本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Amazon OpenSearch 服务的最佳运营实践
本章提供操作亚马逊 OpenSearch 服务域名的最佳实践,并包括适用于许多用例的一般指南。每个工作负载都是独一无二的,具有独特的特征,因此不存在完全适合所有使用案例的万能建议。最重要的最佳实践是通过连续的周期部署、测试和优化域,以找到工作负载的最佳配置、稳定性和成本。
主题
监控和提醒
以下最佳实践适用于监控您的 OpenSearch 服务域。
配置 CloudWatch 警报
OpenSearch 服务向 Amazon CloudWatch 发送绩效指标。定期查看您的集群和实例指标,并根据您的工作负载性能配置推荐的 CloudWatch 警报。
启用日志发布
OpenSearch 该服务在 Amazon Logs 中公开 OpenSearch 错误日志、搜索慢日志、索引慢日志和审核 CloudWatch 日志。搜索慢速日志、索引慢速日志和错误日志有助于排查性能和稳定性问题。审计日志仅在您启用精细访问权限控制后可用,可跟踪用户活动。有关更多信息,请参阅 OpenSearch 文档中的日志
搜索慢速日志和索引慢速日志是了解搜索和索引操作性能以及进行问题排查的重要工具。为所有生产域启用搜索和索引慢速日志传输。您还必须配置日志阈值, CloudWatch 否则将无法捕获日志。
分片策略
分片将您的工作负载分布在 OpenSearch 服务域中的数据节点上。正确配置索引有助于提高域的整体性能。
当你向 OpenSearch 服务发送数据时,你会将该数据发送到索引。索引类似于数据库表,以文档为行,以字段为列。当你创建索引时,你可以告诉你要创建 OpenSearch 多少个主分片。主分片是完整数据集的独立分区。 OpenSearch Service 会自动将您的数据分发到索引中的主分片上。您还可以配置索引的副本。每个副本分片都会完整复制该索引的主分片。
OpenSearch Service 会将每个索引的分片映射到集群中的数据节点。它会确保索引的主分片和副本分片位于不同的数据节点上。第一个副本确保索引中的数据有两份。您应始终至少使用一个副本。更多的副本可提供额外的冗余和读取容量。
OpenSearch 向包含属于索引的分片的所有数据节点发送索引请求。它首先会将索引请求发送到包含主分片的数据节点,然后再发送到包含副本分片的数据节点。协调器节点将搜索请求路由到属于该索引的所有分片的主分片或副本分片。
例如,对于具有五个主分片和每个主分片一个副本的索引,每个索引请求会触及 10 个分片。相比之下,搜索请求会发送到 n 个分片,其中 n 是主分片的数量。对于具有五个主分片和一个副本的索引,每个搜索查询会接触该索引中的五个分片(主分片或副本分片)。
确定分片和数据节点数
使用以下最佳实践来确定域的分片和数据节点数量。
分片大小 – 磁盘上的数据大小直接取决于源数据的大小,并且会随着您为更多数据创建索引而变化。源与索引的比率可能差异很大,从 1:10 到 10:1 或更高,但通常在 1:1.10 左右。您可以使用该比率来预测磁盘上的索引大小。您还可以索引一些数据并检索实际的索引大小,以确定工作负载的比率。获得预测索引大小后,请设置分片数量,以确保每个分片的容量介于 10-30GiB 之间(对于搜索工作负载)或 30-50GiB 之间(对于日志工作负载)。50GiB 应为最大值,请务必为增长做好规划。
分片数量 – 在数据节点中分布分片对域的性能有很大影响。如果索引包含多个分片,请尝试将分片数量设为数据节点数量的倍数。这有助于确保分片在数据节点之间均匀分布,防止出现热节点。例如,假设您有 12 个主分片,则数据节点计数应为 2、3、4、6 或 12。但是,分片数量不如分片大小重要,如果您只有 5GiB 的数据,则仍应使用单个分片。
每个数据节点的分片数 – 一个节点可以容纳的分片总数应与节点的 Java 虚拟机(JVM)堆内存成正比。尽量确保每 GiB 堆内存的分片数量为 25 个或以下。例如,具有 32GiB 堆内存的节点应容纳不超过 800 个分片。尽管分片分布可能因您的工作负载模式而异,但 Elasticsearch 每个节点的分片限制为 1,000 个,2.17 及更高版本的分片限制为 OpenSearch 1.1 到 2.15,4,000 个。 OpenSearch该 cat/allocation
分片 CPU 比率 – 当索引或搜索请求中涉及分片时,它会使用 vCPU 来处理请求。建议以每个分片 1.5 个 vCPU 为初始扩缩点。如果您的实例类型具有 8 个 vCPU,则数据节点数量的设置应确保每个节点的分片数量不超过 6 个。请注意,这是一个近似值。请务必测试您的工作负载并相应地扩展集群。
有关存储卷、分片大小和实例类型的建议,请参阅以下资源:
避免存储偏斜
当集群中有一个或多个节点拥有一个或多个索引的存储数量比例高于其他节点时,会发生存储偏斜。存储偏斜的迹象包括 CPU 利用率不均衡、间歇性和不均匀的延迟以及跨数据节点的队列不均衡。要确定是否存在偏斜问题,请参阅以下问题排查部分:
稳定性
以下最佳实践适用于维护稳定和健康的 OpenSearch 服务域。
随时了解最新动态 OpenSearch
服务软件更新
OpenSearch Servic e 会定期发布软件更新,以增加功能或以其他方式改进您的域名。更新不会更改 OpenSearch 或 Elasticsearch 引擎的版本。我们建议您安排定期运行 DescribeDomainAPI 操作,如果UpdateStatus是,则启动服务软件更新ELIGIBLE。如果您未在一定时间内(通常为两周)更新域名,S OpenSearch ervice 会自动执行更新。
OpenSearch 版本升级
OpenSearch 该服务会定期增加对社区维护版本的 OpenSearch支持。当最新 OpenSearch 版本可用时,请务必升级到最新版本。
OpenSearch 服务同时升级两个 OpenSearch 仪表板 OpenSearch 和控制面板(如果您的域名运行的是传统引擎,则可以同时升级 Elasticsearch 和 Kibana)。如果集群具有专用主节点,则无需停机即可完成升级。否则,群集在选择主节点时可能会在升级后的几秒钟内没有响应。 OpenSearch 在部分或全部升级期间,仪表板可能不可用。
升级域的方式有两种:
无论使用哪种升级方式,我们都建议您建立一个仅用于开发和测试的域,并将其升级到新版本,然后再升级生产域。在创建测试域时,对于部署类型,选择 Development and testing(开发和测试)。务必在域升级后立即将所有客户端升级到兼容版本。
提高快照性能
为防止快照在处理过程中卡住,专用主节点的实例类型应与分片计数相符。有关更多信息,请参阅 为专用主节点选择实例类型。此外,每个节点每 GiB Java 堆内存不应超过 25 个分片(推荐)。有关更多信息,请参阅 选择分片数量。
启用专用主节点
专用主节点可提高集群稳定性。专用主节点会执行集群管理任务,但不保留索引数据也不响应客户端请求。通过下载集群管理任务,可提高域的稳定性,并能够在不停机的情况下实施某些配置更改。
启用并使用三个专用主节点,以跨三个可用区优化域稳定性。使用待机模式Multi-AZ 进行部署会为您配置三个专用的主节点。有关实例类型建议,请参阅为专用主节点选择实例类型。
跨多个可用区进行部署
为在服务中断时防止数据丢失并尽量减少集群停机时间,您可以在同一 Amazon Web Services 区域中的两个或三个可用区之间分布节点。最佳实践是使用 “备用” Multi-AZ 进行部署,它配置三个可用区,其中两个可用区处于活动状态,一个可用区充当备用区域,每个索引使用两个副本分片。此配置允许 S OpenSearch ervice 将副本分片分发到与其对应的主分片不同的可用区。可用区之间的集群通信不会产生跨可用区数据传输费用。
可用区是每个 区域内的隔离位置。使用双可用区配置时,失去一个可用区意味着您将损失一半的域容量。使用三个可用区可进一步减少失去单个可用区的影响。
控制摄取流量和缓冲
我们建议使用 _bulk_bulk 请求要比发送 5000 个包含单个文档的请求更高效。
为了确保最佳操作稳定性,有时需要限制甚至暂停索引请求的上游流。限制索引请求的速率是处理意外或偶尔出现的请求峰值的重要机制,否则这些峰值可能会导致集群不堪重负。考虑在上游架构中构建流量控制机制。
下图显示了日志提取架构的多个组件选项。配置聚合层,以留出足够的空间来缓冲传入的数据,应对突发的流量高峰以及满足短暂的域维护需求。
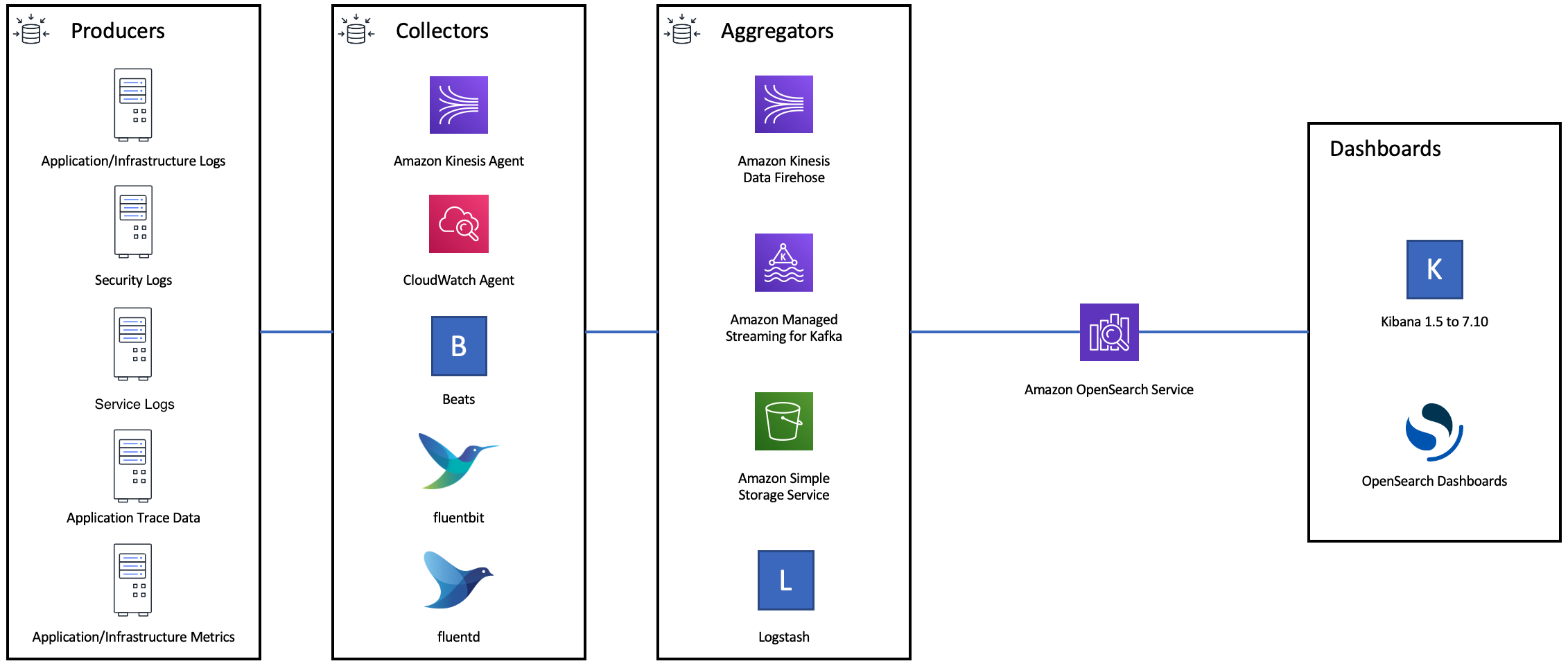
为搜索工作负载创建映射
对于搜索工作负载,创建映射dynamic 设置为 strict,可防止意外添加新字段。
PUT my-index { "mappings": { "dynamic": "strict", "properties": { "title": { "type" : "text" }, "author": { "type" : "integer" }, "year": { "type" : "text" } } } }
使用索引模板
您可以使用索引模板
以下设置对于在模板中配置非常有用:
-
主分片和副本分片的数量
-
刷新间隔时间(刷新频率以及使最近对索引的更改可供搜索的频率)
-
动态映射控制
-
显式字段映射
以下示例模板包含了所有这些设置:
{ "index_patterns":[ "index-*" ], "order": 0, "settings": { "index": { "number_of_shards": 3, "number_of_replicas": 1, "refresh_interval": "60s" } }, "mappings": { "dynamic": false, "properties": { "field_name1": { "type": "keyword" } } } }
即使设置和映射很少更改,在其中集中定义设置和映射 OpenSearch 也比更新多个上游客户端更易于管理。
使用索引状态管理来管理索引
如果您正在管理日志或时间序列数据,我们建议使用索引状态管理(ISM)。ISM 允许您自动执行定期性的索引生命周期管理任务。借助 ISM,您可以创建触发索引别名滚动、拍摄索引快照、在存储层之间移动索引以及删除旧索引的策略。您甚至可以将 ISM 滚动
首先,您需要设置一个 ISM 策略。有关示例,请查看 示例策略。然后,将该策略附加到一个或多个索引。如果您在策略中包含 ISM 模板字段,S OpenSearch ervice 会自动将该策略应用于与指定模式匹配的任何索引。
删除未使用的索引
定期检查集群中的索引并确定任何未使用的索引。拍摄这些索引的快照,以便将它们存储在 S3 中,然后将其删除。移除未使用的索引可减少分片数量,从而能在节点之间实现更均衡的存储分布和资源利用率。即使索引处于空闲状态,它们在内部索引维护活动期间也会消耗一些资源。
您可以使用 ISM 自动拍摄快照并在一段时间后删除索引,而不是手动删除未使用的索引。
使用多个域以实现高可用性
要跨多个区域实现超过 99.9% 正常率
在设计上游和下游应用程序架构注意失效转移的需要。务必要测试失效转移流程以及其他灾难恢复流程。
性能
以下最佳实践有利于调整域以优化性能。
优化批量请求大小和压缩
批量大小取决于您的数据、分析和集群配置,但建议从每个批量请求 3-5MiB 开始。
使用 gzip 压缩来减少请求和响应的有效负载大小,从而发送请求和接收来自您的 OpenSearch 域的响应。您可以在 OpenSearch Python 客户端中使用 gzip 压缩,也可以通过在客户端添加以下标头来使用:
-
'Accept-Encoding': 'gzip' -
'Content-Encoding': 'gzip'
要优化批量请求大小,请先将批量请求大小设为 3MiB。然后,慢慢增加请求大小,直到索引性能停止改善。
注意
要在运行 Elasticsearch 版本 6.x 的域上启用 gzip 压缩,您必须在集群级别设置 http_compression.enabled。在 Elasticsearch 7.x 版本和的所有版本中,默认情况下,此设置均为真。 OpenSearch
降低批量请求响应的大小
要减小 OpenSearch 响应的大小,请使用filter_path参数排除不必要的字段。确保不要筛选掉识别或重试失败请求所必需的任何字段。有关更多信息以及示例,请参阅 减小响应大小。
优化刷新间隔时间
OpenSearch 索引最终具有读取一致性。刷新操作会使对索引执行的所有更新都可供搜索。默认刷新间隔为一秒,这意味着 OpenSearch 在向索引写入时每秒执行一次刷新。
刷新索引的频率越低(刷新间隔时间越长),索引的整体性能越好。增加刷新间隔时间的缺点是,从索引更新到新数据可供搜索之间的延迟会更长。请将刷新间隔时间设置为可以容忍的最高值,从而提高整体性能。
我们建议将所有索引的 refresh_interval 参数设置为 30 秒或更长时间。
启用 Auto-Tune
Auto-Tune使用 OpenSearch 集群中的性能和使用率指标来建议节点上队列大小、缓存大小和 Java 虚拟机 (JVM) 设置的更改。这些可选更改可提高集群速度和稳定性。您可以随时恢复到默认的 OpenSearch 服务设置。 Auto-Tune 除非您明确将其禁用,否则在新域上默认处于启用状态。
我们建议您在所有域名 Auto-Tune 上启用,并设置定期维护窗口或定期查看其建议。
安全性
以下最佳实践有利于域的安全保护。
启用精细访问控制
Fine-grained 访问控制允许您控制谁可以访问 OpenSearch 服务域中的某些数据。与一般访问控制相比,精细访问控制可为每个集群、索引、文档和字段提供自己指定的访问策略。访问条件可基于多个因素,包括请求访问权限的人的角色以及他们计划对数据执行的操作。例如,您可以授予一个用户写入索引的权限,而授予另一个用户只读取索引数据而不进行任何更改的权限。
Fine-grained 访问控制允许具有不同访问要求的数据存在于同一个存储空间中,而不会遇到安全或合规性问题。
我们建议为您的域启用精细访问控制。
在 VPC 中部署域
将 OpenSearch 服务域置于虚拟私有云 (VPC) 中有助于实现 OpenSearch 服务与 VPC 内其他服务之间的安全通信,无需互联网网关、NAT 设备或 VPN 连接。所有流量都安全地保存在 Amazon 云中。由于进行了逻辑隔离,与使用公共端点的域相比,驻留在 VPC 中的域有一层额外的安全性。
我们建议您在 VPC 中创建您的域。
应用限制性访问策略
即使您的域部署在 VPC 中,实施分层安全保护也是最佳做法。务必要对当前的访问策略进行配置检查。
对您的域应用基于资源的限制性访问策略,并在授予对配置 API 和 API 操作的访问权限时遵循最低权限原则。 OpenSearch 原则上,访问策略中应避免使用匿名用户主体 "Principal": {"AWS": "*" }。
但在某些情况下,使用开放访问策略是可以接受的,例如启用精细访问控制时。开放访问策略允许您在难以或无法为请求签名时访问域,例如从某些客户端和工具访问。
启用静态加密
OpenSearch 服务域提供静态数据加密,有助于防止未经授权访问您的数据。静态加密使用 Amazon Key Management Service (Amazon KMS) 来存储和管理您的加密密钥,使用 256 位密钥的高级加密标准算法 (AES-256) 来执行加密。
如果您的域存储了敏感数据,则应启用静态数据加密。
启用节点到节点加密
Node-to-node 除了 OpenSearch 服务中的默认安全功能外,加密还提供了额外的安全层。它为其中配置的节点之间的所有通信实现了传输层安全 (TLS)。 OpenSearch Node-to-node 加密,通过 HTTPS 发送到您的 OpenSearch 服务域的任何数据在传输过程中均保持加密状态,同时在节点之间进行分发和复制。
如果您的域存储了敏感数据,则应启用节点到节点加密。
使用监视器 Amazon Security Hub CSPM
使用监控您对 OpenSearch 服务的使用情况,因为它与安全最佳实践有关Amazon Security Hub CSPM。Security Hub CSPM 使用安全控件来评估资源配置和安全标准,以帮助您遵守各种合规框架。有关使用 Security Hub CSPM 评估 OpenSearch 服务资源的更多信息,请参阅《Amazon Security Hub 用户指南》中的Amazon OpenSearch Service 控件。
成本优化
以下最佳实践适用于优化和节省 OpenSearch 服务成本。
使用最新一代实例类型
OpenSearch 服务始终采用新的 Amazon EC2 实例类型,以更低的成本提供更好的性能。我们建议始终使用最新一代的实例。
不要将 T2 或者 t3.small 实例用于生产域,因为在持续接受重载时,这些实例会变得不稳定。r6g.large 实例适用于小型生产工作负载(既作为数据节点又作为专用主节点)。
使用最新的 Amazon EBS gp3 卷
OpenSearch 数据节点需要低延迟和高吞吐量存储才能提供快速的索引和查询。通过使用 Amazon EBS gp3 卷,您可以获得更高的基准性能(IOPS 和吞吐量),而成本却比之前提供的 Amazon EBS gp2 卷类型低 9.6%。您可以使用 gp3 预置额外的 IOPS 和吞吐量,不受卷大小的影响。这些卷也比上一代卷更稳定,因为它们不使用突增额度。gp3 卷类型还使 gp2 卷类型的每个数据节点的卷大小限制增加了一倍。有了更大的卷,您可以通过增加每个数据节点的存储量来降低被动数据的费用。
时间序列日志数据的使用 UltraWarm 和冷存储
如果您使用 OpenSearch 日志分析,请将数据移至 UltraWarm 或冷存储以降低成本。使用索引状态管理(ISM)在存储层之间迁移数据并管理数据留存。
UltraWarm为在 S OpenSearch ervice 中存储大量只读数据提供了一种经济实惠的方法。 UltraWarm 使用 Amazon S3 进行存储,这意味着数据是不可变的,只需要一个副本。您只需支付相当于索引中主分片大小的存储费用。 UltraWarm 查询的延迟会随着为查询提供服务所需的 S3 数据量而增加。在节点上缓存数据后,对索引的查询的执行与对热 UltraWarm 索引的查询类似。
冷存储也由 S3 提供支持。当你需要查询冷数据时,你可以有选择地将其附加到现有 UltraWarm 节点。冷数据产生的托管存储成本与相同 UltraWarm,但冷存储中的对象不会消耗 UltraWarm 节点资源。因此,冷存储提供了大量的存储容量,而不会影响 UltraWarm 节点大小或数量。
UltraWarm 当您有大约 2.5 TiB 的数据需要从热存储中迁移时,就会变得经济高效。监控您的填充率,并计划在达到该数据量 UltraWarm之前将索引移到该位置。
检查有关预留实例的建议
在确定好性能和计算消耗基线后考虑购买预留实例(RI)。无预付的 1 年期预留实例的折扣从大约 30% 起,所有需要预付的 3 年期预留实例折扣最大可达 50%。
观察稳定运行至少 14 天后,请查看《Amazon Cost Management 用户指南》中的访问预留建议。Amazon S OpenSearch ervic e 标题显示了具体的 RI 购买建议和预计节省的费用。