什么是 Amazon S3?
Amazon Simple Storage Service(Amazon S3)是一种对象存储服务,提供行业领先的可扩展性、数据可用性、安全性和性能。各种规模和行业的客户都可以使用 Amazon S3 存储和保护任意数量的数据,用于数据湖、网站、移动应用程序、备份和恢复、归档、企业应用程序、IoT 设备和大数据分析。Amazon S3 提供了管理功能,使您可以优化、组织和配置对数据的访问,以满足您的特定业务、组织和合规性要求。
注意
有关将 Amazon S3 Express One Zone 存储类与目录存储桶配合使用的更多信息,请参阅S3 Express One Zone和使用目录存储桶。
Amazon S3 的功能
存储类
Amazon S3 提供一系列适合不同使用案例的存储类。例如,您可以将任务关键型生产数据存储在 S3 Standard 或 S3 Express One Zone 中以便频繁访问,将不经常访问的数据存储在 S3 Standard-IA 或 S3 One Zone-IA 中,并在 S3 Glacier Instant Retrieval、S3 Glacier Flexible Retrieval、和 S3 Glacier Deep Archive 中以极低的成本归档数据。
Amazon S3 Express One Zone 是高性能的单区 Amazon S3 存储类,专门用于为延迟要求极高的应用程序提供稳定的毫秒级数据访问。S3 Express One Zone 是目前具有极低延迟的云对象存储类,相比 S3 Standard,其数据访问速度要快 10 倍,且请求成本低 50%。S3 Express One Zone 是第一种可以在其中选择单个可用区的 S3 存储类,您可以选择将您的对象存储与计算资源联合托管在一个位置,从而提供尽可能高的访问速度。此外,为了进一步提高访问速度并支持每秒数十万个请求,数据存储在新的存储桶类型中:Amazon S3 目录存储桶。有关更多信息,请参阅S3 Express One Zone和使用目录存储桶。
您可以在 S3 Intelligent-Tiering 中存储具有不断变化或未知访问模式的数据,该分层可在访问模式发生变化时自动在四个访问层之间移动数据,从而优化存储成本。这四个访问层包括两个低延迟访问层(针对频繁和不频繁访问进行了优化),以及两个为异步访问很少访问的数据而设计的 opt-in archive 访问层。
有关更多信息,请参阅 了解和管理 Amazon S3 存储类。
存储管理
Amazon S3 具有存储管理功能,您可以使用这些功能来管理成本、满足法规要求、减少延迟并保存数据的多个不同副本以满足合规性要求。
-
S3 生命周期 - 配置生命周期配置以管理您的对象,并在整个生命周期内经济高效地存储这些对象。您可以将对象转换为其他 S3 存储类,也可以使其生命周期结束的对象过期。
-
S3 对象锁定 - 可以在固定的时间段内或无限期地阻止删除或覆盖 Amazon S3 对象。可以使用对象锁定来帮助您满足需要一次写入多次读取 (WORM) 存储的法规要求,或只是添加另一个保护层来防止对象被更改和删除。
-
S3 复制 - 将对象及其各自的元数据和对象标签复制到同一或不同的 Amazon Web Services 区域 目标存储桶中的一个或多个目标存储桶,以减少延迟、合规性、安全性和其他使用案例。
-
S3 批量操作 - 通过单个 S3 API 请求或在 Amazon S3 控制台中单击几次,大规模管理数十亿个对象。您可以使用批量操作来执行诸如复制、调用 Amazon Lambda 函数和还原数百万或数十亿个对象等这样的操作。
访问管理和安全性
Amazon S3 提供了用于审核和管理对存储桶和对象的访问的功能。默认情况下,S3 存储桶和对象都是私有的。您只能访问您创建的 S3 资源。要授予支持您特定使用案例的细粒度资源权限或审核 Amazon S3 资源的权限,您可以使用以下功能。
-
S3 阻止公有访问 - 阻止对 S3 存储桶和对象的公有访问。默认情况下,“屏蔽公共访问权限”设置在存储桶级别处于开启状态。我们建议您将所有“屏蔽公共访问权限”设置保持为启用状态,除非您知道您需要为您的特定使用案例关闭其中一个或多个设置。有关更多信息,请参阅 为 S3 存储桶配置屏蔽公共访问权限设置。
-
Amazon Identity and Access Management(IAM)– IAM 是一种 Web 服务,可帮助您安全地控制对 Amazon 资源(包括 Amazon S3 资源)的访问。借助 IAM,您可以集中管理控制用户可访问哪些 Amazon 资源的权限。可以使用 IAM 来控制谁通过了身份验证(准许登录)并获得授权(具有相应权限)来使用资源。
-
存储桶策略 - 使用基于 IAM 的策略语言为 S3 存储桶及其中的对象配置基于资源的权限。
-
Amazon S3 接入点 – 使用专用访问策略配置命名网络端点,以便大规模管理对 Amazon S3 中共享数据集的访问。
-
访问控制列表(ACL)- 向授权用户授予单个存储桶和对象的读写权限。作为一般规则,我们建议您使用基于 S3 资源的策略(存储桶策略和接入点策略)或 IAM 用户策略进行访问控制,而不是 ACL。策略是一种简化、更灵活的访问控制选项。借助存储桶策略和接入点策略,您可以定义广泛适用于针对 Amazon S3 资源的所有请求的规则。有关何时使用 ACL 而不是基于资源的策略或 IAM 用户策略的特定情况的更多信息,请参阅使用 ACL 管理访问。
-
S3 对象所有权 – 获取存储桶中每个对象的所有权,从而简化对存储在 Amazon S3 中的数据的访问管理。S3 对象所有权是 Amazon S3 存储桶级别的设置,您可以使用该设置来禁用或启用 ACL。默认情况下,ACL 处于禁用状态。禁用 ACL 后,存储桶拥有者拥有存储桶中的所有对象,并使用访问管理策略来专门管理对数据的访问权限。
-
适用于 S3 的 IAM Access Analyzer - 评估和监控您的 S3 存储桶访问策略,确保这些策略仅提供对 S3 资源的预期访问权限。
数据处理
要转换数据并触发工作流以大规模自动执行各种其他处理活动,您可以使用以下功能。
-
S3 Object Lambda - 您可以将自己的代码添加到 S3 GET、HEAD 和 LIST 请求中,以便在数据返回到应用程序时修改和处理数据。筛选行、动态调整图像大小、编辑机密数据等。
-
事件通知 - 当您的 S3 资源发生更改时,触发使用 Amazon Simple Notification Service(Amazon SNS)、Amazon Simple Queue Service(Amazon SQS)和 Amazon Lambda 的工作流程。
存储日志记录和监控
Amazon S3 提供日志记录和监控工具,您可以使用这些工具来监控和控制 Amazon S3 资源的使用情况。更多信息,请参阅监控工具。
自动监控工具
-
Amazon S3 的 Amazon CloudWatch 指标- 跟踪 S3 资源的运行状况,并在估计费用达到用户定义的阈值时配置计费警报。
-
Amazon CloudTrail - 在 Amazon S3 中记录用户采取的行动、角色或 Amazon Web Services 服务。CloudTrail 日志为您提供了 S3 存储桶级别和对象级操作的详细 API 跟踪。
手动监控工具
-
服务器访问日志- 详细地记录对存储桶提出的各种请求。您可以使用服务器访问日志对许多使用案例进行安全和访问审计,了解客户群或了解您的 Amazon S3 账单。
-
Amazon Trusted Advisor - 通过使用 Amazon 最佳实践检查以确定优化 Amazon 基础架构、提高安全性和性能、降低成本以及监控服务配额。然后,您可以按照建议优化服务和资源。
分析和见解
Amazon S3 提供的功能可帮助您了解存储使用情况,从而使您能够更好地了解、分析和大规模优化存储。
-
Amazon S3 Storage Lens - 了解、分析和优化您的存储。S3 Storage Lens 存储统计管理工具提供了超过 60 个使用率和活动指标以及交互式控制面板,用于汇总整个组织、特定客户、Amazon Web Services 区域、存储桶或前缀的数据。
-
存储类分析- 分析存储访问模式,以决定何时需要将数据移动到更经济高效的存储类。
-
带清单报告的 S3 清单- 审核和报告对象及其相应的元数据,并配置其他 Amazon S3 功能,在清单报告中采取措施。例如,您可以报告对象的复制和加密状态。有关清单报告中每个对象可用的所有元数据的列表,请参阅 Amazon S3 清单。
强一致性
Amazon S3 为所有 Amazon Web Services 区域 中的 Amazon S3 存储桶中对象的 PUT 和 DELETE 请求提供了强大的先写后读一致性。这个行为既适用于到新对象的写入,也适用于覆盖现有对象的 PUT 和 DELETE。此外,针对 Amazon S3 Select、Amazon S3 访问控制列表 (ACL)、Amazon S3 对象标签和对象元数据(例如 HEAD 对象)的读取操作具有严格一致性。有关更多信息,请参阅 Amazon S3 数据一致性模型。
Amazon S3 的工作原理
Amazon S3 是一种对象存储服务,可将数据作为对象、层次结构数据或表数据存储在存储桶中。对象指的是一个文件和描述该文件的任何元数据。存储桶是对象的容器。
要将数据存储在 Amazon S3 中,您需要先创建存储桶,然后指定存储桶名称和 Amazon Web Services 区域。然后,您将数据作为 Amazon S3 中的对象上传到该存储桶。每个对象都带有密钥(或键名称),它是存储桶中对象的唯一标识符。
S3 提供了一些功能,您可以配置这些功能以支持您的特定使用案例。例如,您可以使用 S3 版本控制将对象的多个版本保持在同一个存储桶中,这允许您恢复意外删除或覆盖的对象。
存储桶及其中的对象是私有的,只有在您明确授予访问权限时才可以访问。您可以使用存储桶策略、Amazon Identity and Access Management(IAM)策略、访问控制列表(ACL)和 S3 接入点管理访问。
桶
Amazon S3 支持四种类型的存储桶:通用存储桶、目录存储桶、表存储桶和向量存储桶。每种类型的存储桶都为不同的应用场景提供了一组独特的功能。
通用存储桶:建议将通用存储桶用于大多数应用场景和访问模式,它们是最初的 S3 存储桶类型。通用存储桶是存储在 Amazon S3 中的对象的容器,您可以在存储桶中和跨所有存储类(S3 Express One Zone 除外)存储任意数量的对象,因此,您可以跨多个可用区以冗余方式存储对象。有关更多信息,请参阅创建、配置和使用 Amazon S3 通用存储桶。
默认情况下,通用存储桶存在于全局命名空间中,这意味着每个存储桶名称在分区内的所有 Amazon Web Services 区域、所有 Amazon Web Services 账户间都必须是唯一的。分区是区域的分组。Amazon 目前有四个分区:aws(标准区域)、aws-cn(中国区域)、aws-us-gov(Amazon GovCloud (US))以及 aws-eusc(欧洲主权云)。创建通用存储桶时,您可以选择在共享全局命名空间中创建存储桶,也可以选择在您的账户区域命名空间中创建存储桶。您的账户区域命名空间是全局命名空间的细分,只有您的账户才能在其中创建存储桶。在您的账户区域命名空间中创建的新通用存储桶对于您的账户是唯一的,并且始终无法由其它账户重新创建。有关存储桶命名空间的更多信息,请参阅通用存储桶的命名空间。
注意
默认情况下,所有通用存储桶都是私有的。但是,您可以授予对通用存储桶的公共访问权限。您可以在存储桶、前缀(文件夹)或对象标签级别控制对通用存储桶的访问权限。有关更多信息,请参阅 Amazon S3 中的访问控制。
目录存储桶:建议用于低延迟应用场景和数据驻留应用场景。默认情况下,在 Amazon Web Services 账户中最多可以创建 100 个目录存储桶,并且对目录存储桶中可以存储的对象数量没有限制。目录存储桶将对象组织到层次结构目录(前缀)中,而不是通用存储桶的扁平存储结构。此存储桶类型没有前缀限制,单个目录可以水平扩展。有关更多信息,请参阅使用目录存储桶。
-
对于低延迟应用场景,您可以在单个 Amazon 可用区中创建目录存储桶来存储数据。可用区中的目录存储桶支持 S3 Express One Zone 存储类。使用 S3 Express One Zone,您的数据将冗余地存储在单个可用区中的多个设备上。如果您的应用程序注重性能,并且受益于个位数毫秒的
PUT和GET延迟,则建议使用 S3 Express One Zone 存储类。要了解有关在可用区中创建目录存储桶的更多信息,请参阅高性能工作负载。 -
对于数据驻留应用场景,您可以在单个 Amazon 专用本地区域(DLZ)中创建目录存储桶来存储数据。在专用本地区域中,您可以创建 S3 目录存储桶来将数据存储在特定的数据边界中,这有助于支持您的数据驻留和隔离应用场景。Local Zones 中的目录存储桶支持 S3 One Zone-Infrequent Access(S3 One Zone-IA;Z-IA)存储类。要了解有关在本地区域中创建目录存储桶的更多信息,请参阅数据驻留工作负载。
注意
默认情况下,目录存储桶会禁用所有公共访问权限。此行为不可更改。您无法授予对存储在目录存储桶中的对象的访问权限。您只能授予对目录存储桶的访问权限。有关更多信息,请参阅对请求进行身份验证和授权。
表存储桶:建议用于存储表数据,例如每日购买交易、流传感器数据或广告展示次数。表数据以列和行表示数据,就像在数据库表中一样。表存储桶提供针对分析和机器学习工作负载进行优化的 S3 存储,其功能旨在持续提高查询性能并降低表的存储成本。S3 表类数据存储服务专为以 Apache Iceberg 格式存储表数据而构建。您可以使用常用的查询引擎(包括 Amazon Athena、Amazon Redshift 和 Apache Spark)在 S3 表类数据存储服务中查询表数据。默认情况下,每个 Amazon Web Services 区域、每个 Amazon Web Services 账户最多可以创建 10 个表存储桶,每个表存储桶最多可以创建 10000 个表。有关更多信息,请参阅使用 S3 表类数据存储服务和表存储桶。
注意
所有表存储桶和表都是私有的,不能使之成为公有的。只有被明确授予访问权限的用户才可以访问这些资源。要授予访问权限,您可以对表存储桶和表使用基于 IAM 资源的策略,并对用户和角色使用基于 IAM 身份的策略。有关更多信息,请参阅 S3 表类数据存储服务的安全性。
向量存储桶:S3 向量存储桶是一种专为存储和查询向量而构建的 Amazon S3 存储桶。向量存储桶使用专用 API 操作来高效地写入和查询向量数据。使用 S3 向量存储桶,可以存储机器学习模型的向量嵌入、执行相似性搜索以及与 Amazon Bedrock 和 Amazon OpenSearch 等服务集成。
S3 向量存储桶使用向量索引来组织数据,向量索引是存储桶中的资源,用于存储和组织向量数据,以实现高效的相似性搜索。可以为每个向量索引配置特定的维度、距离指标(如余弦相似性)和元数据配置,以针对特定的使用案例进行优化。有关更多信息,请参阅 使用 S3 Vectors 和向量存储桶。
关于所有存储桶类型的附加信息
创建存储桶时,您可以输入存储桶名称,然后选择Amazon Web Services 区域存储桶将驻留的位置。创建存储桶后,无法更改存储桶或区域的名称。存储桶名称必须遵循以下存储桶命名规则:
存储桶还:
-
在最高级别组织 Amazon S3 命名空间。对于通用存储桶,此命名空间为
S3。对于目录存储桶,此命名空间为s3express。对于表存储桶,此命名空间为s3tables。 -
标识负责存储和数据传输费用的账户。
-
用作使用情况报告的聚合单元。
对象
对象是 Amazon S3 中存储的基础实体。对象由对象数据和元数据组成。元数据是一组描述对象的名称-值对。这些对值包括一些默认元数据(如上次修改日期)和标准 HTTP 元数据(如 Content-Type)。您还可以在存储对象时指定自定义元数据。
每个对象都储存在一个存储桶中。例如,如果名为 photos/puppy.jpg 的对象存储在美国西部(俄勒冈州)区域的 amzn-s3-demo-bucket 通用存储桶中,则可使用 URL https://amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpg 对该对象进行寻址。有关更多信息,请参阅访问存储桶。
存储桶中的对象由密钥(名称) 和版本 ID唯一标识(如果在存储桶上启用了 S3 版本控制)。有关对象的更多信息,请参阅 Amazon S3 对象概述。
密钥
对象密钥(或密钥名称)是指存储桶中对象的唯一标识符。存储桶内的每个对象都只能有一个键。存储桶、对象密钥和可选版本 ID 的组合(如果为存储桶启用了 S3 版本控制)唯一标识每个对象。因此,您可以将 Amazon S3 看作“存储桶 + 键 + 版本”与对象本身之间的基本数据映射。
将 Web 服务端点、存储桶名称、密钥和版本(可选)组合在一起,可唯一地寻址 Amazon S3 中的每个对象。例如,在 URL https:// 中,amzn-s3-demo-bucket.s3.us-west-2.amazonaws.com/photos/puppy.jpgamzn-s3-demo-bucketphotos/puppy.jpg 是密钥。
有关对象键的更多信息,请参阅 为 Amazon S3 对象命名。
S3 版本控制
您可以使用 S3 版本控制功能将对象的多个变量保留在同一存储桶中。使用 S3 版本控制功能,您可以保留、检索和恢复存储桶中的各个版本。您能够轻松从用户意外操作和应用程序故障中恢复数据。
有关更多信息,请参阅 使用 S3 版本控制保留对象的多个版本。
版本 ID
在存储桶中启用 S3 版本控制时,Amazon S3 会为添加到存储桶中的每个对象生成唯一的版本ID。启用版本控制时存在于存储桶中的对象的版本 ID 为null。如果使用其他操作修改这些(或任何其他)对象,例如 CopyObject 和 PutObject 时,新对象将获得唯一的版本 ID。
有关更多信息,请参阅 使用 S3 版本控制保留对象的多个版本。
存储桶策略
存储桶策略是基于资源的 Amazon Identity and Access Management (IAM) 策略,您可以使用该策略向存储桶及其中对象授予访问权限。只有存储桶拥有者才能将策略与存储桶关联。附加到存储桶的权限适用于存储桶拥有者拥有的存储桶中所有对象。存储桶策略的大小限制为 20 KB。
存储桶策略使用基于 JSON 的访问策略语言,该语言是跨平台的标准语言 Amazon。您可以使用存储桶策略添加或拒绝存储桶中对象的权限。存储桶策略根据策略中的元素允许或拒绝请求,包括请求者、S3 操作、资源以及请求的方面或条件(例如,用于发出请求的 IP 地址)。例如,您可以创建一个存储桶策略,该策略授予跨账户将对象上传到 S3 存储桶的权限,同时确保存储桶拥有者对上传的对象拥有完全控制权。有关更多信息,请参阅 Amazon S3 存储桶策略的示例。
在存储桶策略中,您可以在 Amazon 资源名称(ARN)和其他值上使用通配符来授予对对象子集的权限。例如,您可以控制对以通用前缀或以给定扩展名结尾的对象组的访问,例如 .html。
S3 接入点
Amazon S3 接入点为命名的网络端点,其专用访问策略描述了如何使用该端点访问数据。接入点附加到底层数据来源,如通用存储桶、目录存储桶或适用于 OpenZFS 的 FSx 卷,您可以使用这些数据来源来执行 S3 对象操作,如 GetObject 和 PutObject。访问点可简化对 Amazon S3 中的共享数据集的大规模数据访问管理。
每个接入点都有自己的接入点策略。还可以为每个附加到存储桶的接入点配置屏蔽公共访问权限设置。为了限制 Amazon S3 数据访问提供网络,您可以将任何接入点配置为仅接受来自私有云(VPC)的请求。
有关通用存储桶的接入点的更多信息,请参阅通过接入点管理对共享数据集的访问。有关目录存储桶的接入点的更多信息,请参阅通过接入点管理对目录存储桶中共享数据集的访问权限。
访问控制列表(ACL)
您可以使用 ACL 向已授权的用户授予对单个通用存储桶和对象的读写权限。每个通用存储桶和对象都有一个作为子资源附加到它的 ACL。ACL 定义了哪些 Amazon Web Services 账户 或组将被授予访问权限以及访问的类型。ACL 是一种访问控制机制,其早于 IAM。有关 ACL 的更多信息,请参阅 访问控制列表 (ACL) 概述。
S3 对象所有权是 Amazon S3 存储桶级别的设置,您可以使用该设置来控制上传到存储桶的对象的所有权和禁用或启用 ACL。默认情况下,对象所有权设为强制存储桶拥有者设置,并且所有 ACL 均处于禁用状态。禁用 ACL 后,存储桶拥有者拥有存储桶中的所有对象,并使用访问管理策略来专门管理对这些对象的访问权限。
Amazon S3 中的大多数现代使用案例不再需要使用 ACL。我们建议您将 ACL 保持为禁用状态,除非有需要单独控制每个对象的访问权限的情况。禁用 ACL 后,您可以使用策略来控制对存储桶中所有对象的访问权限,无论是谁将对象上传到您的存储桶。有关更多信息,请参阅 为您的存储桶控制对象所有权和禁用 ACL。。
Regions
您可以选择一个 Amazon Web Services 区域 供 Amazon S3 存储您创建的存储桶。您可以选择一个区域,以便优化延迟、尽可能降低成本或满足法规要求。存储在 Amazon Web Services 区域 中的对象永远不会离开该区域,除非显式地将它们传输或复制到另一个区域。例如,在欧洲(爱尔兰)区域存储的对象将一直留在欧洲。
注意
您只能在已为账户启用的 Amazon Web Services 区域 中访问 Amazon S3 及其功能。有关启用区域以创建和管理 Amazon 资源的更多信息,请参阅《Amazon Web Services 一般参考》中的管理 Amazon Web Services 区域。
有关 Amazon S3 区域和端点的列表,请参阅《Amazon Web Services 一般参考》中的区域和端点。
Amazon S3 数据一致性模型
Amazon S3 为所有 Amazon Web Services 区域 中的 Amazon S3 存储桶中对象的 PUT 和 DELETE 请求提供了强大的先写后读一致性。此行为既适用于对新对象的写入,也适用于覆盖现有对象的 PUT 请求和 DELETE 请求。此外,Amazon S3 Select、Amazon S3访问控制列表 (ACL)、Amazon S3对象标记和对象元数据(例如,HEAD对象)上的读取操作非常一致。
单个键的更新是原子更新。例如,如果您从一个线程对现有密钥执行 PUT 请求,并同时从另一个线程对同一密钥执行 GET 请求,则您将获得旧数据或新数据,但绝不会获得部分或损坏的数据。
Amazon S3 通过在 Amazon 数据中心内的多个服务器之间复制数据,从而实现高可用性。如果 PUT 请求成功,则数据已安全存储。在收到成功的 PUT 响应后启动的任何读取(GET 或 LIST 请求)都将返回 PUT 请求写入的数据。以下是此行为的示例:
-
这是一个过程,它将一个新对象写入 Amazon S3,并立即列出其存储桶内的密钥。新对象显示在列表中。
-
这是一个过程,会替换一个现有的对象,并立即尝试读取此对象。Amazon S3 返回新数据。
-
这是一个过程,会删除一个现有的对象,并立即尝试读取此对象。Amazon S3 不会返回任何数据,因为对象已被删除。
-
这是一个过程,会删除一个现有的对象,并立即列出其存储桶内的键。该对象不会显示在列表中。
注意
-
Amazon S3 不支持对并发写入器进行对象锁定。如果同时对同一键发出两个 PUT 请求,则以带有最新时间戳的请求为准。如果这会导致问题,您需要在应用程序中创建对象锁定机制。
-
更新是基于键的。无法跨键值实现原子更新。例如,无法根据一个键值的更新对另一个键值进行更新,除非将此功能设计到应用程序中。
存储桶配置具有最终一致性模型。具体而言,这意味着:
-
如果您删除存储桶,然后立即列出所有存储桶,则所删除的存储桶可能仍会显示在列表中。
-
如果您首次对存储桶启用版本控制,则可能需要很短的时间即可完全传播更改。我们建议您在启用版本控制后等待 15 分钟,然后再对存储桶中的对象发出写入操作(PUT 或 DELETE 请求)。
并发应用程序
本部分提供了当多个客户端向同一项目写入时,Amazon S3 应采取的行为示例。
在本示例中,W1 (写入 1) 和 W2 (写入 2) 会在 R1 (读取 1) 和 R2 (读取 2) 启动之前完成。由于 S3 具有严格一致性,因此 R1 和 R2 都会返回 color = ruby。
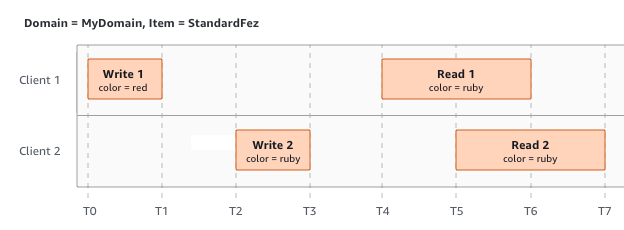
在下一个示例中,W2 不会在 R1 启动之前完成。因此,R1 可能会返回 color = ruby 或 color = garnet。但是,由于 W1 和 W2 在 R2 开始之前完成,因此 R2 会返回 color =
garnet。
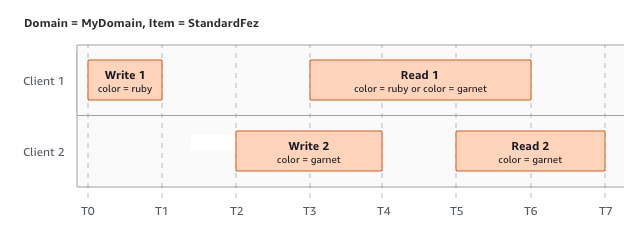
在上一个示例中,W2 在 W1 收到确认之前开始。因此,这些写入被视为并发写入。Amazon S3 在内部使用 last-writer-wins 语义来确定哪个写入优先。但是,由于网络延迟等各种因素,无法预测 Amazon S3 接收请求的顺序和应用程序接收确认的顺序。例如,W2 可能由同一区域中的 Amazon EC2 实例启动,而 W1 可能由距离更远的主机启动。确定最终值的最佳方法是在确认两次写入操作后执行读取。

相关服务
将数据加载到 Amazon S3 中之后,您可以将数据用于其他 Amazon 服务。以下是您可能最常用使用的服务:
-
Amazon Elastic Compute Cloud (Amazon EC2)
- Amazon Web Services 云 中提供安全可扩展的计算容量。使用 Amazon EC2 可避免前期的硬件投入,因此您能够更快地开发和部署应用程序。您可以使用 Amazon EC2 启动所需数量的虚拟服务器,配置安全性和联网以及管理存储。 -
Amazon EMR
– 帮助企业、研究人员、数据分析师和开发人员轻松、经济实惠地处理海量数据。Amazon EMR 使用 Amazon EC2 和 Amazon S3 的 Web 规模基础设施上运行的托管 Hadoop 框架。 -
Amazon Transfer Family
- 为使用安全外壳 (SSH) 文件传输协议 (SFTP)、通过 SSL (FTPS) 的文件传输协议 (FTPS) 和文件传输协议 (FTP) 直接进出 Amazon S3 或 Amazon Elastic File System (Amazon EFS) 的文件传输提供完全托管支持。
访问 Amazon S3
您可以通过以下任何方式使用 Amazon S3:
Amazon Web Services 管理控制台
控制台是基于 Web 的用户界面,用于管理 Amazon S3 和 Amazon 资源。如果您已注册 Amazon Web Services 账户 账户,您可以通过登录 Amazon Web Services 管理控制台 并从 Amazon Web Services 管理控制台 主页中选择 S3 来访问 Amazon S3 控制台。
Amazon Command Line Interface
可以使用 Amazon 命令行工具,在系统的命令行中发出命令来执行 Amazon (包括 S3)任务。
Amazon Command Line Interface (Amazon CLI)
Amazon SDK
Amazon 提供的 SDK(软件开发工具包)包含各种编程语言和平台(Java、Python、Ruby、.NET、iOS、Android 等)的库和示例代码。Amazon SDK 提供便捷的方式来创建对 S3 和 Amazon 的编程访问。Amazon S3 是一项 REST 服务。您可以使用 Amazon SDK 库向 Amazon S3 发送请求,该库包装了底层 Amazon S3 REST API 并简化了编程任务。例如,SDK 负责计算签名、加密签名请求、管理错误和自动重试请求等任务。有关 Amazon SDK 的信息(包括如何下载及安装),请参阅 适用于 Amazon 的工具
与 Amazon S3 的每一次交互都是经身份验证的或匿名的。如果您使用 Amazon SDK,库根据您提供的密钥计算用于身份验证的签名。有关如何向 Amazon S3 发出请求的更多信息,请参阅 Making requests。
Amazon S3 REST API
Amazon S3 架构的设计与编程语言无关,使用 Amazon 支持的接口来存储和检索对象。您可以访问 S3 和 Amazon 以编程方式使用 Amazon S3 REST API。REST API 是面向 Amazon S3 的 HTTP 接口。借助 REST API,您可以使用标准的 HTTP 请求创建、提取和删除存储桶和对象。
要使用 REST API,您可以借助任何支持 HTTP 的工具包。只要对象是匿名可读的,您甚至可以使用浏览器来提取它们。
REST API 使用标准的 HTTP 标头和状态代码,以使标准的浏览器和工具包按预期工作。在某些区域中,我们向 HTTP 添加了功能 (例如,我们添加了标头来支持访问控制)。在这些情况下,我们已尽最大努力使添加的新功能与标准的 HTTP 使用样式相匹配。
如果您在应用程序中直接调用 REST API,您必须编写代码来计算签名并将它添加到请求中。有关如何向 Amazon S3 发出请求的更多信息,请参阅《Amazon S3 API 参考》中的 Making requests。
注意
HTTP 上的 SOAP API 支持已弃用,但是仍可在 HTTPS 上使用。SOAP 不支持较新的 Amazon S3 特征。我们建议您使用 REST API 或 Amazon SDK。
为 Amazon S3 支付费用
Amazon S3 定价的设计可让您不必为应用程序的存储需求制定计划。大多数存储提供商都要求您购买预定量的存储和网络传输容量。在这种情况下,如果超过此容量,就会关闭您的服务或对您收取高额的超容量费用。如果没有超过此容量,又要按全部容量支付使用费用。
Amazon S3 仅按照您的实际使用容量收费,没有任何隐性收费和超容量收费。此模型为您提供了一种可变成本服务,它可以随着您的业务增长而增长,同时为您提供 Amazon 基础架构的成本优势。有关更多信息,请参阅 Amazon S3 定价
在注册 Amazon 时,将在 Amazon 中为您的 Amazon Web Services 账户 自动注册所有服务,包括 Amazon S3。不过,您只需为使用的服务付费。如果您是 Amazon S3 的新客户,则可以免费开始使用 Amazon S3。有关更多信息,请参阅 Amazon免费套餐
若要查看您的账单,请转到 Amazon 账单与成本管理 控制台
PCI DSS 合规性
Amazon S3 支持由商家或服务提供商处理、存储和传输信用卡数据,而且已经验证符合支付卡行业 (PCI) 数据安全标准 (DSS)。有关 PCI DSS 的更多信息,包括如何请求 Amazon PCI Compliance Package 的副本,请参阅 PCI DSS 第 1 级