本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
指标和验证
本指南介绍了可用于衡量机器学习模型性能的指标和验证技术。Amazon SageMaker Autopilot 会生成衡量候选机器学习模型预测质量的指标。为候选人计算的指标是使用一系列MetricDatum类型指定的。
Autopilot 指标
以下列表包含当前可用于衡量 Autopilot 中模型性能的指标名称。
注意
Autopilot 支持样本权重。要了解有关样本权重和可用目标指标的更多信息,请参阅 Autopilot 加权指标。
可用指标如下所示。
Accuracy-
正确分类的项目数,相比所分类项目总数(正确和错误)的比率。它用于二元分类和多元分类。准确性衡量预测类值与实际值的接近程度。准确性指标的值在零 (0) 和壹 (1) 之间变化。值为 1 表示完全准确,0 表示完全不准确。
AUC-
曲线下面积 (AUC) 指标通过返回概率(例如逻辑回归)的算法,比较和评估二元分类。为了将概率映射到分类中,需要将这些概率与阈值进行比较。
相关的曲线是接收者操作特征曲线。该曲线将预测(或查全率)的真阳性率 (TPR) 与假阳性率 (FPR) 作为阈值的函数绘制,在曲线之上的预测视为阳性。提高阈值会减少假阳性,但会增加假阴性。
AUC 是接收者操作特征曲线下方的面积。因此,AUC 提供了在所有可能的分类阈值中,模型性能的综合度量。AUC 分数介于 0 和 1 之间。分数为 1 表示完美的准确性,分数为一半 (0.5) 表示预测结果并不比随机分类器更好。
BalancedAccuracy-
BalancedAccuracy是用于衡量准确预测占所有预测比例的指标。该比率是在根据阳性 (P) 和阴性 (N) 值总数,对真阳性 (TP) 和真阴性 (TN) 进行标准化后计算得出的。它用于二进制分类和多类分类,其定义如下:0.5* ((TP/P) + () (TN/N)),值范围为 0 到 1。BalancedAccuracy在不平衡的数据集中,如果正面或负面的数量相差很大,例如只有 1% 的电子邮件是垃圾邮件,则可以更好地衡量准确性。 F1-
F1分数是查准率和查全率的调和平均值,定义如下:F1 = 2 *(查准率 * 查全率)/(查准率 + 查全率)。它用于二元分类,分为传统上称为阳性和阴性的类。预测在与实际(正确)类匹配时为 true,不匹配时为 false。查准率是指真阳性预测与所有阳性预测的比率,它包括数据集中的假阳性。在预测阳性类时,查准率衡量预测的质量。
查全率(或灵敏度)是真阳性预测与所有实际阳性实例的比率。查全率衡量模型预测数据集中实际类成员的全面程度。
F1 分数介于 0 和 1 之间。分数为 1 表示具有最佳性能,0 表示性能最差。
F1macro-
F1macro分数将 F1 评分应用于多元分类问题。为此,它计算查准率和查全率,然后用它们的调和平均值来计算每个类的 F1 分数。最后,F1macro对各个分数取平均值以获得F1macro分数。F1macro分数介于 0 和 1 之间。分数为 1 表示具有最佳性能,0 表示性能最差。 InferenceLatency-
推理延迟是指从发出模型预测请求,到从部署模型的实时端点收到模型预测请求之间的大致时间长度。该指标以秒为单位进行测量,仅在组合模式下可用。
LogLoss-
对数损失,也称为交叉熵损失,是用于评估概率输出质量的指标,而不是输出本身。它可用于二元分类和多元分类,也用于神经网络。它也是逻辑回归的成本函数。对数损失是一个重要指标,指示模型何时有很高的概率做出了错误预测。值范围为 0 到无穷大。值为 0 表示可以完美预测数据的模型。
MAE-
平均绝对误差 (MAE) 用于衡量在所有值上,将预测值与实际值的差值取平均数时有多大的差异。MAE 通常用于回归分析以了解模型预测误差。如果使用线性回归,则 MAE 表示从预测线到实际值的平均距离。MAE 定义为绝对误差之和除以观察数据的数量。值的范围从 0 到无穷大,数字越小表示模型对数据的拟合效果越好。
MSE-
均方误差 (MSE) 是预测值和实际值之间的平方差的平均值。它用于回归。MSE 值始终为正值。模型在预测实际值方面的表现越好,MSE 值就越小。
Precision-
查准率衡量算法预测的真阳性 (TP) 占所识别的全部阳性的比例。它的定义如下:查准率 = TP/(TP+FP),值范围从零 (0) 到壹 (1),用于二元分类。当假阳性的成本很高时,查准率是一个重要指标。例如,如果飞机安全系统错误地认为可以安全飞行,则假阳性的成本非常高。假阳性 (FP) 反映的是预测为阳性,而在数据中实际为阴性的情况。
PrecisionMacro-
查准率宏计算多元分类问题的查准率。它通过计算每个类的查准率并对分数取平均值来获得多个类的查准率。
PrecisionMacro分数范围从零 (0) 到壹 (1)。该分数在多个类中取平均值,分数越高反映了模型越能从其识别的所有阳性中预测真阳性 (TP)。 R2-
R2,也称为决定系数,在回归中用于量化模型在多大程度上可以解释因变量的方差。值范围从壹 (1) 到负壹 (-1)。数字越大,说明变异率的解释比例越高。接近零 (0) 的
R2值表示模型几乎无法解释因变量。负值表示拟合不佳,常量函数的性能优于模型。对于线性回归,这是一条水平线。 Recall-
查全率可以衡量算法正确预测数据集中所有真阳性 (TP) 的能力如何。真阳性是指预测为阳性,而实际也是数据中阳性值的情况。查全率定义如下:查全率 = TP/(TP+FN),值范围从 0 到 1。分数越高,反映模型预测数据中真阳性 (TP) 的能力越强。它用于二元分类。
在癌症检测时,查全率很重要,因为它被用来找出所有真阳性。假阴性(FN)反映的是预测阴性,而在数据中实际为阳性的情况。仅衡量查全率通常是不够的,因为只要将每个输出都预测为真阳性,就可以得到完美的查全率分数。
RecallMacro-
RecallMacro计算每个类的查全率并取平均值,以获取多个类的查全率,以此来计算多元分类问题的查全率。RecallMacro分数介于 0 和 1 之间。分数越高反映模型预测数据集中真阳性 (TP) 的能力就越好,而真阳性反映的是预测为阳性,而实际也是数据中阳性值的情况。仅衡量查全率通常是不够的,因为只要将每个输出都预测为真阳性,就可以得到完美的查全率分数。 RMSE-
均方根误差 (RMSE) 衡量预测值与实际值之间平方差的平方根,并对所有值取平均值。它用于回归分析以了解模型预测误差。这是一个重要的指标,用于指示是否存在较大的模型误差和异常值。值的范围从零 (0) 到无穷大,数字越小表示模型对数据的拟合效果越好。RMSE 依赖于规模,不应用于比较不同大小的数据集。
为候选模型自动计算的指标取决于要解决的问题的类型。
有关 Autopilot 支持的可用指标列表,请参阅 A mazon SageMaker API 参考文档。
Autopilot 加权指标
注意
Autopilot 仅在组合模式下支持所有可用指标的样本权重,但 Balanced Accuracy 和 InferenceLatency 除外。对于不需要样本权重的不平衡数据集,BalanceAccuracy 有自己的加权架构。InferenceLatency 不支持样本权重。在训练和评估模型时,目标 Balanced Accuracy 和 InferenceLatency 指标都会忽略任何现有的样本权重。
用户可以向其数据添加样本权重列,以确保向用于训练机器学习模型的每个观察数据赋予权重,该权重对应于每个观察数据对模型的感知重要性。在数据集中的观察数据重要性程度各不相同,或者数据集中一个类别的样本数量与其他类别的样本数量相比不成比例的场景中,权重特别有用。根据每个观察结果的重要性向其分配权重,或者向少数类赋予更高的权重,有助于提升模型的整体性能,或者确保模型不会偏向多数类。
有关在 Studio Classic 用户界面中创建实验时如何传递样本权重的信息,请参阅使用 Studio Classic 创建 Autopilot 实验中的步骤 7。
有关在使用 API 创建 Autopilot 实验时如何以编程方式传递样本权重的信息,请参阅以编程方式创建 Autopilot 实验中的如何向 AutoML 作业添加样本权重。
Cross-validation 在自动驾驶仪中
Cross-validation 用于减少模型选择中的过度拟合和偏差。如果验证数据集抽取自同一个数据集,交叉验证还有助于评测模型预测验证数据集中未用于训练的能力。在对训练实例数量有限的数据集进行训练时,此方法尤其重要。
Autopilot 使用交叉验证在超参数优化 (HPO) 和组合训练模式下构建模型。Autopilot 交叉验证过程的第一步是将数据拆分为 k 个子集。
K-fold 分裂
K-fold spliting 是一种将输入训练数据集分成多个训练和验证数据集的方法。数据集被拆分为 k 个大小相等的子样本,称为子集。然后在 k-1 个子集上对模型进行训练,并根据剩余的第 k 个子集进行测试,该子集作为验证数据集。此过程使用不同的数据集重复 k 次以进行验证。
下图描绘了 k = 4 个子集时的 k 折拆分。每个子集都表示为一行。深色调的方框代表训练中使用的数据部分。其余的浅色方框表示验证数据集。

Autopilot 为超参数优化 (HPO) 模式和组合模式使用 k 折交叉验证。
你可以像使用任何其他自动驾驶或 SageMaker 人工智能模型一样部署使用交叉验证构建的自动驾驶模型。
HPO 模式
K-fold 交叉验证使用 k 折拆分方法进行交叉验证。在 HPO 模式下,Autopilot 会自动为不超过 50000 个训练实例的小型数据集实施 k 折交叉验证。在小型数据集上训练时,执行交叉验证尤其重要,因为它可以防止过度拟合和选择偏差。
HPO 模式对用于数据集建模的每个候选算法使用 k 值 5。在不同的拆分上训练多个模型,模型分开存储。训练完成后,将对每个模型的验证指标取平均值,以生成单个估计指标。最后,Autopilot 将试验中具有最佳验证指标的模型合并成一个组合模型。Autopilot 使用此组合模型进行预测。
Autopilot 训练的模型的验证指标提供作为模型排行榜中的目标指标。除非您另有指定,否则 Autopilot 会对处理的每种问题类型使用默认验证指标。有关 Autopilot 使用的所有指标的列表,请参阅 Autopilot 指标。
例如,波士顿房屋数据集
Cross-validation 可以将训练时间平均增加 20%。在使用复杂的数据集时,训练时间也可能显著增加。
注意
在 HPO 模式下,你可以在/aws/sagemaker/TrainingJobs CloudWatch 日志中看到各个方面的训练和验证指标。有关 CloudWatch 日志的更多信息,请参阅CloudWatch 亚马逊 A SageMaker I 的日志。
组合模式
注意
Autopilot 支持组合模式下的样本权重。有关支持样本权重的可用指标列表,请参阅 Autopilot 指标。
在组合模式下,无论数据集大小如何,都会执行交叉验证。客户可以提供自己的验证数据集并自定义数据拆分比率,也可以让 Autopilot 自动按照 80%-20% 的拆分比率来拆分数据集。然后,将训练数据拆分为 k-folds 以进行交叉验证,其中的k值由引擎确定。 AutoGluon 一个组合由多个机器学习模型组成,其中每个模型被称为基础模型。单个基础模型在 (k-1) 个子集上进行训练,并对剩余子集进行子集外预测。此过程对所有 k 个子集重复,将子集外 (OOF) 预测连接起来形成一组预测。组合中的所有基础模型都遵循相同的流程来生成 OOF 预测。
下图描绘了 k = 4 个子集时的 k 折验证。每个子集都表示为一行。深色调的方框代表训练中使用的数据部分。其余的浅色方框表示验证数据集。
在图像的上半部的每个子集中,第一个基础模型在训练数据集上训练后,对验证数据集进行预测。在随后的每个子集中,数据集更换角色。之前用于训练的数据集现在用于验证,以此类推。在 k 个子集上完成训练后,将所有预测串联在一起形成一组预测,称为子集外 (OOF) 预测。对每个 n 基础模型重复此过程。
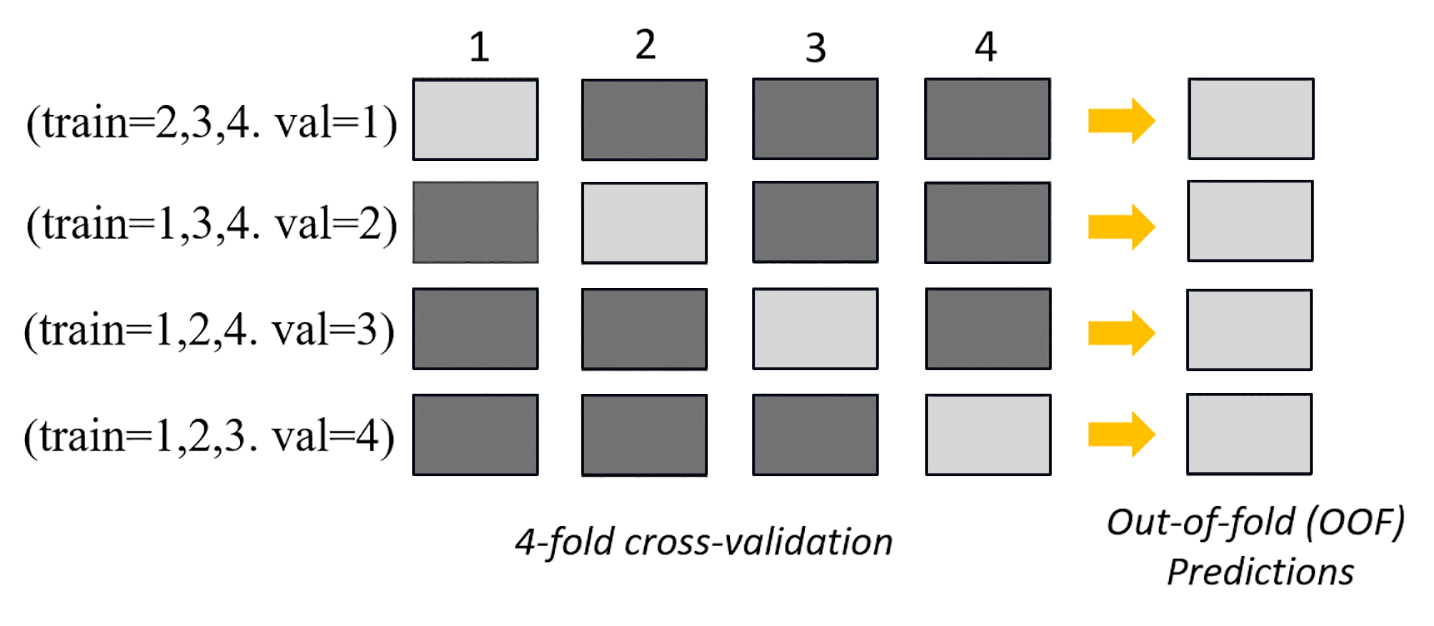
然后,将每个基础模型的 OOF 预测用作特征来训练堆叠模型。堆叠模型学习每个基础模型的重要性权重。这些权重用于合并 OOF 预测以形成最终预测。验证数据集的性能决定了哪个基础模型或堆叠模型最合适,然后返回此模型作为最终模型。
在组合模式下,您可以提供自己的验证数据集,也可以让 Autopilot 自动拆分输入数据集,其中 80% 为训练数据集,20% 为验证数据集。然后,将训练数据拆分为 k 个子集以进行交叉验证,并为每个子集生成 OOF 预测和基础模型。
这些 OOF 预测用作特征来训练堆叠模型,堆叠模型同时会学习每个基础模型的权重。这些权重用于合并 OOF 预测以形成最终预测。每个子集的验证数据集用于所有基础模型和堆叠模型的超参数调整。验证数据集的性能决定了哪个基础模型或堆叠模型是最合适的模型,然后返回此模型作为最终模型。