本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
评估模型
现在,您已经使用 Amazon A SageMaker I 训练和部署了一个模型,请评估该模型以确保它能对新数据生成准确的预测。要对模型进行评测,请使用在准备数据集中创建的测试数据集。
评估部署到 SageMaker AI 托管服务的模型
要评估模型并在生产环境中使用它,请使用测试数据集调用端点,然后检查您获得的推断是否返回您想要实现的目标准度。
评估模型
-
设置以下函数来预测测试集中的每一行。在下面的示例代码中,
rows参数用于指定每次预测的行数。您可以更改其值,以执行批量推理,充分利用实例的硬件资源。import numpy as np def predict(data, rows=1000): split_array = np.array_split(data, int(data.shape[0] / float(rows) + 1)) predictions = '' for array in split_array: predictions = ','.join([predictions, xgb_predictor.predict(array).decode('utf-8')]) return np.fromstring(predictions[1:], sep=',') -
运行以下代码对测试数据集进行预测并绘制直方图。您只需要使用测试数据集的特征列,不包括实际值的第 0 列。
import matplotlib.pyplot as plt predictions=predict(test.to_numpy()[:,1:]) plt.hist(predictions) plt.show()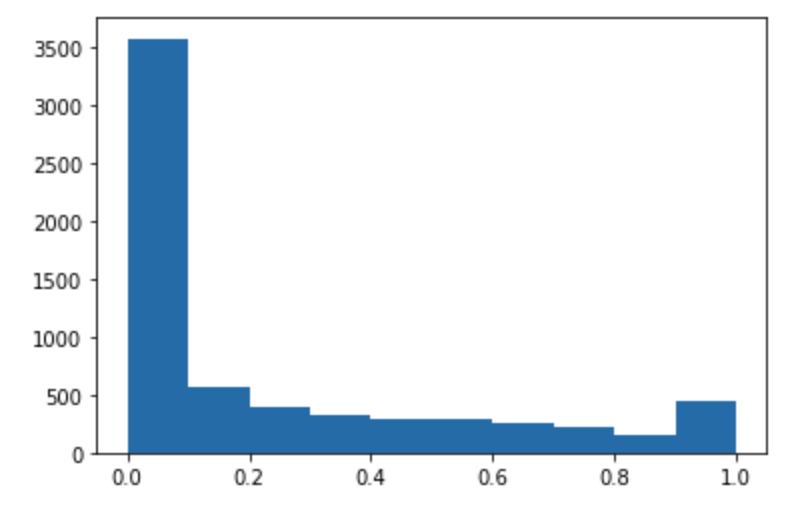
-
预测值为浮点型。要根据浮点值确定
True或False,需要设置一个截止值。如以下示例代码所示,使用 Scikit-learn 库返回截止值为 0.5 的输出混淆指标和分类报告。import sklearn cutoff=0.5 print(sklearn.metrics.confusion_matrix(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0))) print(sklearn.metrics.classification_report(test.iloc[:, 0], np.where(predictions > cutoff, 1, 0)))这应该返回以下混淆矩阵:
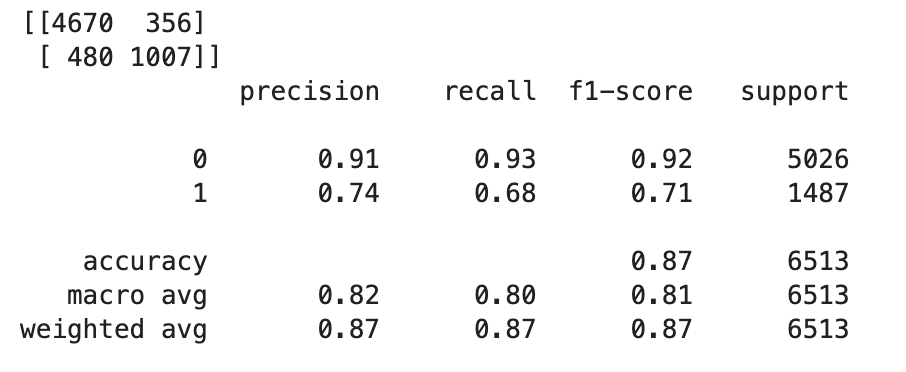
-
要根据给定的测试集找到最佳截止点,需要计算逻辑回归的对数损失函数。对数损失函数被定义为返回其 ground truth 标签预测概率的逻辑模型的负对数似然。下面的示例代码以数值迭代方式计算对数损失值 (
-(y*log(p)+(1-y)log(1-p)),其中y是真实标签,p是对应测试样本的概率估计。它返回一个对数损失与截止值的关系图。import matplotlib.pyplot as plt cutoffs = np.arange(0.01, 1, 0.01) log_loss = [] for c in cutoffs: log_loss.append( sklearn.metrics.log_loss(test.iloc[:, 0], np.where(predictions > c, 1, 0)) ) plt.figure(figsize=(15,10)) plt.plot(cutoffs, log_loss) plt.xlabel("Cutoff") plt.ylabel("Log loss") plt.show()这应该返回以下对数损失曲线。
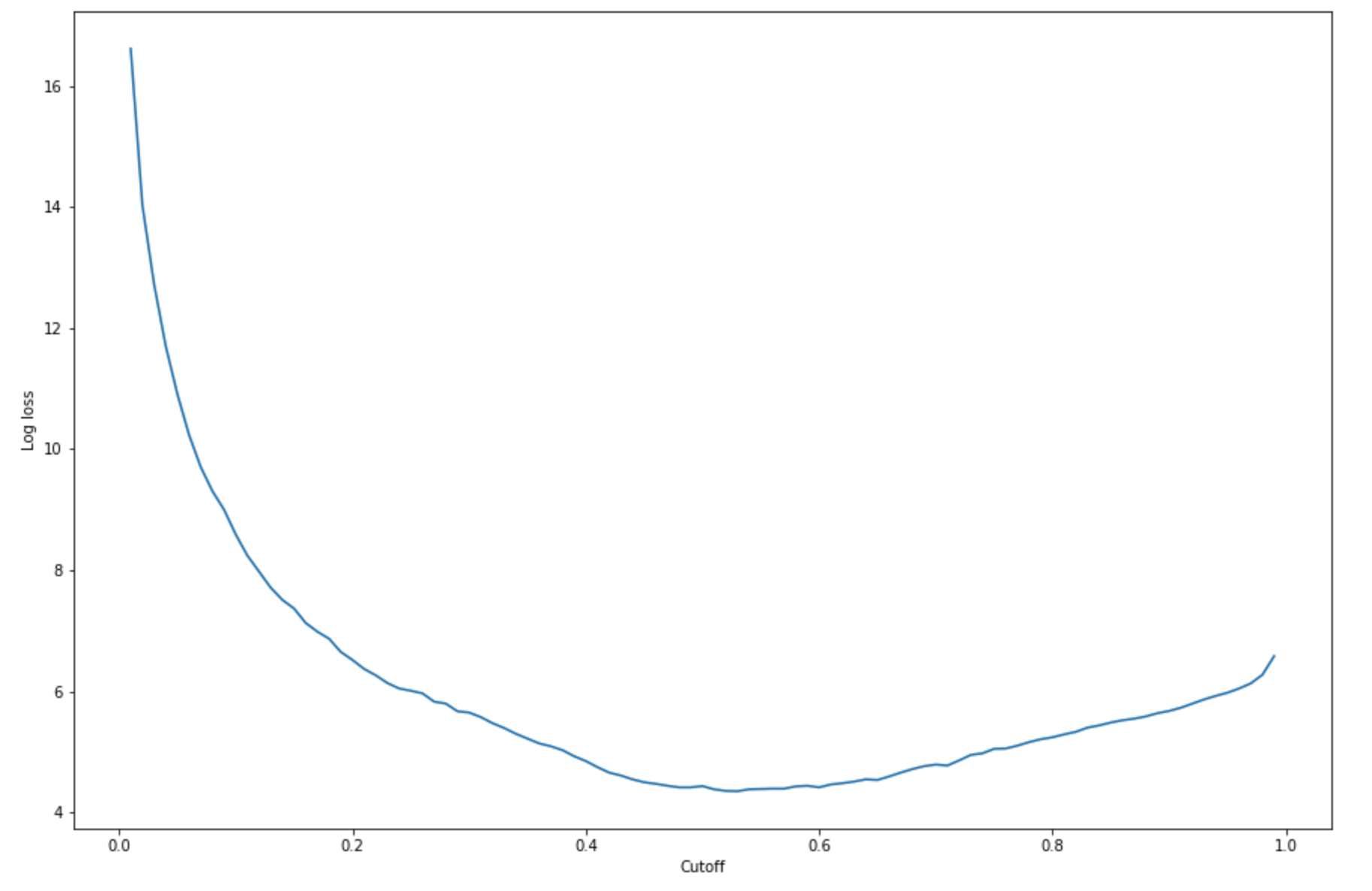
-
使用 NumPy
argmin和min函数找出误差曲线的最小点:print( 'Log loss is minimized at a cutoff of ', cutoffs[np.argmin(log_loss)], ', and the log loss value at the minimum is ', np.min(log_loss) )这应该返回
Log loss is minimized at a cutoff of 0.53, and the log loss value at the minimum is 4.348539186773897。您可以估算成本函数作为替代方案,而不是计算和最小化对数损失函数。例如,如果要训练模型以对业务问题(例如客户流失预测问题)执行二元分类,则可以为混淆矩阵元素设置权重,并相应地计算成本函数。
现在,您已经在 SageMaker AI 中训练、部署和评估了您的第一个模型。
提示
要监控模型质量、数据质量和偏差漂移,请使用 Amazon SageMaker 模型监控器和 A SageMaker I Clarify。要了解更多信息,请参阅 Amazon SageMaker 模型监视器、监控数据质量、监控模型质量、监控偏差偏差和监控特征归因偏差。
提示
要对置信度较低的 ML 预测或随机抽样预测进行人工审核,请使用 Amazon Augmented AI 人工审核工作流。有关更多信息,请参阅使用 Amazon Augmented AI 进行人工审核。