Amazon Glue 组件
Amazon Glue 提供控制台和 API 操作来设置和管理您的提取、转换和加载 (ETL) 工作负载。您可以通过多个特定于语言的开发工具包和 Amazon Command Line Interface (Amazon CLI) 来使用 API 操作。有关使用 Amazon CLI 的信息,请参阅 Amazon CLI 命令参考。
Amazon Glue 使用 Amazon Glue Data Catalog来存储有关数据源、转换和目标的元数据。数据目录是 Apache Hive 元存储的简易替代。Amazon Glue Jobs system提供用于为您的数据定义、安排和运行 ETL 操作的托管基础设施。有关 Amazon Glue API 的更多信息,请参阅Amazon Glue API。
Amazon Glue 管理控制台
您可以使用 Amazon Glue 控制台来定义和协调您的 ETL 工作流程。该控制台在 Amazon Glue Data Catalog和 Amazon Glue Jobs system中调用多个 API 操作以执行以下任务:
-
定义 Amazon Glue 对象,如作业、表、爬网程序和连接。
-
安排爬网程序的运行时间。
-
为作业触发器定义事件或计划。
-
搜索和筛选 Amazon Glue 对象的列表。
-
Edit 转换脚本。
Amazon Glue Data Catalog
Amazon Glue Data Catalog 是您在 Amazon 云中的持久性技术元数据存储。
每个 Amazon 账户在每个 Amazon 区域有一个 Amazon Glue Data Catalog。每个数据目录都是组织成数据库的高度可扩展的表集合。表是存储在 Amazon RDS、Apache Hadoop Distributed File System、Amazon OpenSearch Service 等源中的结构化或半结构化数据集合的元数据表示形式。Amazon Glue Data Catalog 提供了一个统一的存储库,不同的系统可以在其中存储和查找元数据来跟踪数据孤岛中的数据。然后,您可以使用元数据在各种应用程序中以统一的方式查询和转换该数据。
您将数据目录与 Amazon Identity and Access Management 策略和 Lake Formation 一同使用,从而控制对表和数据库的访问。通过这样做,您可以允许企业中的不同组将数据安全地发布到更广泛的组织,同时以高度精细的方式保护敏感信息。
数据目录以及 CloudTrail 和 Lake Formation 还提供全面的审计和监管功能,其中有架构更改跟踪和数据访问控制。这有助于确保数据不会被不当修改或无意中共享。
有关保护及审计 Amazon Glue Data Catalog 的信息,请参阅:
-
Amazon Lake Formation – 有关更多信息,请参阅《Amazon Lake Formation 开发人员指南》中的 什么是 Amazon Lake Formation?
-
CloudTrail – 有关更多信息,请参阅 Amazon CloudTrail 用户指南中的什么是 CloudTrail?
以下是其他 Amazon 服务和使用 Amazon Glue Data Catalog 的开源项目:
-
Amazon Athena – 有关更多信息,请参阅《Amazon Athena 用户指南》中的 了解表、数据库和数据目录。
-
Amazon Redshift Spectrum – 有关更多信息,请参阅《Amazon Redshift 数据库开发人员指南》中的 使用 Amazon Redshift Spectrum 查询外部数据。
-
Amazon EMR – 有关更多信息,请参阅《Amazon EMR 管理指南》中的 使用基于资源的策略实现 Amazon EMR 对 Amazon Glue Data Catalog 的访问。
-
Apache Hive 元存储的 Amazon Glue Data Catalog 客户端 – 有关此 GitHub 项目的更多信息,请参阅 Apache Hive 元存储的 Amazon Glue Data Catalog 客户端
。
Amazon Glue 爬网程序和分类器
Amazon Glue 还能让您设置爬网程序,它可以扫描所有类型的存储库中的数据,对其进行分类,从中提取架构信息,并自动在 Amazon Glue Data Catalog中存储元数据。然后 Amazon Glue Data Catalog 可用于指导 ETL 操作。
有关如何设置爬网程序和分类器的信息,请参阅使用爬网程序填充 Data Catalog。有关如何使用 Amazon Glue API 编程爬网程序和分类器的信息,请参阅爬网程序和分类器 API。
Amazon Glue ETL 操作
通过使用数据目录中的元数据,Amazon Glue 可以自动生成具有 Amazon Glue 扩展的 Scala 或 PySpark(用于 Apache Spark 的 Python API)脚本,您可以使用和修改它来执行各种 ETL 操作。例如,您可以提取、清除和转换原始数据,然后将结果存储在不同的存储库中,以便可以对其进行查询和分析。此类脚本可能会将 CSV 文件转换为关系形式并将其保存到 Amazon Redshift 中。
有关如何使用 Amazon Glue ETL 功能的更多信息,请参阅Spark 脚本编程。
Amazon Glue 中的流式处理 ETL
通过 Amazon Glue,您能够使用连续运行的任务对流数据执行 ETL 操作。Amazon Glue 流式处理 ETL 基于 Apache Spark Structured Streaming 引擎而构建,可以从 Amazon Kinesis Data Streams、Apache Kafka 和 Amazon Managed Streaming for Apache Kafka(Amazon MSK)提取流。流式处理 ETL 可以清理和转换流数据,并将其加载到 Amazon S3 或 JDBC 数据存储中。在 Amazon Glue 中使用流式处理 ETL 可以处理 IoT 流、点击流和网络日志等事件数据。
如果您知道流数据源的架构,则可以在数据目录表中指定该架构。如果没有,则可以在流式 ETL 任务中启用架构检测。然后,任务会根据传入的数据自动确定架构。
流式处理 ETL 任务可以同时使用 Amazon Glue 内置转换和 Apache Spark Structured Streaming 的原生转换。有关更多信息,请参阅 Apache Spark 网站上的流式处理 DataFrame/数据集的操作
有关更多信息,请参阅 在 Amazon Glue 中流式处理 ETL 作业。
Amazon Glue 作业系统
Amazon Glue Jobs system提供托管基础设施以协调 ETL 工作流程。您可以在 Amazon Glue 中创建作业,用于自动处理您用于提取、转换数据并将数据传输到不同位置的脚本。作业可以安排和串联,也可以由诸如新数据到达之类的事件触发。
有关如何使用 Amazon Glue Jobs system的更多信息,请参阅监控 Amazon Glue。有关使用 Amazon Glue Jobs system API 编程的信息,请参阅作业 API。
Visual ETL 组件
使用 Amazon Glue 可以通过可操作的可视画布创建 ETL 作业。
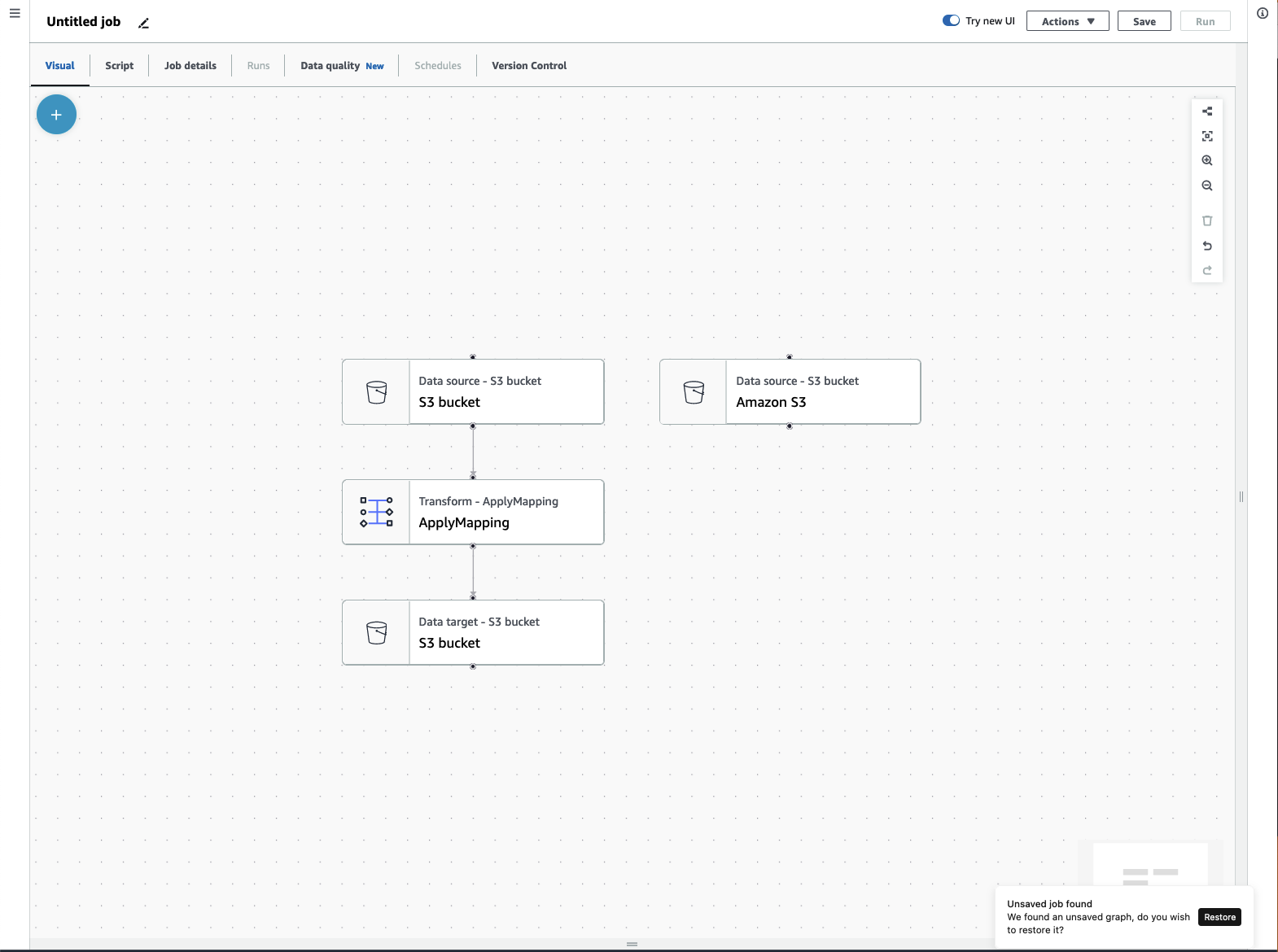
ETL 作业菜单
使用画布顶部的菜单选项可以访问有关作业的各种视图和配置详细信息。
-
可视化 — 可视化任务编辑器画布。您可以在此处添加节点以创建任务。
-
脚本 – ETL 作业的脚本表示形式。AmazonGlue 基于作业的可视化表示形式来生成脚本。您也可以编辑脚本或下载脚本。
注意
如果您选择编辑脚本,则作业创作体验将永久转换为纯脚本模式。之后,您将无法再使用可视化编辑器来编辑作业。在选择编辑脚本之前,您应该添加所有作业源、转换和目标,并使用可视化编辑器进行所需的所有更改。
-
作业详细信息 —“作业详细信息”选项卡允许您通过设置作业属性来配置作业。有多个基本属性,例如您的作业名称和描述、IAM 角色、作业类型、Amazon Glue 版本、语言、工作线程类型、工作线程数量、作业书签、弹性执行、重试次数和作业超时等,还有多个高级属性,例如连接、库、作业参数和标签等。
-
运行 — 作业运行后,可以访问此选项卡以查看您过去的作业运行情况。
-
数据质量 — 数据质量评估和监控数据资产的质量。您可以在此选项卡上详细了解如何使用数据质量,并在作业中添加数据质量转换。
-
计划 — 您已计划的作业显示在此选项卡中。如果此作业没有附加计划,则无法访问此选项卡。
-
版本控制 — 您可以将作业配置到 Git 存储库,从而将 Git 用于您的作业。
Visual ETL 面板
当您在画布中工作时,有几个面板可以帮助您配置节点,或者帮助您预览数据和查看输出架构。
-
属性 — 当您在画布上选择节点时,将出现“属性”面板。
-
数据预览 —“数据预览”面板提供数据输出的预览,这样您就可以在运行作业和检查输出之前做出决策。
-
输出架构 —“输出架构”选项卡允许您查看和编辑转换节点的架构。
调整面板大小
您可以调整屏幕右侧的“属性”面板以及包含“数据预览”和“输出架构”选项卡的底部面板的大小,方法是单击面板边缘并向左和向右或向上和向下拖动。
-
属性面板 — 通过单击并拖动屏幕右侧画布边缘来调整属性面板的大小,然后向左拖动以扩大其宽度。默认情况下,面板处于折叠状态,当选择节点时,属性面板会以其默认大小打开。
-
数据预览和输出架构面板 — 通过单击并拖动屏幕底部画布的底部边缘来调整底部面板的大小,然后向上拖动以扩大其高度。默认情况下,面板处于折叠状态,当选择节点时,底部面板会以其默认大小打开。
作业画布
您可以直接在 Visual ETL 画布上添加、移除和移动/重新排序节点。可以把它想象成您的工作空间,用来创建一个功能齐全的 ETL 作业,该作业从数据来源开始,可以以数据目标结尾。
当您在画布上处理节点时,您可以使用一个工具栏帮助您放大和缩小、移除节点、建立或编辑节点之间的连接、更改作业流方向以及撤销或重做操作。

浮动工具栏固定在画布的右上角大小,其中包含几张执行操作的图像:
-
布局图标 — 工具栏中的第一个图标是布局图标。默认情况下,视觉作业的方向是从上到下。它通过从左到右水平排列节点来重新排列可视化作业的方向。再次单击布局图标将方向更改为从上到下。
-
重新居中图标 — 重新居中图标通过居中来更改画布视图。您可以用它来处理大型作业,回到中心位置。
-
放大图标 — 放大图标可放大画布上节点的大小。
-
缩小图标 — 缩小图标可缩小画布上节点的大小。
-
垃圾桶图标 — 垃圾桶图标将节点从可视化作业中移除。必须先选择一个节点。
-
撤销图标 — 撤销图标会撤销上次对可视化作业执行的操作。
-
重做图标 — 重做图标会重复对可视化作业执行的上一个操作。
使用迷你地图

资源面板
资源面板包含所有可用的数据来源、转换操作和连接。单击“+”图标在画布上打开资源面板。这将打开资源面板。
要关闭资源面板,请单击资源面板右上角的 X。这将隐藏面板,直到您准备好再次打开它为止。
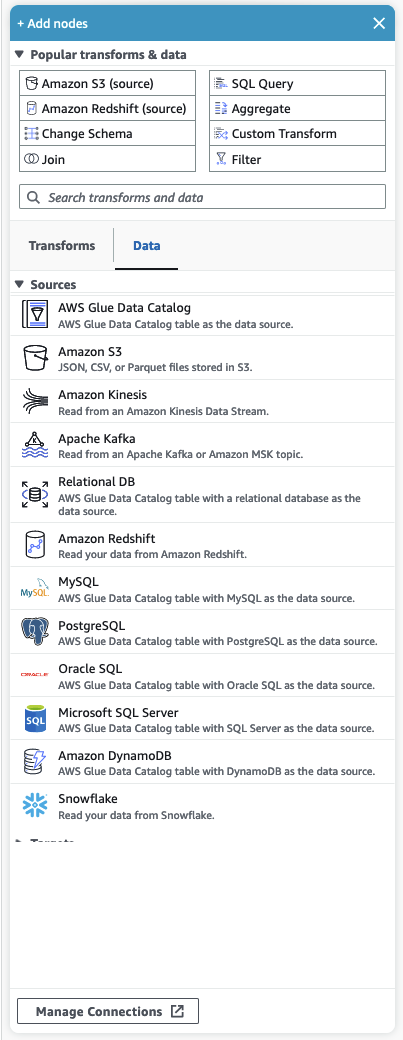
常用转换和数据
面板顶部是常用转换和数据的集合。这些节点在 Amazon Glue 中很常用。选择一个将其添加到画布中。也可以通过单击常用转换和数据标题旁边的三角形来隐藏常用转换和数据。
在常用转换和数据部分下方,您可以搜索转换和数据来源节点。在您键入时会显示结果。您在搜索查询中添加的字母越多,结果列表就会越小。搜索结果是根据节点名称和/或描述填充的。选择一个节点将其添加到画布中。
转换和数据
有两个选项卡可将节点组织为转换和数据。
转换 — 选择转换选项卡时,可以选择所有可用的转换。选择一个转换将其添加到画布中。您也可以选择转换列表底部的添加转换,这将打开一个用于创建自定义视觉转换的文档的新页面。按照这些步骤操作可以创建您自己的转换。然后,您的转换将出现在可用转换列表中。
数据 — 数据选项卡包含来源和目标的所有节点。您可以通过单击“来源”或“目标”标题旁边的三角形来隐藏“来源”和“目标”。您可以通过再次单击三角形来取消隐藏来源和目标。选择来源节点或目标节点将其添加到画布中。您也可以选择管理连接来添加新连接。这将在控制台中打开“连接”页面。