在 Amazon Glue 中流式处理 ETL 作业
您可以创建连续运行的串流提取、转换和负载(ETL)任务,使用来自 Amazon Kinesis Data Streams、Apache Kafka 和 Amazon Managed Streaming for Apache Kafka(Amazon MSK)等串流源的数据。这些任务会清理并转换数据,然后将结果加载到 Amazon S3 数据湖或 JDBC 数据存储中。
此外,您还可以为 Amazon Kinesis Data Streams 流生成数据。此功能在编写 Amazon Glue 脚本时才可用。有关更多信息,请参阅 Kinesis 连接。
默认情况下,Amazon Glue 在 100 秒的时段内处理和写出数据。这可以实现数据的高效处理,并允许对晚于预计时间到达的数据执行聚合。您可以修改此窗口时段的大小以提高及时性或聚合精度。Amazon Glue 串流任务使用检查点而非任务书签来跟踪已读取的数据。
注意
当串流 ETL 任务正在运行时,Amazon Glue 会按小时计费。
本视频讨论了 Amazon Glue 中流式传输 ETL 的成本挑战以及节省成本功能。
创建串流 ETL 任务涉及以下步骤:
-
对于 Apache Kafka 串流源,请创建与 Kafka 源或 Amazon MSK 集群的 Amazon Glue 连接。
-
手动为串流源创建数据目录表。
-
为串流数据源创建 ETL 任务。定义特定于串流的任务属性,并提供您自己的脚本或(可选)修改生成的脚本。
有关更多信息,请参阅 Amazon Glue 中的流式处理 ETL。
为 Amazon Kinesis Data Streams 创建串流 ETL 任务时,您无需创建 Amazon Glue 连接。但是,如果有一个连接附加到以 Kinesis Data Streams 作为源的 Amazon Glue 串流 ETL 任务,则需要提供到 Kinesis 的 Virtual Private Cloud(VPC)终端节点。有关更多信息,请参阅 Amazon VPC 用户指南中的创建接口端点 在另一个账户中指定 Amazon Kinesis Data Streams 串流时,您必须设置角色和策略从而允许跨账户访问。有关更多信息,请参阅示例:从不同账户的 Kinesis 串流中读取。
Amazon Glue 流式传输 ETL 任务可以自动检测压缩数据,以透明方式解压流式传输数据,对输入源执行常见转换,并加载到输出存储。
如果是以下输入格式,则 Amazon Glue 支持自动解压以下压缩类型:
| 压缩类型 | Avro 文件 | Avro 基准 | JSON | CSV | Grok |
|---|---|---|---|---|---|
| BZIP2 | 支持 | 是 | 是 | 是 | 是 |
| GZIP | 否 | 是 | 是 | 是 | 是 |
| SNAPPY | 是(原始 Snappy) | 是(framed Snappy) | 是(framed Snappy) | 是(framed Snappy) | 是(framed Snappy) |
| XZ | 支持 | 是 | 是 | 是 | 是 |
| ZSTD | 是 | 否 | 否 | 否 | 否 |
| DEFLATE | 支持 | 是 | 是 | 是 | 是 |
主题
为 Apache Kafka 数据流创建 Amazon Glue 连接
要从 Apache Kafka 流中进行读取,您必须创建 Amazon Glue 连接。
为 Kafka 源创建 Amazon Glue 连接(控制台)
通过 https://console.aws.amazon.com/glue/
打开 Amazon Glue 控制台。 -
在导航窗格的 Data catalog (数据目录) 下,选择 Connections (连接)。
-
选择 Add connection (添加连接),然后在 Set up your connection’s properties (设置连接的属性) 页面上,输入连接名称。
注意
有关指定连接属性的更多信息,请参阅 Amazon Glue连接属性。。
-
对于 Connection type (连接类型),选择 Kafka。
-
对于 Kafka bootstrap servers URLs (Kafka 引导服务器 URL),输入您 Amazon MSK 集群或 Apache Kafka 集群引导代理的主机和端口编号。仅使用传输层安全性(TLS)端点建立到 Kafka 群集的初始连接。不支持 Plaintext 端点。
以下是 Amazon MSK 集群的主机名和端口编号对的示例列表。
myserver1.kafka.us-east-1.amazonaws.com:9094,myserver2.kafka.us-east-1.amazonaws.com:9094, myserver3.kafka.us-east-1.amazonaws.com:9094有关引导代理信息的更多信息,请参阅 Amazon Managed Streaming for Apache Kafka 开发人员指南中的获取 Amazon MSK 集群的引导代理。
-
如果您希望与 Kafka 数据源建立安全连接,请选择 Require SSL connection (需要 SSL 连接),并在 Kafka private CA certificate location (Kafka 私有 CA 证书位置) 中,输入自定义 SSL 证书的有效 Amazon S3 路径。
对于与自我托管式 Kafka 的 SSL 连接,自定义证书是强制性的。对于 Amazon MSK 则是可选的。
有关为 Kafka 指定自定义证书的更多信息,请参阅 Amazon Glue SSL 连接属性。
-
使用 Amazon Glue Studio 或 Amazon CLI 指定 Kafka 客户端身份认证方法。要访问 Amazon Glue Studio,请从左侧导航窗格的 ETL 菜单中选择 Amazon Glue。
有关 Kafka 客户端身份认证方法的更多信息,请参阅适用于客户端身份认证的 Amazon Glue Kafka 连接属性。
-
(可选)输入描述,然后选择 Next (下一步)。
-
对于 Amazon MSK 集群,请指定其 Virtual Private Cloud(VPC)、子网和安全组。对于自行托管式 Kafka,VPC 信息是可选的。
-
选择 Next (下一步) 以查看所有连接属性,然后选择 Finish (结束)。
有关 Amazon Glue 连接的更多信息,请参阅 连接到数据。
适用于客户端身份认证的 Amazon Glue Kafka 连接属性
- SASL/GSSAPI(Kerberos)身份认证
-
选择此身份认证方法将允许您指定 Kerberos 属性。
- Kerberos Keytab
-
选择 keytab 文件的位置。keytab 可存储一个或多个主体的长期密钥。有关更多信息,请参阅 MIT Kerberos 文档:keytab
。 - Kerberos krb5.conf 文件
-
选择 krb5.conf 文件。它包含默认领域(一种类似于域的逻辑网络,用于定义同一 KDC 下的一组系统)和 KDC 服务器的位置。有关更多信息,请参阅 MIT Kerberos 文档:krb5.conf
。 - Kerberos 主体和 Kerberos 服务名称
-
输入 Kerberos 主体和服务名称 有关更多信息,请参阅 MIT Kerberos 文档:Kerberos 主体
。 - SASL/SCRAM-SHA-512 身份认证
-
选择此身份认证方法将允许您指定身份认证凭证。
- Amazon Secrets Manager
-
在搜索框中键入相应的名称或 ARN 以搜索令牌。
- 直接提供用户名和密码
-
在搜索框中键入相应的名称或 ARN 以搜索令牌。
- SSL 客户端身份认证
-
选择此身份认证方法将允许您浏览 Amazon S3 以选择 Kafka 客户端密钥库的位置。或者,您可以输入 Kafka 客户端密钥库密码和 Kafka 客户端密钥密码。
- IAM 身份验证
-
此身份验证方法不需要任何其他规范,仅在流媒体源为 MSK Kafka 时适用。
- SASL/PLAIN 身份验证
-
选择此身份验证方法将让您能够指定身份验证凭证。
为串流源创建数据目录表
您可以为流式传输源手动创建数据目录表,以指定源数据流属性(包括数据 Schema)。此表用作串流 ETL 任务的数据源。
如果您不知道源数据流中数据的架构,则可以在不使用架构的情况下创建表。然后,当您创建串流 ETL 任务时,您可以打开 Amazon Glue 架构检测函数。Amazon Glue 会通过流数据来确定架构。
可使用 Amazon Glue 控制台
注意
无法使用 Amazon Lake Formation 控制台创建表;必须使用 Amazon Glue 控制台。
另外,请考虑以下有关 Avro 格式的串流源或可以应用 Grok 模式的日志数据的信息。
Kinesis 数据源
在创建表时,请设置以下串流 ETL 属性(控制台)。
- 源的类型
-
Kinesis
- 对于同一账户中的 Kinesis 源:
-
- 区域
-
存在 Amazon Kinesis Data Streams 服务的 Amazon 区域。“区域”和 Kinesis 流名称会一起转换为“流 ARN”。
示例:https://kinesis.us-east-1.amazonaws.com
- Kinesis 流名称
-
流名称如《Amazon Kinesis Data Streams 开发人员指南》https://docs.amazonaws.cn/streams/latest/dev/kinesis-using-sdk-java-create-stream.html中的创建流所述。
- 有关其他账户中的 Kinesis 源,请参阅此示例来设置角色和策略以允许进行跨账户访问。配置以下设置:
-
- 流 ARN
-
使用者用于注册的 Kinesis Data Streams ARN。有关更多信息,请参阅 Amazon Web Services 一般参考 中的 Amazon Resource Names (ARNs) and Amazon Service Namespaces。
- 所担任角色的 ARN
-
担任角色的 Amazon Resource Name(ARN)。
- 会话名称(可选)
-
所担任角色会话的标识符。
在根据不同规则或因为不同原因担任相同角色时,使用角色会话名称对会话进行唯一标识。在跨账户方案中,角色会话名称对于拥有此角色的账户可见,并且可以由拥有该角色的账户记录。所担任角色规则的 ARN 中也使用角色会话名称。这意味着使用临时安全证书的后续跨账户 API 请求会在其 Amazon CloudTrail 日志中将角色会话名称公开给外部账户。
为 Amazon Kinesis Data Streams 设置串流 ETL 属性(Amazon Glue API 或 Amazon CLI)
-
要为同一账户中的 Kinesis 源设置串流 ETL 属性,请在
CreateTableAPI 操作或create_tableCLI 命令的StorageDescriptor结构中指定streamName和endpointUrl参数。"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamName": "sample-stream", "endpointUrl": "https://kinesis.us-east-1.amazonaws.com" } ... }或者,指定
streamARN。例
"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream" } ... } -
要为其他账户中的 Kinesis 源设置串流 ETL 属性,请在
CreateTableAPI 操作或create_tableCLI 命令的StorageDescriptor结构中指定streamARN、awsSTSRoleARN和awsSTSSessionName(可选)参数。"StorageDescriptor": { "Parameters": { "typeOfData": "kinesis", "streamARN": "arn:aws:kinesis:us-east-1:123456789:stream/sample-stream", "awsSTSRoleARN": "arn:aws:iam::123456789:role/sample-assume-role-arn", "awsSTSSessionName": "optional-session" } ... }
Kafka 数据源
在创建表时,请设置以下串流 ETL 属性(控制台)。
- 源的类型
-
Kafka
- 对于 Kafka 源:
-
- 主题名称
-
Kafka 中指定的主题名称。
- 连接
-
一个引用 Kafka 源的 Amazon Glue 连接,如 为 Apache Kafka 数据流创建 Amazon Glue 连接 中所述。
Amazon Glue 架构注册表源
要将 Amazon Glue 架构注册表用于串流任务,请按照位于 使用案例:Amazon Glue Data Catalog 的说明创建或更新架构注册表。
目前,Amazon Glue 串流仅支持架构推理推断设置为 false 的 Glue Schema Registry Avro 格式。
Avro 串流源的注释和限制
以下注释和限制适用于 Avro 格式的串流源:
-
启用架构检测后,Avro 架构必须包含在负载中。关闭时,负载应仅包含数据。
-
某些 Avro 数据类型在动态帧中不受支持。在使用 Amazon Glue 控制台的创建表向导中的 Define a schema (定义架构) 页面时,您无法指定这些数据类型。在架构检测期间,Avro 架构中不受支持的类型将转换为受支持的类型,如下所示:
-
EnumType => StringType -
FixedType => BinaryType -
UnionType => StructType
-
-
如果使用控制台中的 Define a schema (定义架构) 页面,则架构的隐含根元素类型为
record。如果你想要一个除record以外的根元素类型,例如array或者map,则不能使用 Define a schema (定义架构) 页面来指定架构。相反,您必须跳过该页并将架构指定为表属性或在 ETL 脚本中指定。-
要在表属性中指定架构,请完成创建表向导,编辑表详细信息,并在 Table properties (表属性) 下添加新的键值对。使用密钥
avroSchema,然后为值输入架构 JSON 对象,如以下屏幕截图所示。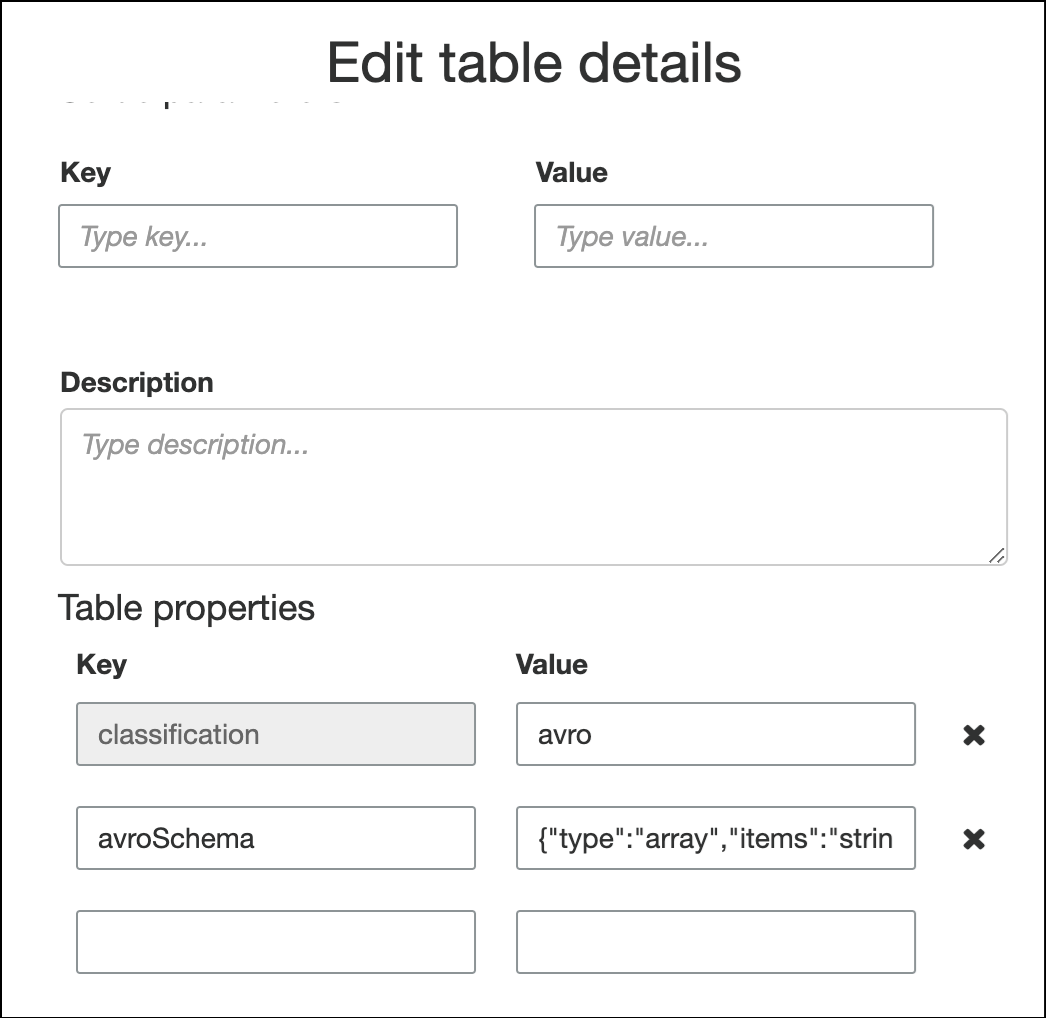
-
要在 ETL 脚本中指定架构,请修改
datasource0任务语句并将avroSchema密钥添加到additional_options参数,如以下 Python 和 Scala 示例所示。
-
将 grok 模式应用于串流源
您可以为日志数据源创建串流 ETL 任务,并使用 Grok 模式将日志转换为结构化数据。然后,ETL 任务会将数据作为结构化数据源进行处理。在为串流源创建数据目录表时,可以指定要应用的 Grok 模式。
有关 Grok 模式和自定义模式字符串值的信息,请参阅 编写 grok 自定义分类器。
将 grok 模式添加到数据目录表(控制台)
-
使用创建表向导,并使用在 为串流源创建数据目录表 中指定的参数创建表。将数据格式指定为 Grok,填写 Grok pattern (Grok 模式) 字段,并可选择在 Custom patterns (optional) (自定义模式(可选)) 下添加自定义模式。
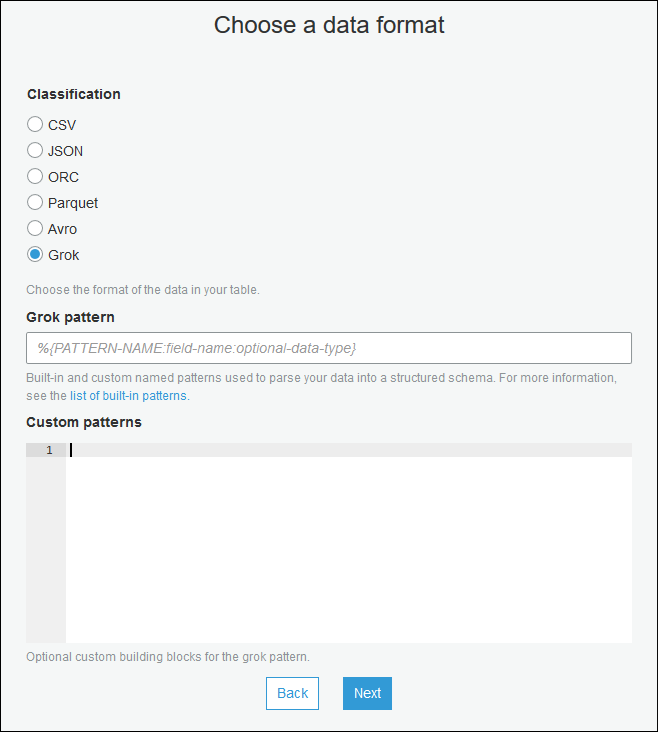
在每个自定义模式后按 Enter。
将 grok 模式添加到数据目录表(Amazon Glue API 或 Amazon CLI)
-
添加
GrokPattern参数,并且可以选择将CustomPatterns参数添加到CreateTableAPI 操作或create_tableCLI 命令。"Parameters": { ... "grokPattern": "string", "grokCustomPatterns": "string", ... },将
grokCustomPatterns表达为字符串,并使用“\n”作为模式之间的分隔符。以下是指定这些参数的示例。
例
"parameters": { ... "grokPattern": "%{USERNAME:username} %{DIGIT:digit:int}", "grokCustomPatterns": "digit \d", ... }
定义串流 ETL 作业的作业属性
在 Amazon Glue 控制台上定义串流 ETL 任务时,请提供以下特定于流的属性。有关其他任务属性的说明,请参阅 定义 Spark 作业的作业属性。
- IAM 角色
-
指定用于对运行任务、访问串流源和访问目标数据存储所用的资源进行授权的 Amazon Identity and Access Management(IAM)角色。
要访问 Amazon Kinesis Data Streams,请将
AmazonKinesisFullAccessAmazon 托管式策略附加到该角色,或附加类似的 IAM policy 来允许更精细的访问。有关示例策略,请参阅使用 IAM 控制对 Amazon Kinesis Data Streams 资源的访问。有关在 Amazon Glue 中运行任务的权限的更多信息,请参阅 适用于 Amazon Glue 的 Identity and Access Management。
- Type
-
选择 Spark streaming (Spark 串流)。
- Amazon Glue 版本
-
Amazon Glue 版本确定可用于任务的 Apache Spark、Python 或 Scala 版本。选择一个选项指定可供作业使用的 Python 或 Scala 版本。Amazon Glue支持 Python 3 的 2.0 版是串流 ETL 任务的默认设置。
- 维护时段
-
指定可以重启流式传输作业的窗口。请参阅Amazon Glue 流式传输的维护时段。
- 作业超时
-
(可选)输入持续时间(以分钟为单位)。默认值是为空。
流式传输作业的超时值必须小于 7 天或 10080 分钟。
如果将该值留空,在您尚未设置维护时段的情况下,该作业将在 7 天后重启。如果您设置了维护时段,该作业将于 7 天后在维护时段内重启。
- 数据来源
-
指定您在 为串流源创建数据目录表 中创建的表。
- 数据目标
-
请执行以下操作之一:
-
选择 Create tables in your data target (在数据目标中创建表) 并指定以下数据目标属性。
- 数据存储
-
选择 Amazon S3 或 JDBC。
- Format
-
选择任意格式。所有项都支持流式处理。
-
选择 Use tables in the data catalog and update your data target (使用数据目录中的表并更新数据目标),然后选择用于 JDBC 数据存储的表。
-
- 输出架构定义
-
请执行以下操作之一:
-
选择 Automatically detect schema of each record (自动检测每条记录的架构) 以启动架构检测。Amazon Glue 可以通过串流数据确定架构。
-
选择 Specify output schema for all records (指定所有记录的输出方案) 以使用 Apply Mapping(应用映射)转换来定义输出架构。
-
- Script
-
(可选)提供您自己的脚本或修改生成的脚本以执行 Apache Spark Structured Streaming 引擎支持的操作。有关可用操作的信息,请参阅串流 DataFrame/数据集的操作
。
串流 ETL 注释和限制
请记住以下注释和限制:
-
自动解压 Amazon Glue 流式传输 ETL 任务仅适用于受支持的压缩类型。另请注意以下几点:
Framed Snappy 是指适用于 Snappy 的帧格式
。 Deflate 在 Glue 版本 3.0 而不是 Glue 版本 2.0 中受支持。
-
使用架构检测时,无法执行串流数据联接。
-
Amazon Glue 流式传输 ETL 任务不支持对具有 Avro 格式的 Amazon Glue 架构注册表使用 Union 数据类型。
-
您的 ETL 脚本可以使用 Amazon Glue 的内置转换和 Apache Spark Structured Streaming 的原生转换。有关更多信息,请参阅 Apache Spark 网站或 Amazon Glue PySpark 转换参考 上的串流 DataFrame/数据集的操作
。 -
Amazon Glue 串流 ETL 任务使用检查点来跟踪已读取的数据。因此,停止并重新启动的任务将从流中停止的位置开始。如果要重新处理数据,您可以删除脚本中引用的检查点文件夹。
-
不支持任务书签。
-
要在作业中使用 Kinesis Data Streams 的增强型扇出功能,请参阅 在 Kinesis 流作业中使用增强型扇出功能。
-
如果您使用在 Amazon Glue 架构注册表中创建的数据目录表,则当新的架构版本可用时,要反映该新架构,您需要执行以下操作:
-
停止与该表关联的任务。
-
更新数据目录表的架构。
-
重新启动与该表关联的任务。
-