample Count |
| 维度 | 说明 |
|---|---|
EndpointName, VariantName |
针对指定端点和变体的 |
SageMaker AI 工作指标
/aws/sagemaker/ProcessingJobs/aws/sagemaker/TrainingJobs、和/aws/sagemaker/TransformJobs命名空间包括以下处理作业、训练作业和批处理转换作业的指标。
指标按 1 分钟一次的频率提供。
注意
Amazon CloudWatch 支持高分辨率的自定义指标,其最佳分辨率为 1 秒。但是,分辨率越高, CloudWatch 指标的寿命越短。对于 1 秒频率分辨率,这些 CloudWatch 指标的可用时间为 3 小时。有关分辨率和 CloudWatch 指标寿命的更多信息,请参阅 Amazon CloudWatch API 参考GetMetricStatistics中的。
提示
要以更精细的分辨率分析您的训练作业,精度低至 100 毫秒(0.1 秒),并将训练指标无限期存储在 Amazon S3 中以便随时进行自定义分析,请考虑使用 Amazon Debugger。 SageMaker SageMaker Debugger 提供内置规则来自动检测常见的训练问题。它可以检测硬件资源利用率问题(例如 CPU、GPU 和 I/O 瓶颈)。它还能检测非收敛模型问题(如过拟合、梯度消失和张量爆炸)。 SageMaker 调试器还通过 Studio Classic 及其分析报告提供可视化效果。要探索调试器可视化效果,请参阅 D SageMaker ebugger Insights 仪表板演练、调试器分析报告演练和使用客户端库分析数据。 SMDebug
| 指标 | 说明 |
|---|---|
CPUUtilization |
每个单独的 CPU 核心利用率的总和。每个核心的 CPU 利用率范围均为 0 – 100。例如,如果有四个 CPUs,则CPUUtilization范围为 0% — 400%。对于处理作业,该值是实例上的处理容器的 CPU 利用率。对于训练作业,该值是实例上的算法容器的 CPU 利用率。 对于批量转换作业,该值是实例上的转换容器的 CPU 利用率。 注意对于多实例作业,每个实例都会报告 CPU 利用率指标。但是,中的默认视图 CloudWatch 显示了所有实例的平均 CPU 使用率。 单位:百分比 |
DiskUtilization |
实例上容器所使用的磁盘空间的百分比。此值范围为 0%–100%。批量转换作业不支持此指标。 对于处理作业,该值是实例上的处理容器的磁盘空间利用率。对于训练作业,该值是实例上的算法容器的磁盘空间利用率。 单位:百分比 注意对于多实例作业,每个实例都会报告磁盘利用率指标。但是,中的默认视图 CloudWatch 显示了所有实例的平均磁盘利用率。 |
GPUMemoryUtilization |
实例上的容器所使用的 GPU 内存的百分比。值范围为 0—100,并乘以数字。 GPUs例如,如果有四个 GPUs,则 对于训练作业,该值是实例上的算法容器的 GPU 内存利用率。 对于批量转换作业,该值是实例上的转换容器的 GPU 内存利用率。 注意对于多实例作业,每个实例都会报告 GPU 内存利用率指标。但是,中的默认视图 CloudWatch 显示了所有实例的平均 GPU 内存使用率。 单位:百分比 |
GPUUtilization |
实例上的容器所使用的 GPU 单位的百分比。该值的范围可以介于 0—100 之间,并乘以的数量。 GPUs例如,如果有四个 GPUs,则 对于训练作业,该值是实例上的算法容器的 GPU 利用率。 对于批量转换作业,该值是实例上的转换容器的 GPU 利用率。 注意对于多实例作业,每个实例都会报告 GPU 利用率指标。但是,中的默认视图 CloudWatch 显示了所有实例的平均 GPU 使用率。 单位:百分比 |
MemoryUtilization |
实例上的容器所使用的内存的百分比。此值范围为 0%–100%。 对于处理作业,该值是实例上的处理容器的内存利用率。对于训练作业,该值是实例上的算法容器的内存利用率。 对于批量转换作业,该值是实例上的转换容器的内存利用率。 单位:百分比 注意对于多实例作业,每个实例都会报告内存利用率指标。但是,中的默认视图 CloudWatch 显示了所有实例的平均内存使用率。 |
| 维度 | 说明 |
|---|---|
Host |
对于处理作业,该维度的值具有格式 对于训练作业,该维度的值具有格式 对于批量转换作业,该维度的值的格式为 |
SageMaker 推理推荐人作业指标
/aws/sagemaker/InferenceRecommendationsJobs 命名空间包括推理推荐系统作业的以下指标。
| 指标 | 说明 |
|---|---|
ClientInvocations |
Inference Recommender 观察到的发送到模型端点的 单位:无 有效统计数据:Sum |
ClientInvocationErrors |
Inference Recommender 观察到的失败的 单位:无 有效统计数据:Sum |
ClientLatency |
Inference Recommender 观察到的从发送 单位:毫秒 有效统计数据:Average、Sum、Min、Max、Sample Count、Percentiles |
NumberOfUsers |
向模型端点发送 单位:无 有效统计数据:Max、Min、Average |
| 维度 | 说明 |
|---|---|
JobName |
筛选指定 Inference Recommender 作业的 Inference Recommender 作业指标。 |
EndpointName |
筛选指定端点的 Inference Recommender 作业指标。 |
SageMaker Ground Truth 指标
| 指标 | 说明 |
|---|---|
ActiveWorkers |
专有工作团队中的一名活跃工作人员已提交、发布或拒绝了任务。要获取活跃工作人员的总数,请使用 Sum 统计数据。Ground Truth 会尝试将每个单独的 单位:无 有效统计数据:Sum、Sample Count |
DatasetObjectsAutoAnnotated |
在标注作业中自动注释的数据集对象数。此指标仅在启用自动标记时发出。要查看标注作业进度,请使用 Max 指标。 单位:无 有效统计数据:Max |
DatasetObjectsHumanAnnotated |
在标注作业中人工注释的数据集对象数。要查看标注作业进度,请使用 Max 指标。 单位:无 有效统计数据:Max |
DatasetObjectsLabelingFailed |
在标注作业中未能标记的数据集对象数。要查看标注作业进度,请使用 Max 指标。 单位:无 有效统计数据:Max |
JobsFailed |
单个标注作业失败。要获取失败的标注作业总数,请使用 Sum 统计数据。 单位:无 有效统计数据:Sum、Sample Count |
JobsSucceeded |
单个标注作业成功。要获取成功的标注作业总数,请使用 Sum 统计数据。 单位:无 有效统计数据:Sum、Sample Count |
JobsStopped |
单个标注作业已停止。要获取停止的标注作业总数,请使用 Sum 统计数据。 单位:无 有效统计数据:Sum、Sample Count |
TasksAccepted |
工作人员接受了单个任务。要获取工作人员接受的任务总数,请使用 Sum 统计数据。Ground Truth 会尝试将每个单独的 单位:无 有效统计数据:Sum、Sample Count |
TasksDeclined |
工作人员拒绝了单个任务。要获取工作人员拒绝的任务总数,请使用 Sum 统计数据。Ground Truth 会尝试将每个单独的 单位:无 有效统计数据:Sum、Sample Count |
TasksReturned |
返回了一个任务。要获取返回的任务总数,请使用 Sum 统计信息。Ground Truth 会尝试将每个单独的 单位:无 有效统计数据:Sum、Sample Count |
TasksSubmitted |
一项任务 submitted/completed 是由私人工人完成的。要获取工作人员提交的任务总数,请使用 Sum 统计数据。Ground Truth 会尝试将每个单独的 单位:无 有效统计数据:Sum、Sample Count |
TimeSpent |
专有工作人员完成任务所用的时间。此指标不包括工作人员暂停或休息的时间。Ground Truth 会尝试将每个 单位:秒 有效统计数据:Sum、Sample Count |
TotalDatasetObjectsLabeled |
在标注作业中成功标记的数据集对象数。要查看标注作业进度,请使用 Max 指标。 单位:无 有效统计数据:Max |
| 维度 | 说明 |
|---|---|
LabelingJobName |
筛选标签作业的数据集对象计数指标。 |
Amazon SageMaker 特色商店指标
| 指标 | 说明 |
|---|---|
ConsumedReadRequestsUnits |
在指定时间段内使用的读取单元数。您可以检索特征存放区运行时系统操作及其相应特征组使用的读取单元。 单位:无 有效统计数据:全部 |
ConsumedWriteRequestsUnits |
在指定时间段内使用的写入单元数。您可以检索特征存放区运行时系统操作及其相应特征组使用的写入单元。 单位:无 有效统计数据:全部 |
ConsumedReadCapacityUnits |
指定时间段内使用的预配置读取容量单位数。您可以检索特征存放区运行时系统操作及其相应特征组使用的读取容量单元。 单位:无 有效统计数据:全部 |
ConsumedWriteCapacityUnits |
在指定时间段内使用的预配置写入容量单位数。您可以检索特征存放区运行时系统操作及其相应特征组使用的写入容量单元。 单位:无 有效统计数据:全部 |
| 维度 | 说明 |
|---|---|
FeatureGroupName, OperationName |
筛选特征组和您指定的操作的特征存放区运行时系统使用指标。 |
| 指标 | 说明 |
|---|---|
Invocations |
在指定时间段内对特征存放区运行时系统操作发出的请求数。 单位:无 有效统计数据:Sum |
Operation4XXErrors |
向 Feature Store 运行时系统操作发出的请求数,其中操作返回了 4xx HTTP 响应代码。对于每个 4xx 响应,发送 1;否则,发送 0。 单位:无 有效统计数据:Average、Sum |
Operation5XXErrors |
向特征存放区运行时系统操作发出的请求数,其中操作返回了 5xx HTTP 响应代码。对于每个 5xx 响应,发送 1;否则,发送 0。 单位:无 有效统计数据:Average、Sum |
ThrottledRequests |
向特征存放区运行时系统操作发出的请求数,其中请求被节流。对于每个节流请求,发送 1;否则,发送 0。 单位:无 有效统计数据:Average、Sum |
Latency |
处理向 Feature Store 运行时系统操作提出的请求的时间间隔。此间隔是从 SageMaker AI 收到请求到向客户端返回响应之时测量的。 单位:微秒 有效统计数据:Average、Sum、Min、Max、Sample Count、Percentiles |
| 维度 | 说明 |
|---|---|
|
|
筛选特征组和您指定的操作的特征存放区运行时系统操作指标。您可以将这些维度用于非批量操作 GetRecord,例如 PutRecord、和 DeleteRecord。 |
OperationName |
筛选您指定的操作的特征存放区运行时系统操作指标。您可以将此维度用于批量操作,例如 BatchGetRecord。 |
SageMaker 管道指标
AWS/Sagemaker/ModelBuildingPipeline 命名空间包括管道执行的以下指标。
有两种类型的管道执行指标可用:
-
所有管道的执行指标 - 账户级管道执行指标(用于当前账户中的所有管道)
-
按管道划分的执行指标 - 每个管道的管道执行指标
指标按 1 分钟一次的频率提供。
| 指标 | 说明 |
|---|---|
ExecutionStarted |
启动的管道执行次数。 单位:计数 有效统计数据:Average、Sum |
ExecutionFailed |
失败的管道执行次数。 单位:计数 有效统计数据:Average、Sum |
ExecutionSucceeded |
成功的管道执行次数。 单位:计数 有效统计数据:Average、Sum |
ExecutionStopped |
已停止的管道执行次数。 单位:计数 有效统计数据:Average、Sum |
ExecutionDuration |
管道执行运行的持续时间(以毫秒为单位)。 单位:毫秒 有效统计数据:Average、Sum、Min、Max、Sample Count |
| 维度 | 说明 |
|---|---|
PipelineName |
筛选指定管道的管道执行指标。 |
AWS/Sagemaker/ModelBuildingPipeline 命名空间包括管道步骤的以下指标。
指标按 1 分钟一次的频率提供。
| 指标 | 说明 |
|---|---|
StepStarted |
已启动的步骤数。 单位:计数 有效统计数据:Average、Sum |
StepFailed |
失败的步骤数。 单位:计数 有效统计数据:Average、Sum |
StepSucceeded |
成功的步骤数。 单位:计数 有效统计数据:Average、Sum |
StepStopped |
已停止的步骤数。 单位:计数 有效统计数据:Average、Sum |
StepDuration |
步骤运行的持续时间(以毫秒为单位)。 单位:毫秒 有效统计数据:Average、Sum、Min、Max、Sample Count |
| 维度 | 说明 |
|---|---|
PipelineName, StepName |
筛选指定管道和步骤的步骤指标。 |