Data Quality Definition Language (DQDL) reference
Data Quality Definition Language (DQDL) is a domain specific language that you use to define rules for Amazon Glue Data Quality.
This guide introduces key DQDL concepts to help you understand the language. It also provides a reference for DQDL rule types with syntax and examples. Before you use this guide, we recommend that you have familiarity with Amazon Glue Data Quality. For more information, see Amazon Glue Data Quality.
Note
DynamicRules are only supported in Amazon Glue ETL.
Contents
DQDL syntax
A DQDL document is case sensitive and contains a ruleset, which groups individual data quality rules together. To construct a
ruleset, you must create a list named Rules (capitalized), delimited by a pair of
square brackets. The list should contain one or more comma-separated DQDL rules like the
following example.
Rules = [ IsComplete "order-id", IsUnique "order-id" ]
Rule structure
The structure of a DQDL rule depends on the rule type. However, DQDL rules generally fit the following format.
<RuleType> <Parameter> <Parameter> <Expression>
RuleType is the case-sensitive name of the rule type that you want to
configure. For example, IsComplete, IsUnique, or
CustomSql. Rule parameters differ for each rule type. For a complete
reference of DQDL rule types and their parameters, see DQDL rule type reference.
Composite rules
DQDL supports the following logical operators that you can use to combine rules. These rules are called Composite Rules.
- and
-
The logical
andoperator results intrueif and only if the rules that it connects aretrue. Otherwise, the combined rule results infalse. Each rule that you connect with theandoperator must be surrounded by parentheses.The following example uses the
andoperator to combine two DQDL rules.(IsComplete "id") and (IsUnique "id") - or
-
The logical
oroperator results intrueif and only if one or more of the rules that it connects aretrue. Each rule that you connect with theoroperator must be surrounded by parentheses.The following example uses the
oroperator to combine two DQDL rules.(RowCount "id" > 100) or (IsPrimaryKey "id")
You can use the same operator to connect multiple rules, so the following rule combination is allowed.
(Mean "Star_Rating" > 3) and (Mean "Order_Total" > 500) and (IsComplete "Order_Id")
You can combine the logical operators into a single expression. For example:
(Mean "Star_Rating" > 3) and ((Mean "Order_Total" > 500) or (IsComplete "Order_Id"))
You can also author more complex, nested rules.
(RowCount > 0) or ((IsComplete "colA") and (IsUnique "colA"))
How Composite rules work
By default, Composite Rules are evaluated as individual rules across the entire dataset or table and then the results are combined. In other words, it evaluates the entire column first and then applies the operator. This default behaviour is explained below with an example:
# Dataset +------+------+ |myCol1|myCol2| +------+------+ | 2| 1| | 0| 3| +------+------+ # Overall outcome +----------------------------------------------------------+-------+ |Rule |Outcome| +----------------------------------------------------------+-------+ |(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)|Failed | +----------------------------------------------------------+-------+
In the above example, Amazon Glue Data Quality first evaluates (ColumnValues "myCol1" > 1) which will result in
a failure. Then it will evaluate (ColumnValues "myCol2" > 2) which will also fail. The combination of both
results will be noted as FAILED.
However, if you prefer an SQL like behaviour, where you need the entire row to be evaluated, you have to explicitly
set the ruleEvaluation.scope parameter as shown in additionalOptions in the code snippet below.
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ (ColumnValues "age" >= 26) OR (ColumnLength "name" >= 4) ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "compositeRuleEvaluation.method":"ROW" } """ ) ) }
In Amazon Glue Data Catalog, you can easily configure this option in the user interface as shown below.
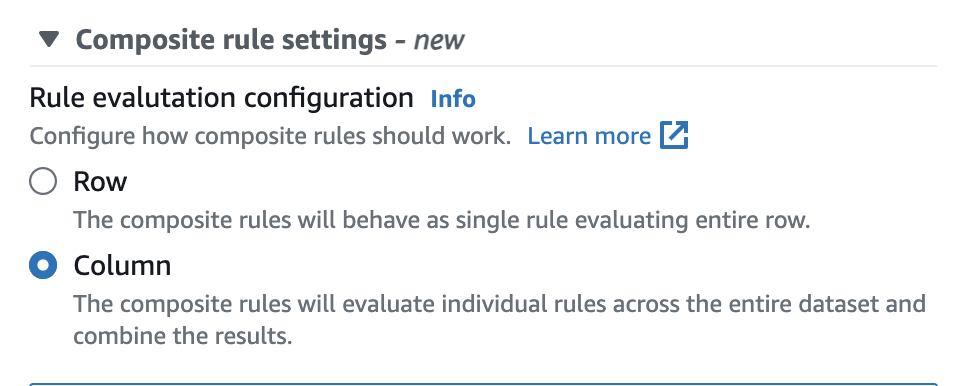
Once set, the composite rules will behave as a single rule evaluating the entire row. The following example illustrates this behaviour.
# Row Level outcome +------+------+------------------------------------------------------------+---------------------------+ |myCol1|myCol2|DataQualityRulesPass |DataQualityEvaluationResult| +------+------+------------------------------------------------------------+---------------------------+ |2 |1 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | |0 |3 |[(ColumnValues "myCol1" > 1) OR (ColumnValues "myCol2" > 2)]|Passed | +------+------+------------------------------------------------------------+---------------------------+
Some rules cannot be supported in this feature because their overall outcome rely on thresholds or ratios. They are listed below.
Rules relying on ratios:
-
Completeness
-
DatasetMatch
-
ReferentialIntegrity
-
Uniqueness
Rules dependent on thresholds:
When the following rules include with threshold, they are not supported. However, rules that do not involve
with threshold remain supported.
-
ColumnDataType
-
ColumnValues
-
CustomSQL
Expressions
If a rule type doesn't produce a Boolean response, you must provide an expression as a parameter in order to create a Boolean response. For example, the following rule checks the mean (average) of all the values in a column against an expression to return a true or false result.
Mean "colA" between 80 and 100
Some rule types such as IsUnique and IsComplete already return
a Boolean response.
The following table lists expressions that you can use in DQDL rules.
| Expression | Description | Example |
|---|---|---|
=x |
Resolves to true if the rule type response is equal to
x. |
|
!=x
|
x Resolves to true if the rule type response is not equal to x. |
|
> x |
Resolves to true if the rule type response is greater than
x. |
|
< x |
Resolves to true if the rule type response is less than
x. |
|
>= x |
Resolves to true if the rule type response is greater than or
equal to x. |
|
<= x |
Resolves to true if the rule type response is less than or equal
to x. |
|
between x and y |
Resolves to true if the rule type response falls in a specified
range (exclusive). Only use this expression type for numeric and date types. |
|
not between x and y
|
Resolves to true if the rule type response does not fall in a specified range (inclusive). You should only use this expression type for numeric and date types. |
|
in [a, b, c, ...] |
Resolves to true if the rule type response is in the specified
set. |
|
not in [a, b, c, ...] |
Resolves to true if the rule type response is not in the specified
set. |
|
matches /ab+c/i |
Resolves to true if the rule type response matches a regular
expression. |
|
not matches /ab+c/i |
Resolves to true if the rule type response does not match a regular
expression. |
|
now() |
Works only with the ColumnValues rule type to create a date
expression. |
|
matches/in […]/not matches/not in [...] with threshold |
Specifies the percentage of values that match the rule conditions. Works only
with the ColumnValues, ColumnDataType, and CustomSQL rule types. |
|
Keywords for NULL, EMPTY and WHITESPACES_ONLY
If you want to validate if a string column has a null, empty or a string with only whitespaces you can use the following keywords:
-
NULL / null – This keyword resolves to true for a
nullvalue in a string column.ColumnValues "colA" != NULL with threshold > 0.5would return true if more than 50% of your data does not have null values.(ColumnValues "colA" = NULL) or (ColumnLength "colA" > 5)would return true for all rows which either have a null value or have length >5. Note that this will require the use of the “compositeRuleEvaluation.method” = “ROW” option. -
EMPTY / empty – This keyword resolves to true for an empty string (“”) value in a string column. Some data formats transform nulls in a string column to empty strings. This keyword helps filter out empty strings in your data.
(ColumnValues "colA" = EMPTY) or (ColumnValues "colA" in ["a", "b"])would return true if a row is either empty, “a” or “b”. Note that this requires the use of the “compositeRuleEvaluation.method” = “ROW” option. -
WHITESPACES_ONLY / whitespaces_only – This keyword resolves to true for a string with only whitespaces (“ ”) value in a string column.
ColumnValues "colA" not in ["a", "b", WHITESPACES_ONLY]would return true if a row is neither “a” or “b” nor just whitespaces.Supported rules:
For a numeric or date based expression, if you want to validate if a column has a null you can use the following keywords.
-
NULL / null – This keyword resolves to true for a null value in a string column.
ColumnValues "colA" in [NULL, "2023-01-01"]would return true if a dates in your column are either2023-01-01or null.(ColumnValues "colA" = NULL) or (ColumnValues "colA" between 1 and 9)would return true for all rows which either have a null value or have values between 1 and 9. Note that this will require the use of the “compositeRuleEvaluation.method” = “ROW” option.Supported rules:
Filtering with Where Clause
Note
Where Clause is only supported in Amazon Glue 4.0.
You can filter your data when authoring rules. This is helpful when you want to apply conditional rules.
<DQDL Rule> where "<valid SparkSQL where clause> "
The filter must be specified with the where keyword, followed by a valid SparkSQL statement that is enclosed in
quotes ("").
If the rule you wish to add the where clause to a rule with a threshold, the where clause should be specified before the threshold condition.
<DQDL Rule> where "valid SparkSQL statement>" with threshold <threshold condition>
With this syntax you can write rules like the following.
Completeness "colA" > 0.5 where "colB = 10" ColumnValues "colB" in ["A", "B"] where "colC is not null" with threshold > 0.9 ColumnLength "colC" > 10 where "colD != Concat(colE, colF)"
We will validate that the SparkSQL statement provided is valid. If invalid, the rule evaluation will fail and we will
throw the an IllegalArgumentException with the following format:
Rule <DQDL Rule> where "<invalid SparkSQL>" has provided an invalid where clause : <SparkSQL Error>
Where clause behaviour when Row level error record identification is turned on
With Amazon Glue Data Quality, you can identify specific records that failed. When applying a where clause to rules that
support row level results, we will label the rows that are filtered out by the where clause as Passed.
If you prefer to separately label the filtered out rows as SKIPPED, you can set the following
additionalOptions for the ETL job.
object GlueApp { val datasource = glueContext.getCatalogSource( database="<db>", tableName="<table>", transformationContext="datasource" ).getDynamicFrame() val ruleset = """ Rules = [ IsComplete "att2" where "att1 = 'a'" ] """ val dq_results = EvaluateDataQuality.processRows( frame=datasource, ruleset=ruleset, additionalOptions=JsonOptions(""" { "rowLevelConfiguration.filteredRowLabel":"SKIPPED" } """ ) ) }
As an example, refer to the following rule and dataframe:
IsComplete att2 where "att1 = 'a'"
| id | att1 | att2 | Row-level Results (Default) | Row Level Results (Skipped Option) | Comments |
|---|---|---|---|---|---|
| 1 | a | f | PASSED | PASSED | |
| 2 | b | d | PASSED | SKIPPED | Row is filtered out, since att1 is not "a" |
| 3 | a | null | FAILED | FAILED | |
| 4 | a | f | PASSED | PASSED | |
| 5 | b | null | PASSED | SKIPPED | Row is filtered out, since att1 is not "a" |
| 6 | a | f | PASSED | PASSED |
Constants
In DQDL, you can define constant values and reference them throughout your script. This helps prevent issues related to query size limits—for example, when working with large SQL statements that might exceed allowable boundaries. By assigning these values to Constants, you can simplify your DQDL and avoid hitting those limits.
The following example shows how to define and use a constant:
mySql = "select count(*) from primary" Rules = [ CustomSql $mySql between 0 and 100 ]
In this example, the SQL query is assigned to the constant mySql, which is then referenced in the rule using the $ prefix.
Labels
Labels provide an effective way to organize and analyze data quality results. You can query results by specific labels to identify failing rules within particular categories, count rule outcomes by team or domain, and create focused reports for different stakeholders.
For example, you can apply all rules that pertain to the finance team with a label "team=finance" and generate a customized report to showcase quality metrics specific to the finance team. You can label high priority rules with "criticality=high" to prioritize remediation efforts. Labels can be authored as part of the DQDL. You can query the labels as part of rule outcomes, row-level results, and API responses, making it easy to integrate with your existing monitoring and reporting workflows.
Note
Labels are only available in Amazon Glue ETL and are not available in Amazon Glue Data Catalog based Data Quality.
Syntax for DQDL labels
DQDL supports both default and rule-specific labels. Default labels are defined at the ruleset level and automatically apply to all rules within that ruleset. Individual rules can also have their own labels, and since labels are implemented as key-value pairs, rule-specific labels can override the default labels when using the same key.
The following example shows how to use default and rule-specific labels:
DefaultLabels=["frequency"="monthly"] Rules = [ // Auto includes the default label ["frequency"="monthly"] ColumnValues "col" > 21, // Add ["foo"="bar"] to default label. Labels for this rule would be ["frequency"="monthly", "foo"="bar"] RowCount > 0 with threshold > 0.8 labels=["foo"="bar"], // Override default label. Labels for this rule would be ["frequency"="daily", "foo"="bar"] ColumnValues "colA" in ["A", "B"] with threshold > 0.8 labels=["foo"="bar", "frequency"="daily"] // Labels must be applied to the entire composite rule (parentheses required) (isComplete "col" AND RowCount > 0) labels=["foo"="bar] ]
The following example shows invalid syntax with labels and composite rules:
(isComplete "colA") AND (RowCount > 0) labels=["foo"="bar"] (isComplete "colA" labels=["foo"="bar"]) AND (RowCount > 0) isComplete "col" AND RowCount > 0 labels=["foo"="bar]
Label constraints
Labels have the following constraints:
-
A maximum of 10 labels per DQDL rule.
-
Labels are specified as a list of key-value pairs.
-
The label key and label value are case sensitive.
-
The maximum label key length is 128 characters. The label key must not be empty or null.
-
The maximum label value length is 256 characters. The label value may be empty or null.
Retrieving DQDL labels
You can retrieve DQDL labels from rule outcomes, row-level results, and API responses.
Rule outcomes
DQDL labels are always visible in rule outcomes. No additional configuration is needed to enable them.
Row-level results
DQDL labels are disabled by default in row-level results but can be enabled using AdditionalOptions in EvaluateDataQuality.
The following example shows how to enable labels in row-level results:
val evaluateResult = EvaluateDataQuality.processRows( frame=AmazonS3_node1754591511068, ruleset=example_ruleset, publishingOptions=JsonOptions("""{ "dataQualityEvaluationContext": "evaluateResult", "enableDataQualityCloudWatchMetrics": "true", "enableDataQualityResultsPublishing": "true" }"""), additionalOptions=JsonOptions("""{ "performanceTuning.caching":"CACHE_NOTHING", "observations.scope":"ALL", "rowLevelConfiguration.ruleWithLabels":"ENABLED" }""") )
When enabled, the row-level results dataframe includes labels for each rule in the DataQualityRulesPass, DataQualityRulesFail, and DataQualityRulesSkip columns.
API response
DQDL labels are always visible in API responses under a new field Labels in the RuleResults object.
The following example shows labels in an API response:
{ "ResultId": "dqresult-example", "ProfileId": "dqprofile-example", "Score": 0.6666666666666666, "RulesetName": "EvaluateDataQuality_node1754591514205", "EvaluationContext": "EvaluateDataQuality_node1754591514205", "StartedOn": "2025-08-22T19:36:10.448000+00:00", "CompletedOn": "2025-08-22T19:36:16.368000+00:00", "JobName": "anniezc-test-labels", "JobRunId": "jr_068f6d7a45074d9105d14e4dee09db12c3b95664b45f6ee44fa29ed7e5619ba8", "RuleResults": [ { "Name": "Rule_0", "Description": "IsComplete colA", "EvaluationMessage": "Input data does not include column colA!", "Result": "FAIL", "EvaluatedMetrics": {}, "EvaluatedRule": "IsComplete colA", "Labels": { "frequency": "monthly" } }, { "Name": "Rule_1", "Description": "Rule 1 with threshold > 0.8", "Result": "PASS", "EvaluatedMetrics": {}, "EvaluatedRule": "Rule 1 with threshold > 0.8", "Labels": { "frequency": "monthly", "foo": "bar" } }, { "Name": "Rule_3", "Description": "Rule 2 with threshold > 0.8", "Result": "PASS", "EvaluatedMetrics": {}, "EvaluatedRule": "Rule 2 with threshold > 0.8", "Labels": { "frequency": "daily", "foo": "bar" } } ] }
Dynamic rules
Note
Dynamic Rules are only supported in Amazon Glue ETL and is not supported in Amazon Glue Data Catalog.
You can now author dynamic rules to compare current metrics produced by your rules with
their historical values. These historical comparisons are enabled by using the
last() operator in expressions. For example, the rule RowCount >
last() will succeed when the number of rows in the current run is greater than the
most recent prior row count for the same dataset. last() takes an optional
natural number argument describing how many prior metrics to consider; last(k) where k
>= 1 will reference the last k metrics.
-
If no data points are available,
last(k)will return the default value 0.0. -
If fewer than
kmetrics are available,last(k)will return all prior metrics.
To form valid expressions use last(k), where k > 1 requires an aggregation function to reduce multiple historical results
to a single number. For example, RowCount > avg(last(5)) will check whether the
current dataset’s row count is strictly greater than the average of the last five row counts for the same dataset.
RowCount > last(5) will produce an error because the current dataset row count can't be meaningfully compared to a list.
Supported aggregation functions:
-
avg -
median -
max -
min -
sum -
std(standard deviation) -
abs(absolute value) -
index(last(k), i)will allow for selecting theith most recent value out of the lastk.iis zero-indexed, soindex(last(3), 0)will return the most recent datapoint andindex(last(3), 3)will result in an error as there are only three datapoints and we attempt to index the 4th most recent one.
Sample expressions
ColumnCorrelation
ColumnCorrelation "colA" "colB" < avg(last(10))
DistinctValuesCount
DistinctValuesCount "colA" between min(last(10))-1 and max(last(10))+1
Most rule types with numeric conditions or thresholds support dynamic rules; see the provided table, Analyzers and Rules, to determine whether dynamic rules are supported for your rule type.
Excluding statistics from dynamic rules
Sometimes, you will need to exclude data statistics from your dynamic rule calculations. Lets say you did a historical data load and you don’t want that to impact your averages. To do this, open the job in Amazon Glue ETL and choose the Data Quality Tab, then choose Statistics and select the statistics that you want to exclude. You will be able to see a trend chart along with a table of statistics. Select the values you want to exclude and choose Exclude Statistics. Now the excluded statistics will not be included in the dynamic rule calculations.
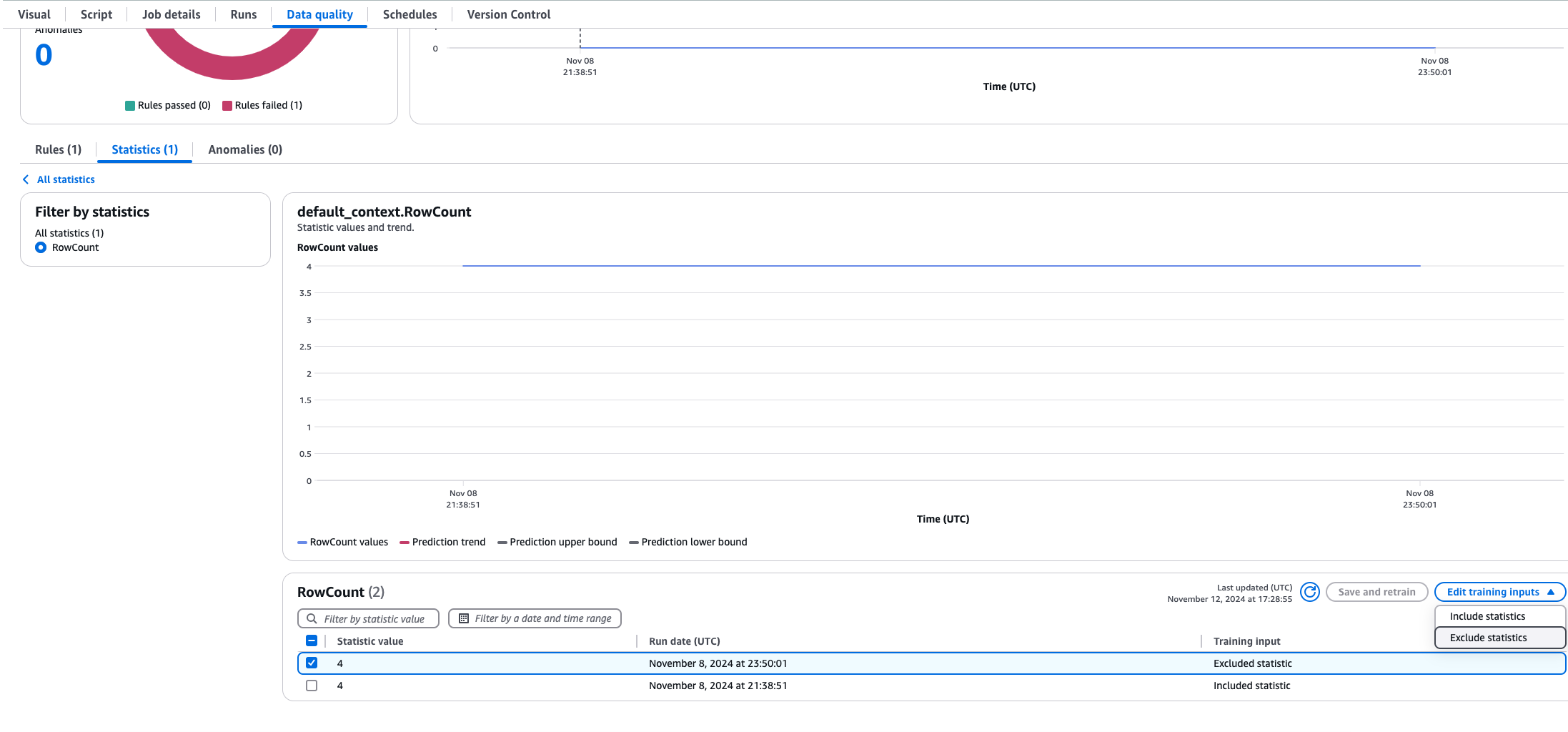
Analyzers
Note
Analyzers are not supported in Amazon Glue Data Catalog.
DQDL rules use functions called analyzers to gather information about your
data. This information is employed by a rule’s Boolean expression to determine whether the rule should succeed or fail.
For example, the RowCount rule RowCount > 5 will use a row count analyzer to discover the number of rows in your dataset,
and compare that count with the expression > 5 to check whether more than five rows exist in the current dataset.
Sometimes, instead of authoring rules, we recommend creating analyzers and then have them generate statistics that can be used to detect anomalies. For such instances, you can create analyzers. Analyzers differ from rules in the following ways.
| Characteristic | Analyzers | Rules |
|---|---|---|
| Part of ruleset | Yes | Yes |
| Generates statistics | Yes | Yes |
| Generates observations | Yes | Yes |
| Can evaluate and assert a condition | No | Yes |
| You can configure actions such as stop the jobs on failure, continue processing job | No | Yes |
Analyzers can independently exist without rules, so you can quickly configure them and progressively build data quality rules.
Some rule types can be input in the Analyzers block of your ruleset to run
the rules required for analyzers and gather information without applying checks for any condition. Some analyzers
aren't associated with rules and can only be input in the Analyzers block.
The following table indicates whether each item is supported as a rule or
a standalone analyzer, along with additional details for each rule type.
Example Ruleset with Analyzer
The following ruleset uses:
-
a dynamic rule to check whether a dataset is growing over its trailing average for the last three job runs
-
a
DistinctValuesCountanalyzer to record the number of distinct values in the dataset'sNamecolumn -
a
ColumnLengthanalyzer to track minimum and maximumNamesize over time
Analyzer metric results can be viewed in the Data Quality tab for your job run.
Rules = [ RowCount > avg(last(3)) ] Analyzers = [ DistinctValuesCount "Name", ColumnLength "Name" ]
Amazon Glue Data Quality supports the following analyzers.
| Analyzer name | Functionality |
|---|---|
RowCount |
Computes row counts for a dataset |
Completeness |
Computes the completeness percentage of a column |
Uniqueness |
Computes the uniqueness percentage of a column |
Mean |
Computes mean of a numeric column |
Sum |
Computes sum of a numeric column |
StandardDeviation |
Computes standard deviation of a numeric column |
Entropy |
Computes entropy of a numeric column |
DistinctValuesCount |
Computes the number of distinct values in a column |
UniqueValueRatio |
Computes the unique values ratio in a column |
ColumnCount |
Computes the number of columns in a dataset |
ColumnLength |
Computes the length of a column |
ColumnValues |
Computes the minimum, maximum for numerical columns. Computes Minimum ColumnLength and Maximum ColumnLength for non-numeric columns |
ColumnCorrelation |
Computes column correlations for given columns |
CustomSql |
Computes statistics returned by the CustomSQL |
AllStatistics |
Computes the following statistics:
|
Comments
You can use the '#' character to add a comment to your DQDL document. Anything after the '#' character and until the end of the line is ignored by DQDL.
Rules = [ # More items should generally mean a higher price, so correlation should be positive ColumnCorrelation "price" "num_items" > 0 ]