Aurora Serverless v1 的工作原理
重要
Amazon 已宣布 Aurora Serverless v1 的生命周期终止日期为:2025 年 3 月 31 日
接下来,您可以了解 Aurora Serverless v1 的工作原理。
主题
Aurora Serverless v1 架构
下图显示了 Aurora Serverless v1 架构的概览。
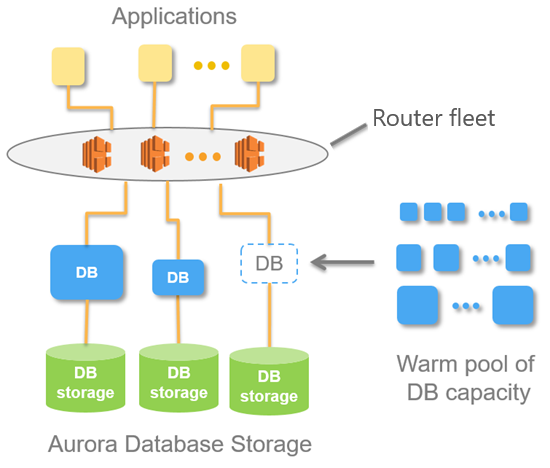
您可指定 Aurora 容量单元 (ACU),而不是配置和管理数据库服务器。每个 ACU 是约 2 GB 的内存、相应的 CPU 和网络的组合。数据库存储从 10 GiB 自动扩展到 128 tebibytes (TiB),与标准 Aurora 数据库集群中的存储相同。
可以指定最小和最大 ACU。最小 Aurora 容量单元 是数据库集群可缩减到的最低 ACU。最大 Aurora 容量单元 是数据库集群可扩展到的最高 ACU。根据您的设置,Aurora Serverless v1 自动创建 CPU 使用率、连接和可用内存阈值的扩展规则。
Aurora Serverless v1 管理 Amazon Web Services 区域中的热资源池以最大程度地减少扩展时间。在 Aurora Serverless v1 将新资源添加到 Aurora 数据库集群时,它使用路由器机群将活动客户端连接切换到新资源。在任何给定时间,您都只需为您的 Aurora 数据库集群中正在主动使用的 ACU 付费。
Aurora Serverless v1 的自动扩展
分配给 Aurora Serverless v1 数据库集群的容量可根据客户端应用程序生成的负载无缝向上和向下扩展。在这里,负载是 CPU 利用率和连接数。当容量受这两个因素之一的限制时,Aurora Serverless v1 可以向上扩展。当它检测到性能问题时,Aurora Serverless v1 也可以向上扩展以解决这些问题。
您可以查看 Aurora Serverless v1 中 Amazon Web Services 管理控制台 集群的扩展事件。在自动扩展期间,Aurora Serverless v1 会重置 EngineUptime 指标。重置指标值的值并不意味着无缝扩展存在问题,也不意味着 Aurora Serverless v1 连接中断。这只是新容量下正常运行时间的起点。了解有关指标的更多信息,请参阅 监控 Amazon Aurora 集群中的指标。
当您的 Aurora Serverless v1 数据库集群没有活动连接时,它可以缩减到零容量(0 ACU)。要了解更多信息,请参阅“暂停和恢复 Aurora Serverless v1”。
当它确实需要执行扩展操作时,Aurora Serverless v1 首先尝试识别扩展点,此时没有处理任何查询。Aurora Serverless v1 可能会由于以下原因而无法找到扩展点:
-
长时间运行的查询
-
进行中的交易
-
临时表或表锁定
在查找扩展点时,为了提高 Aurora Serverless v1 数据库集群的成功率,建议您避免长时间运行的查询和长时间运行的事务。要了解有关阻止扩展的操作以及如何避免这些操作的更多信息,请参阅使用 Aurora Serverless v1 的最佳实践
预设情况下,Aurora Serverless v1 尝试在 5 分钟(300 秒)内找到扩展点。您可以在创建或修改集群时指定不同的超时期限。超时期限可以介于 60 秒至 10 分钟 (600 秒) 之间。如果 Aurora Serverless v1 在指定期限内找不到扩展点,自动扩展操作将超时。
默认情况下,如果自动扩展在超时之前找不到扩展点,那么 Aurora Serverless v1 会将集群保持为当前容量。当您通过选择强制执行容量更改选项创建或修改 Aurora Serverless v1 数据库集群时,可以更改此默认行为。有关更多信息,请参阅 容量更改超时操作。
容量更改超时操作
如果自动扩展在没有找到扩展点的情况下超时,预设情况下 Aurora 将保持当前容量。您可以通过启用 Force the capacity change(强制执行容量更改)选项来选择让 Aurora 强制执行更改。创建集群时,此选项在 Create database(创建数据库)页面的 Autoscaling timeout and action(自动扩展超时和操作)部分中可供选择。
默认情况下,Force the capacity change(强制执行容量更改)选项处于取消选中状态。如果扩展操作已超时而未找到扩展点,则不要选中此选项以使 Aurora Serverless v1 数据库集群的容量保持不变。
选择此选项会导致 Aurora Serverless v1 数据库集群强制执行容量更改,即使没有扩展点也是如此。在选择此选项之前,请注意此选择带来的后果:
-
所有进行中的事务都会中断,并显示以下错误消息。
Aurora MySQL 版本 2 –
错误 1105(HY000):由于无缝扩缩,最后一个事务已中止。请重试。您可以在 Aurora Serverless v1 数据库集群可用后立即重新提交事务。
-
与临时表和表锁定的连接会中断。
建议您仅在应用程序可以从中断的连接或未完成的事务中恢复时,才选择 Force the capacity change(强制容量更改)选项。
创建 Aurora Serverless v1 数据库集群时在 Amazon Web Services 管理控制台 中所做的选择存储在 ScalingConfigurationInfo 对象的 SecondsBeforeTimeout 和 TimeoutAction 属性中。创建集群时,TimeoutAction 属性的值设置为以下值之一:
-
RollbackCapacityChange- 当您选择 Roll back the capacity change(回滚容量更改)选项时设置此值。这是默认行为。 -
ForceApplyCapacityChange– 当您选择 Force the capacity change(强制容量更改)选项时设置此值。
您可以通过使用 describe-db-clusters Amazon CLI 命令在现有 Aurora Serverless v1 数据库集群上获取此属性的值,如下所示。
对于 Linux、macOS 或 Unix:
aws rds describe-db-clusters --regionregion\ --db-cluster-identifieryour-cluster-name\ --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}'
对于:Windows
aws rds describe-db-clusters --regionregion^ --db-cluster-identifieryour-cluster-name^ --query "*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}"
例如,下面显示了美国西部(加利福尼亚北部)区域中名为 west-coast-sles 的 Aurora Serverless v1 数据库集群的查询和响应。
$aws rds describe-db-clusters --region us-west-1 --db-cluster-identifier west-coast-sles --query '*[].{ScalingConfigurationInfo:ScalingConfigurationInfo}' [ { "ScalingConfigurationInfo": { "MinCapacity": 1, "MaxCapacity": 64, "AutoPause": false, "SecondsBeforeTimeout": 300, "SecondsUntilAutoPause": 300, "TimeoutAction": "RollbackCapacityChange" } } ]
如响应所示,此 Aurora Serverless v1 数据库集群使用默认设置。
有关更多信息,请参阅“创建 Aurora Serverless v1 数据库集群”。在创建您的 Aurora Serverless v1 之后,您还可以随时修改超时操作和其他容量设置。要了解如何操作,请参阅修改 Aurora Serverless v1 数据库集群。
暂停和恢复 Aurora Serverless v1
您可以选择在无任何活动的指定时间段内暂停 Aurora Serverless v1 数据库集群。在暂停数据库集群之前指定无任何活动的时间长度。选择此选项后,默认的非活动时间为 5 分钟,但您可以更改此值。此选项为可选设置。
暂停数据库集群后,不会发生任何计算或内存活动,而且您只需支付存储费用。如果暂停 Aurora Serverless v1 数据库集群时请求数据库连接,数据库集群将自动恢复并处理连接请求。
当数据库集群恢复活动时,它的容量与 Aurora 暂停集群时的容量相同。ACU 的数量取决于在暂停集群之前 Aurora 扩展或缩减的程度。
注意
如果暂停数据库集群超过 7 天,则可能会使用快照对数据库集群进行备份。在这种情况下,当有连接到快照的请求时,Aurora 将从快照还原数据库集群。
确定 Aurora Serverless v1 的最大数据库连接数
以下示例用于与 MySQL 5.7 兼容的 Aurora Serverless v1 数据库集群。如果已配置对 MySQL 客户端或查询编辑器的访问权限,则可以使用它们。有关更多信息,请参阅 在查询编辑器中运行查询。
查找最大数据库连接数
-
使用 Amazon CLI 查找 Aurora Serverless v1 数据库集群的容量范围。
aws rds describe-db-clusters \ --db-cluster-identifier my-serverless-57-cluster \ --query 'DBClusters[*].ScalingConfigurationInfo|[0]'结果显示,其容量范围为 1-4 ACU。
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
运行以下 SQL 查询以查找最大连接数。
select @@max_connections;显示的结果适用于集群的最小容量 1 ACU。
@@max_connections 90 -
将集群扩展到 8–32 ACU。
有关扩展的更多信息,请参阅修改 Aurora Serverless v1 数据库集群。
-
确认容量范围。
{ "MinCapacity": 8, "AutoPause": true, "MaxCapacity": 32, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
查找最大连接数。
select @@max_connections;显示的结果适用于集群的最小容量 8 ACU。
@@max_connections 1000 -
将集群扩展到最大可能的 256–256 ACU。
-
确认容量范围。
{ "MinCapacity": 256, "AutoPause": true, "MaxCapacity": 256, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 } -
查找最大连接数。
select @@max_connections;显示的结果适用于 256 ACU。
@@max_connections 6000注意
max_connections值不会随 ACU 的数量线性扩展。 -
将集群向下缩减至 1-4 ACU。
{ "MinCapacity": 1, "AutoPause": true, "MaxCapacity": 4, "TimeoutAction": "RollbackCapacityChange", "SecondsUntilAutoPause": 3600 }这次,
max_connections值适用于 4 ACU。@@max_connections 270 -
让集群缩减至 2 ACU。
@@max_connections 180如果您已将集群配置为在空闲一定时间后暂停,则它将缩小到 0 ACU。但是,
max_connections不会降至低于 1 ACU 的值。@@max_connections 90
Aurora Serverless v1 的参数组
当您创建您的 Aurora Serverless v1 数据库集群时,您可以选择特定 Aurora 数据库引擎和关联的数据库集群参数组。与预置的 Aurora 数据库集群不同,Aurora Serverless v1 数据库集群有一个只配置了数据库集群参数组的读/写数据库实例—它没有单独的数据库参数组。在自动扩展期间,Aurora Serverless v1 需要能够更改集群的参数,以便在容量增加或减少时发挥最佳作用。因此,对于 Aurora Serverless v1 数据库集群,您对特定数据库引擎类型的参数所做的一些更改可能不适用。
例如,Aurora PostgreSQL–基于 Aurora Serverless v1 的数据库集群不能使用 apg_plan_mgmt.capture_plan_baselines 和其他参数,这些参数可能会用于预置的 Aurora PostgreSQL 数据库集群以进行查询计划管理。
通过使用 describe-engine-default-cluster-parameters CLI 命令并查询 Amazon Web Services 区域,您可以获得各种 Aurora 数据库引擎的默认参数组的默认值列表。以下是可用于 --db-parameter-group-family 选项的值。
|
Aurora MySQL 版本 2 |
|
|
Aurora PostgreSQL 版本 11 |
|
|
Aurora PostgreSQL 版本 13 |
|
建议您使用 Amazon 访问密钥 ID 和 Amazon 秘密访问密钥配置 Amazon CLI,并在使用 Amazon CLI 命令之前设置您的 Amazon Web Services 区域。为 CLI 配置提供区域,于是您无需在运行命令时输入 --region 参数。要了解有关配置 Amazon CLI 的更多信息,请参阅《Amazon Command Line Interface 用户指南》中的配置基础知识。
以下示例从 Aurora MySQL 版本 2 的默认数据库集群组中获取参数列表。
对于 Linux、macOS 或 Unix:
aws rds describe-engine-default-cluster-parameters \ --db-parameter-group-family aurora-mysql5.7 --query \ 'EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, `serverless`) == `true`] | [*].{param:ParameterName}' \ --output text
对于:Windows
aws rds describe-engine-default-cluster-parameters ^ --db-parameter-group-family aurora-mysql5.7 --query ^ "EngineDefaults.Parameters[*].{ParameterName:ParameterName,SupportedEngineModes:SupportedEngineModes} | [?contains(SupportedEngineModes, 'serverless') == `true`] | [*].{param:ParameterName}" ^ --output text
为 Aurora Serverless v1 修改参数值
如 Amazon Aurora 的参数组 中所述,无论默认参数组的类型如何(数据库集群参数组、数据库参数组),都不能直接更改其值。相反,您可以根据 Aurora 数据库引擎的默认数据库集群参数组创建自定义参数组,并根据需要更改该参数组的设置。例如,您可能希望更改 Aurora Serverless v1 数据库集群的某些设置以记录查询或将数据库引擎特定日志上传到 Amazon CloudWatch。
创建自定义数据库集群参数组
-
登录Amazon Web Services 管理控制台并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
选择参数组。
-
选择创建参数组,打开参数组详细信息窗格。
-
为要用于 Aurora Serverless v1 数据库集群的数据库引擎选择适当的默认数据库集群组。请务必选择以下选项:
-
对于 Parameter group family(参数组系列),请为所选的数据库引擎选择合适的系列。请确保您的选择名称中有
aurora-前缀。 -
对于 Type(类型),请选择 DB Cluster Parameter Group(数据库集群参数组)。
-
在组名称和描述中,为您或可能需要使用 Aurora Serverless v1 数据库集群及其参数的其他人输入有意义的名称。
-
选择 Create(创建)。
-
您的自定义数据库集群参数组将添加到您的 Amazon Web Services 区域中提供的参数组列表中。现在,当您创建新的 Aurora Serverless v1 数据库集群时,您可以使用自定义数据库集群参数组。您还可以修改现有 Aurora Serverless v1 数据库集群,以使用自定义数据库集群参数组。使用自定义数据库集群参数组启动 Aurora Serverless v1 数据库集群后,您可以使用 Amazon Web Services 管理控制台 或 Amazon CLI 更改动态参数的值。
您还可以使用控制台查看自定义数据库集群参数组中的值与默认数据库集群参数组的值并排比较,如以下屏幕截图所示。
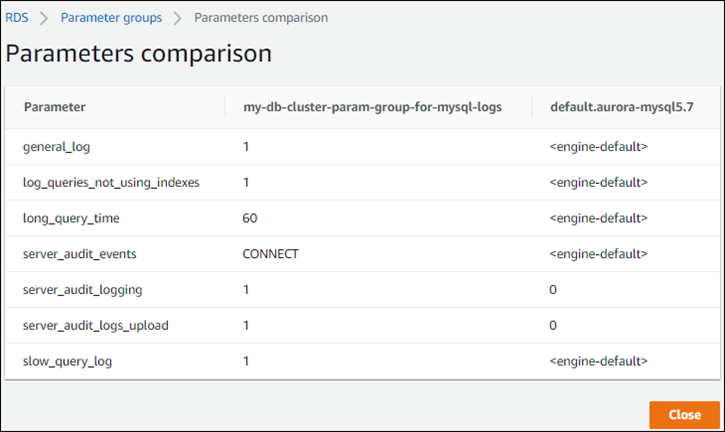
当您更改活动数据库集群上的参数值时,Aurora Serverless v1 将启动无缝扩展以应用参数更改。如果您的 Aurora Serverless v1 数据库集群处于已暂停状态,它会恢复并开始扩展,以便进行更改。参数组更改的扩展操作始终为 forces a capacity change(强制容量更改),因此请注意,如果在扩展期间找不到扩展点,修改参数可能会导致连接中断。
Aurora Serverless v1 的日志记录
默认情况下,Aurora Serverless v1 的错误日志已启用并自动上传到 Amazon CloudWatch。您也可以让 Aurora Serverless v1 数据库集群将 Aurora 数据库引擎特定的日志上传到 CloudWatch。为此,请在自定义数据库集群参数组中启用配置参数。然后,您的 Aurora Serverless v1 数据库集群会将所有可用日志上传到 Amazon CloudWatch。此时,您可以使用 CloudWatch 来分析日志数据、创建警报和查看指标。
对于 Aurora MySQL,下表显示了您可以启用的日志。启用后,它们自动从 Aurora Serverless v1 数据库集群上传到 Amazon CloudWatch。
| Aurora MySQL 日志 | 说明 |
|---|---|
|
|
创建常规日志。设置为 1 以开启。默认为关闭 (0)。 |
|
|
将任何查询记录到不使用索引的慢速查询日志中。默认为关闭 (0)。设置为 1 以开启此日志。 |
|
|
防止快速运行的查询记录在慢速查询日志中。可以设置为 0 到 3,1536,000 之间的浮动值。默认值为 0(不活动)。 |
|
|
要在日志中捕获的事件列表。支持的值有 |
|
|
设置为 1 以打开服务器审核日志记录。如果启用此选项,则可以通过在 |
|
|
创建慢速查询日志。设置为 1 以打开慢速查询日志。默认为关闭 (0)。 |
有关更多信息,请参阅 在 Amazon Aurora MySQL 数据库集群中使用高级审计。
对于 Aurora PostgreSQL,下表显示了您可以启用的日志。启用后,它们自动从 Aurora Serverless v1 数据库集群上传到 Amazon CloudWatch,并附带常规的错误日志。
| Aurora PostgreSQL 日志 | 说明 |
|---|---|
|
|
默认情况下为已启用,无法更改。它会记录所有新客户端连接的详细信息。 |
|
|
默认情况下为已启用,无法更改。记录所有客户端断开连接。 |
|
|
默认情况下处于关闭状态,无法更改。不记录主机名。 |
|
|
默认值为 0(关闭)。设置为 1 以记录锁定等待。 |
|
|
语句在记录前运行的最短持续时间(以毫秒为单位)。 |
|
|
设置记录的消息级别。支持的值为 将性能数据记录到 |
|
|
记录指定千字节 (kB) 以上的临时文件的使用情况。 |
|
|
控制被记录的特定 SQL 语句。支持的值有 |
为 Aurora Serverless v1 数据库集群的 Aurora MySQL 或 Aurora PostgreSQL 启用日志后,可以在 CloudWatch 中查看日志。
通过 Amazon CloudWatch 查看 Aurora Serverless v1 日志
Aurora Serverless v1 自动上传(“发布”)至自定义数据库集群参数组中启用的 Amazon CloudWatch 所有日志。您无需选择或指定日志类型。启用日志配置参数后,将立即开始上传日志。如果您以后禁用日志参数,则将停止进一步上传。但是,所有已发布到 CloudWatch 的日志都将保留,直到您删除它们。
有关将 CloudWatch 与 Aurora MySQL 日志配合使用的更多信息,请参阅 在 Amazon CloudWatch 中监控日志事件。
有关 CloudWatch 和 Aurora PostgreSQL 的更多信息,请参阅将 Aurora PostgreSQL 日志发布到 Amazon CloudWatch Logs。
要查看 Aurora Serverless v1 数据库集群的日志
通过以下网址打开 CloudWatch 控制台:https://console.aws.amazon.com/cloudwatch/
。 -
选择您的 Amazon Web Services 区域。
-
选择 Log groups(日志组)。
-
从列表中选择 Aurora Serverless v1 数据库集群日志。对于错误日志,命名模式如下。
/aws/rds/cluster/cluster-name/error
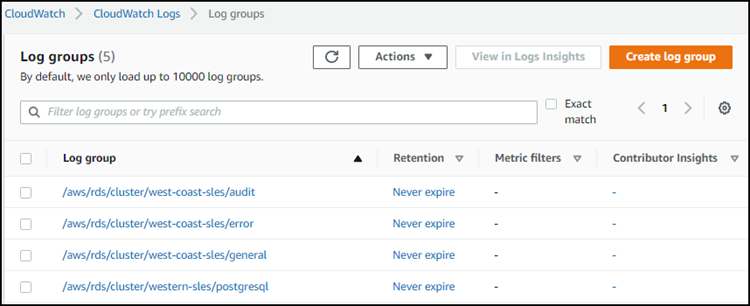
例如,在以下屏幕截图中,您可以找到为名为 western-sles 的 Aurora PostgreSQL Aurora Serverless v1 数据库集群发布的日志列表。您还可以找到 Aurora MySQL Aurora Serverless v1 数据库集群 west-coast-sles 的多个列表。选择感兴趣的日志以开始探索其内容。
Aurora Serverless v1 和维护
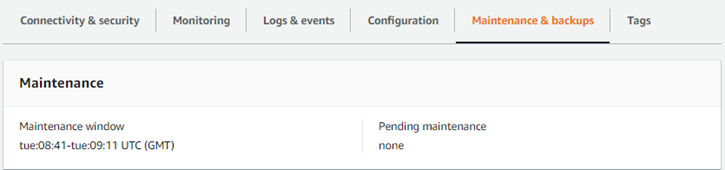
系统将自动为您执行 Aurora Serverless v1 数据库集群的维护(例如应用最新功能、修复程序和安全更新)。Aurora Serverless v1 有一个维护时段,您可以在 Amazon Web Services 管理控制台中 Aurora Serverless v1 数据库集群的维护和备份中查看。您可以查找可能执行维护的日期和时间,以及 Aurora Serverless v1 数据库集群是否有任何待处理的维护,如下图所示。
您可以在创建 Aurora Serverless v1 数据库集群时设置维护时段,并可以稍后修改该时段。有关更多信息,请参阅 调整首选数据库集群维护时段。
维护时段用于定期的主要版本升级。在扩展过程中,会立即应用次要版本升级和补丁。扩展根据您的 TimeoutAction 设置进行:
-
ForceApplyCapacityChange– 将立即应用更改。 -
RollbackCapacityChange– Aurora 会在第一次尝试应用补丁 3 天后强制更新集群。
与在没有适当扩展点的情况下强制进行的任何更改一样,这可能会中断您的工作负载。
Aurora Serverless v1 会尽可能以无中断的方式执行维护。当需要维护时,Aurora Serverless v1 数据库集群会扩展容量以处理必要的操作。在进行扩展之前,Aurora Serverless v1 会查找扩展点。如有必要,此操作最多可以持续三天。
在 Aurora Serverless v1 找不到扩展点的每一天结束时,它都会创建一个集群事件。此事件会通知您有关待处理的维护以及需要进行扩展以执行维护。该通知包括 Aurora Serverless v1 可以强制数据库集群扩展的日期。
有关更多信息,请参阅 容量更改超时操作。
Aurora Serverless v1 和失效转移
如果 Aurora Serverless v1 数据库集群的数据库实例变得不可用,或者其所在的可用区(AZ)出现故障,Aurora 会在其他可用区中重新创建数据库实例。但是,Aurora Serverless v1 集群不是多可用区集群。那是因为它只包含单个可用区中的单个数据库实例。因此,这个失效转移机制需要的时间比具有预置实例或 Aurora Serverless v2 实例的 Aurora 集群更长。未定义 Aurora Serverless v1 失效转移时间,因为它取决于给定 Amazon Web Services 区域中的其他可用区的需求和容量可用性。
由于 Aurora 分离计算容量和存储,因此,集群的存储卷分布在多个可用区中。即使中断影响数据库实例或关联的 AZ,您的数据也仍可用。
Aurora Serverless v1 和快照
Aurora Serverless v1 集群的集群卷始终是加密的。您可以选择加密密钥,但不能禁用加密。要复制或分享 Aurora Serverless v1 集群的快照,可使用您自己的 Amazon KMS key 对快照加密。有关更多信息,请参阅 数据库集群快照复制。要了解有关加密和 Amazon Aurora 的更多信息,请参阅加密 Amazon Aurora 数据库集群。