本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
IAM 访问管理
以下各节描述了亚马逊 SageMaker 管道的 Amazon Identity and Access Management (IAM) 要求。有关如何实施这些权限的示例,请参阅先决条件。
管道角色权限
您的管道需要一个 IAM 管道执行角色,该角色将在您创建管道时传递给管道。 用于创建管道的 SageMaker AI 实例的角色必须具有指定管道执行角色的iam:PassRole权限的策略。这是因为实例需要权限才能将您的管道执行角色传递给 Pipelines 服务,以用于创建和运行管道。有关 IAM 角色的更多信息,请参阅 IAM 角色。
您的管道执行角色需要以下权限:
-
您可以为管道中的任何 SageMaker AI 任务步骤使用唯一角色或自定义角色(而不是默认使用的管道执行角色)。请确保您的管道执行角色已添加具有指定每个角色的
iam:PassRole权限的策略。 -
管道中每种作业类型的
Create和Describe权限。 -
Amazon S3 使用
JsonGet函数的权限。您可以使用基于资源的策略和基于身份的策略来控制对 Amazon S3 资源的访问。基于资源的策略会应用到 Amazon S3 存储桶,并授予 Pipelines 对存储桶的访问权限。基于身份的策略使您的管道能够从您的账户调用 Amazon S3。有关基于资源的策略和基于身份的策略的更多信息,请参阅策略和基于资源的Identity-based策略。{ "Action": [ "s3:GetObject" ], "Resource": "arn:aws:s3:::<your-bucket-name>/*", "Effect": "Allow" }
管道步骤权限
管道包括运行 A SageMaker I 作业的步骤。为了让管道步骤运行这些作业,需要在您的账户中设置一个 IAM 角色,以提供对所需资源的访问权限。此角色由您的管道传递给 SageMaker AI 服务主体。有关 IAM 角色的更多信息,请参阅 IAM 角色。
默认情况下,每个步骤都扮演管道执行角色。您可以选择将不同的角色传递给管道中的任何步骤。这样可以确保每个步骤中的代码不会影响其他步骤中使用的资源,除非管道定义中指定的两个步骤之间存在直接关系。您可以在为步骤定义处理器或估算器时传递这些角色。有关如何在这些定义中包含这些角色的示例,请参阅 SageMaker AI Python SDK 文档
使用 Amazon S3 存储桶进行 CORS 配置
为确保映像以可预测的方式从 Amazon S3 存储桶导入到管道中,必须向从中导入映像的 Amazon S3 存储桶添加 CORS 配置。此部分说明了如何为 Amazon S3 存储桶设置所需的 CORS 配置。Pipelines 所需的 XML CORSConfiguration 与输入映像数据的 CORS 要求中的不同,不过您仍可借助其中的信息,进一步了解 Amazon S3 存储桶的 CORS 要求。
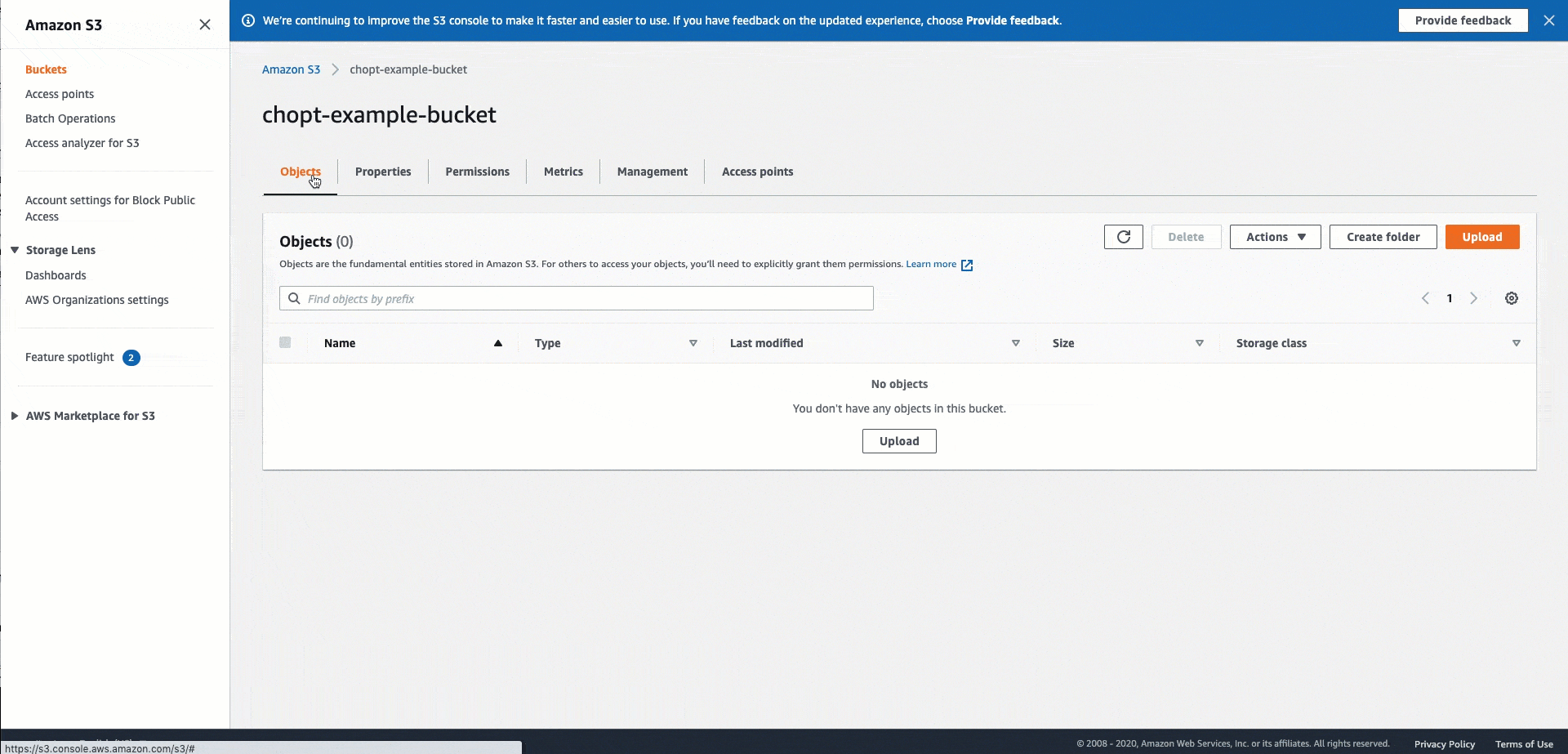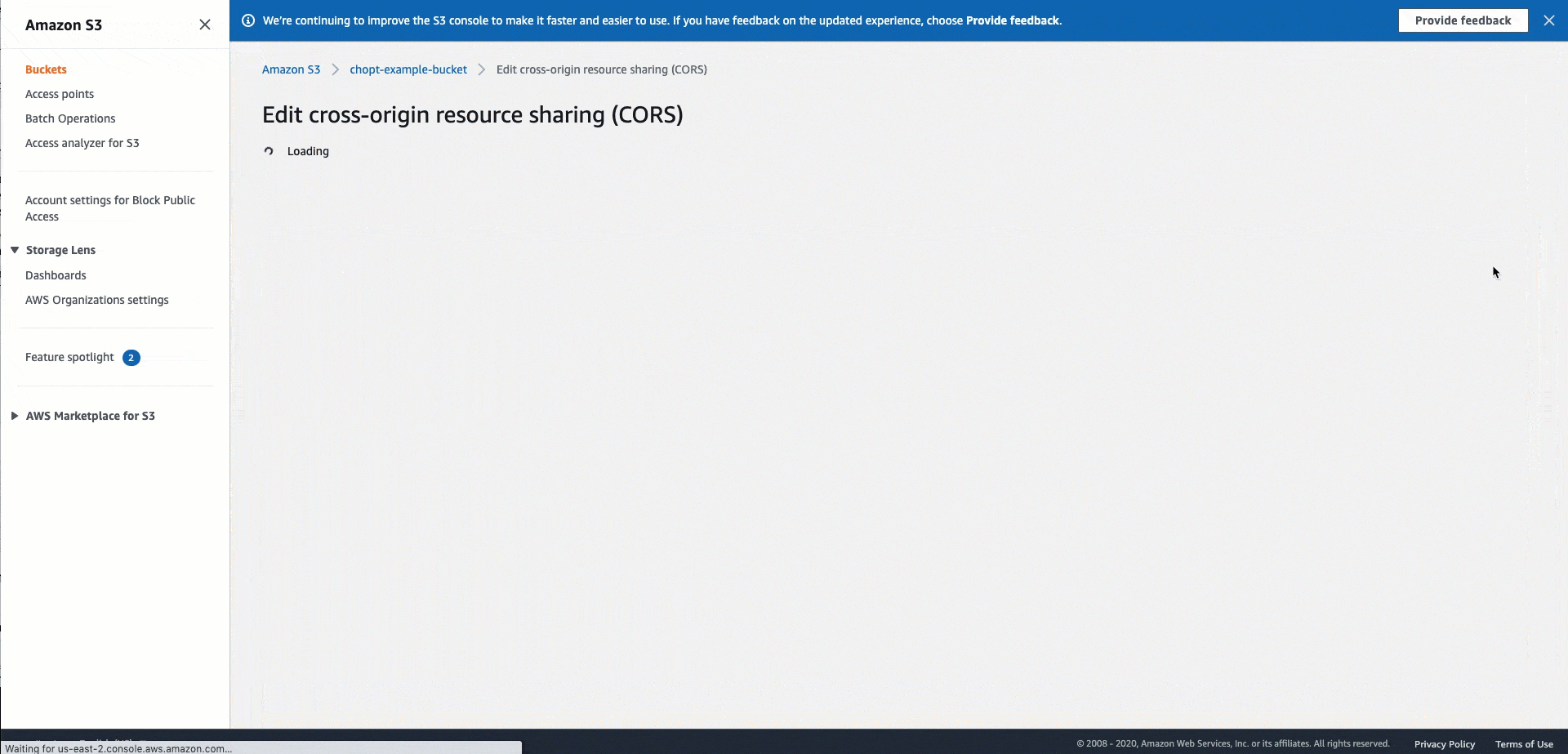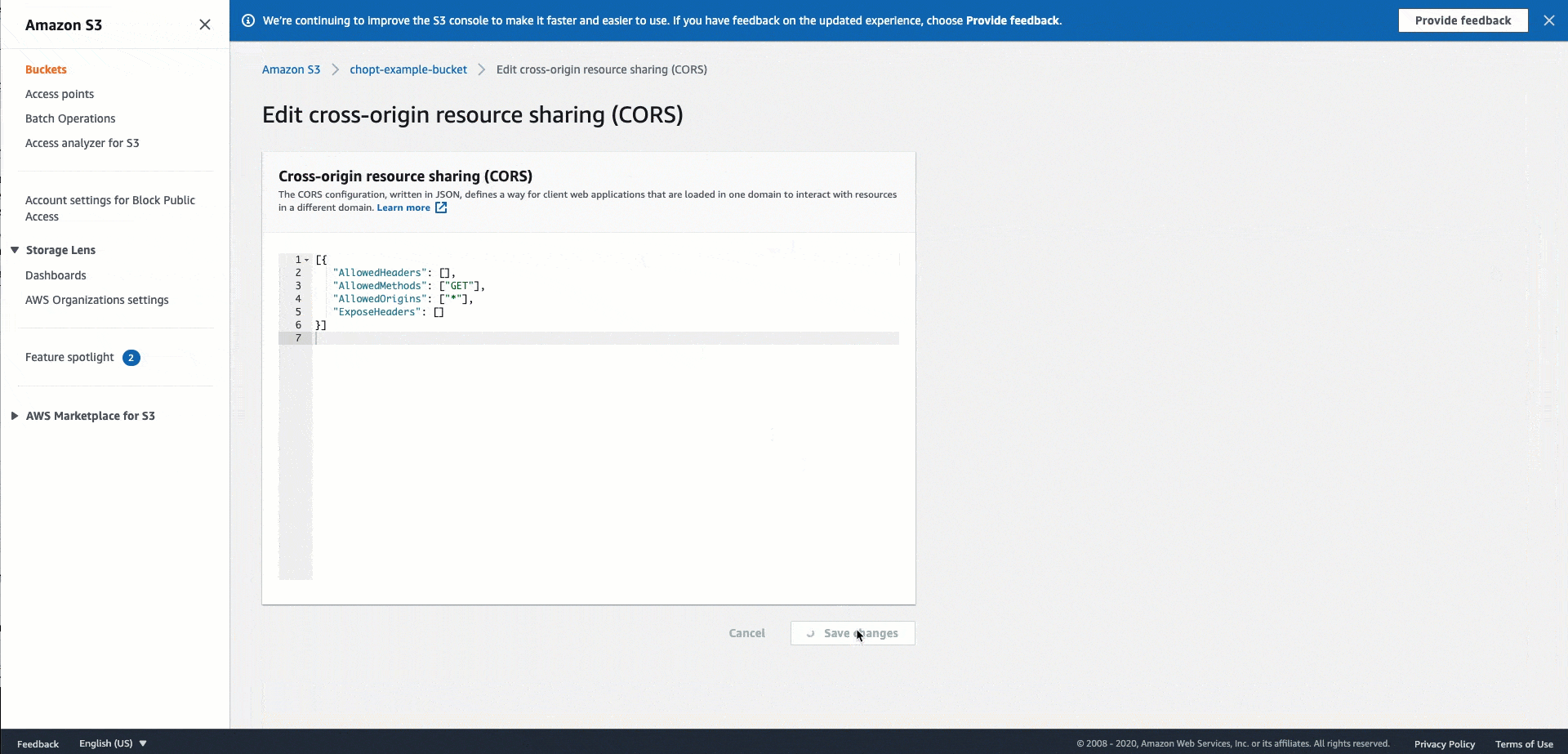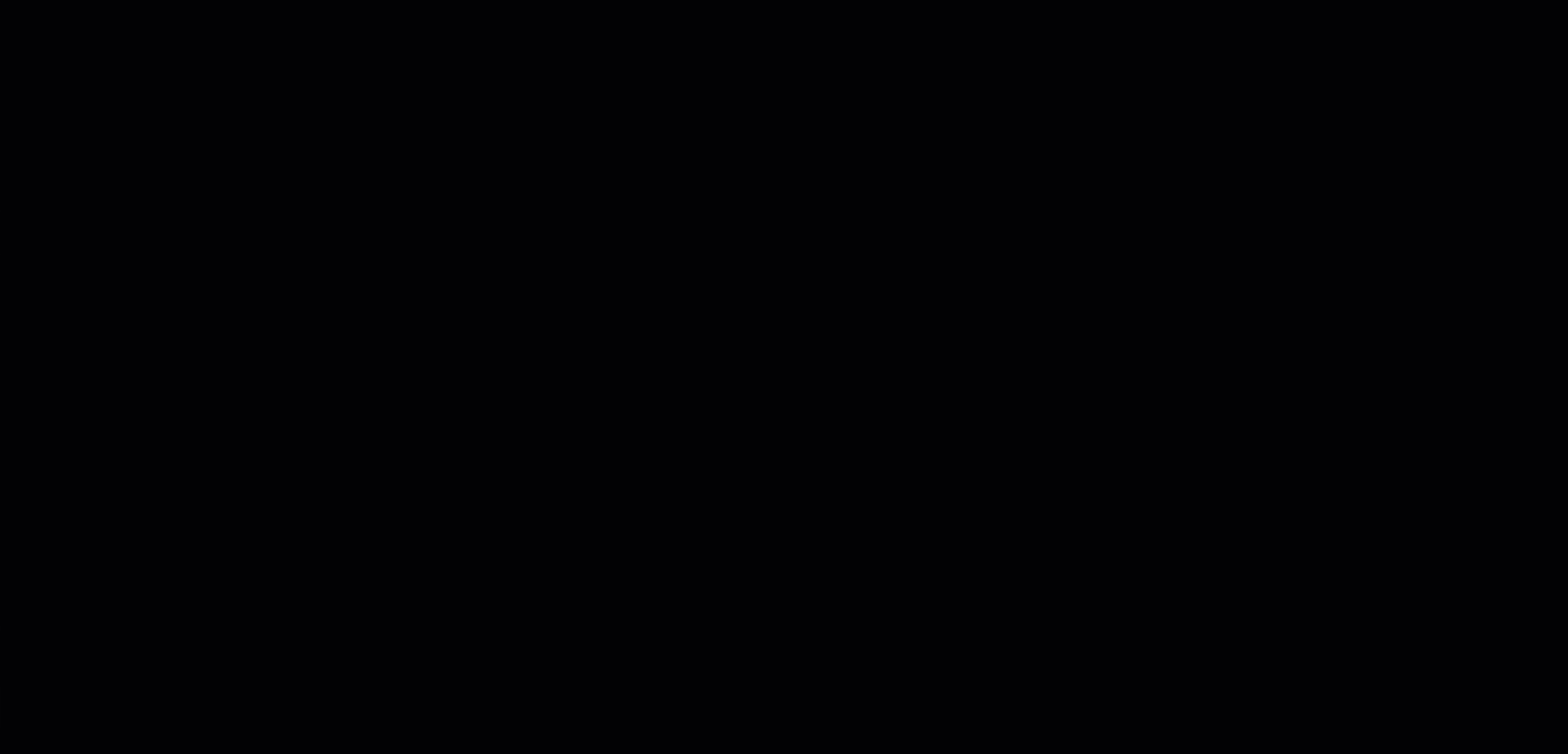
对托管映像的 Amazon S3 存储桶使用以下 CORS 配置代码。有关如何配置 CORS 的说明,请参阅《Amazon Simple Storage Service 用户指南》中的配置跨源资源共享(CORS)。如果您使用 Amazon S3 控制台将策略添加到存储桶,则必须使用 JSON 格式。
JSON
[ { "AllowedHeaders": [ "*" ], "AllowedMethods": [ "PUT" ], "AllowedOrigins": [ "*" ], "ExposeHeaders": [ "Access-Control-Allow-Origin" ] } ]
XML
<CORSConfiguration> <CORSRule> <AllowedHeader>*</AllowedHeader> <AllowedOrigin>*</AllowedOrigin> <AllowedMethod>PUT</AllowedMethod> <ExposeHeader>Access-Control-Allow-Origin</ExposeHeader> </CORSRule> </CORSConfiguration>
下面的 GIF 演示了 Amazon S3 文档中使用 Amazon S3 控制台添加 CORS 头策略的说明。
自定义 Pipelines 作业的访问管理
您可以进一步自定义 IAM 策略,以便组织中的选定成员可以运行任意或所有管道步骤。例如,您可以向某些用户授予创建训练作业的权限,向另一组用户授予创建处理作业的权限,以及向所有用户授予运行其余步骤的权限。要使用此特征,请选择一个以您的作业名称为前缀的自定义字符串。您的管理员在允许的 ARN 前面加上前缀,而您的数据科学家则在管道实例化中包含此前缀。由于获允许用户的 IAM 策略包含带有指定前缀的作业 ARN,因此您的管道步骤的后续作业具有继续操作所需的权限。作业前缀默认情况下关闭,您必须在 Pipeline 类中启用此选项才能使用它。
对于关闭了前缀的作业,作业名称的格式如图所示,该名称由下表中所述的字段串联而成:
pipelines-<executionId>-<stepNamePrefix>-<entityToken>-<failureCount>
| 字段 | 定义 |
|---|---|
|
pipelines |
静态字符串,始终前置。此字符串将管道编排服务标识为作业的来源。 |
|
executionId |
正在运行的管道实例的随机缓冲区。 |
|
步 NamePrefix |
用户指定的步骤名称(在管道步骤的 |
|
entityToken |
随机令牌,用于确保步骤实体的幂等性。 |
|
failureCount |
当前为完成作业而尝试重试的次数。 |
在这种情况下,作业名称前面没有自定义前缀,相应的 IAM 策略必须与此字符串匹配。
对于开启作业前缀的用户,底层作业名称采用以下形式,自定义前缀指定为 MyBaseJobName:
<MyBaseJobName>-<executionId>-<entityToken>-<failureCount>
自定义前缀取代了静态pipelines字符串,以帮助您缩小可以作为管道一部分运行 SageMaker AI 作业的用户的选择范围。
前缀长度限制
作业名称具有特定于各个管道步骤的内部长度限制。此约束还限定了允许的前缀长度。前缀长度要求如下:
| 管道步骤 | 前缀长度 |
|---|---|
|
|
38 |
|
6 |
将作业前缀应用于 IAM 策略
您的管理员创建 IAM 策略,允许具有特定前缀的用户创建作业。以下示例策略允许数据科学家在使用 MyBaseJobName 前缀的情况下创建训练作业。
{ "Action": "sagemaker:CreateTrainingJob", "Effect": "Allow", "Resource": [ "arn:aws:sagemaker:region:account-id:*/MyBaseJobName-*" ] }
将作业前缀应用于管道实例化
您可以使用作业实例类的 *base_job_name 参数来指定前缀。
注意
创建管道步骤之前,您可以将带有 *base_job_name 参数的作业前缀传递给作业实例。此作业实例包含使作业作为管道中的一个步骤运行的必要信息。该参数因所使用的作业实例而异。以下列表显示了每种管道步骤类型应使用的参数:
-
对于
Estimator(TrainingStep)、Processor(ProcessingStep) 和AutoML(AutoMLStep) 类,使用base_job_name -
对于
Tuner类 (TuningStep),使用tuning_base_job_name -
对于
Transformer类 (TransformStep),使用transform_base_job_name -
对于
QualityCheckStep(Quality Check) 和ClarifyCheckstep(Clarify Check) 类,使用CheckJobConfig的base_job_name -
对于
Model类,使用的参数取决于您在将结果传递给ModelStep之前是运行create还是register-
如果您调用
create,则自定义前缀来自您构造模型(即Model(name=))时的name参数 -
如果您调用
register,则自定义前缀来自您调用register(即my_model.register(model_package_name=)model_package_name参数
-
以下示例说明了如何为新的训练作业实例指定前缀。
# Create a job instance xgb_train = Estimator( image_uri=image_uri, instance_type="ml.m5.xlarge", instance_count=1, output_path=model_path, role=role, subnets=["subnet-0ab12c34567de89f0"], base_job_name="MyBaseJobName" security_group_ids=["sg-1a2bbcc3bd4444e55"], tags = [ ... ] encrypt_inter_container_traffic=True, ) # Attach your job instance to a pipeline step step_train = TrainingStep( name="TestTrainingJob", estimator=xgb_train, inputs={ "train": TrainingInput(...), "validation": TrainingInput(...) } )
作业前缀默认情况下关闭。要选择使用此特征,请使用 PipelineDefinitionConfig 的 use_custom_job_prefix 选项,如以下代码片段所示:
from sagemaker.workflow.pipeline_definition_config import PipelineDefinitionConfig # Create a definition configuration and toggle on custom prefixing definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True); # Create a pipeline with a custom prefix pipeline = Pipeline( name="MyJobPrefixedPipeline", parameters=[...] steps=[...] pipeline_definition_config=definition_config )
创建并运行管道。以下示例创建并运行管道,还演示了如何关闭作业前缀并重新运行管道。
pipeline.create(role_arn=sagemaker.get_execution_role()) # Optionally, call definition() to confirm your prefixed job names are in the built JSON pipeline.definition() pipeline.start() # To run a pipeline without custom-prefixes, toggle off use_custom_job_prefix, update the pipeline # via upsert() or update(), and start a new run definition_config = PipelineDefinitionConfig(use_custom_job_prefix=False) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
同样,您可以为现有管道开启该特征,然后启动使用作业前缀的新运行。
definition_config = PipelineDefinitionConfig(use_custom_job_prefix=True) pipeline.pipeline_definition_config = definition_config pipeline.update() execution = pipeline.start()
最后,您可以在管道执行时调用 list_steps 来查看自定义前缀的作业。
steps = execution.list_steps() prefixed_training_job_name = steps['PipelineExecutionSteps'][0]['Metadata']['TrainingJob']['Arn']
自定义对管道版本的访问权限
您可以使用sagemaker:PipelineVersionId条件键授予对特定版本的 Amazon Pi SageMaker pelines 的自定义访问权限。例如,以下策略仅允许对版本 ID 为 6 及以上的管道启动执行或更新管道版本。
有关支持的条件键的更多信息,请参阅 Amazon A SageMaker I 的条件键。
使用管道的服务控制策略
服务控制策略(SCP)是一种组织策略,可用于管理组织中的权限。SCP 为您组织中的所有账户提供对最大可用权限的集中控制。通过在组织中使用 Pipelines,您可以确保数据科学家无需与 Amazon 控制台交互即可管理您的管道执行。
如果您的 SCP 使用的 VPC 限制访问 Amazon S3,则需要采取措施允许您的管道访问其他 Amazon S3 资源。
要允许 Pipelines 使用 JsonGet 功能访问 VPC 外部的 Amazon S3,请更新组织的 SCP,确保使用 Pipelines 的角色可以访问 Amazon S3。为此,请使用主体标签和条件键为管道执行器通过管道执行角色使用的角色创建一个异常情况。
允许 Pipelines 访问 VPC 以外的 Amazon S3
-
按照标记 IAM 用户和角色中的步骤为管道执行角色创建唯一标签。
-
使用您创建的标签的
Aws:PrincipalTag IAM条件键,在您的 SCP 中授予一个例外。有关更多信息,请参阅创建、更新和删除服务控制策略。