本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
Model Monitor 常见问题
有关 Amazon SageMaker 模型监视器的更多信息,请参阅以下常见问题解答。
问:Model Monitor and C SageMaker larify 如何帮助客户监控模型行为?
客户可以通过 Amazon Model Monitor 和 Clarify 从四个维度监控模型行为:数据质量、 SageMaker 模型质量、偏差漂移和 SageMaker 特征归因漂移。模型监控器
问:启用 SageMaker Model Monitor 后,后台会发生什么?
Amazon SageMaker Model Monitor 可自动监控模型,无需手动监控模型或构建任何其他工具。为了自动执行该过程,Model Monitor 使您能够使用训练模型时所用的数据创建一组基准统计数据和约束,然后设置计划来监控对端点所做的预测。Model Monitor 使用规则来检测模型中的偏差,并在出现偏差时提醒您。以下步骤描述了启用模型监控时会发生的情况:
-
启用模型监控:对于实时端点,您必须启用端点,以捕获从传入请求到已部署机器学习模型的数据以及由此产生的模型预测。对于批量转换作业,支持捕获批量转换输入和输出的数据。
-
基准处理作业:然后您从用于训练模型的数据集创建基准。该基准会计算指标并建议指标的约束条件。例如,模型的召回分数不应下降并降至0.571以下,或者精度分数不应降至1.0以下。 Real-time 或者,将模型中的批量预测与约束进行比较,如果这些预测超出约束值,则报告为违规。
-
监控作业:然后,您创建一个监控计划,该计划指定要收集的数据、数据收集频率、数据分析方式以及生成的报告。
-
合并任务:这仅适用于您使用 Amazon G SageMaker round Truth 的情况。Model Monitor 将您的模型所做的预测与 Ground Truth 标签进行比较,以衡量模型的质量。为此,您需要定期为端点或批量转换作业捕获的数据添加标签,然后将其上传到 Amazon S3。
创建并上传 Ground Truth 标签后,请在创建监控作业时将标签的位置作为参数包括在内。
当您使用 Model Monitor 监控批量转换作业而不是实时端点时,Model Monitor 将监控推理输入和输出,而不是接收对端点的请求并跟踪预测。在 Model Monitor 计划中,客户提供要在处理作业中使用的实例的数量和类型。无论当前执行的状态如何,这些资源都会一直保留到计划被删除为止。
问:什么是数据捕获,为什么需要它,以及如何启用它?
要将模型端点的输入以及已部署模型的推理输出记录到 Amazon S3,可以启用名为数据捕获的特征。有关如何为实时端点和批量转换作业启用该特征的更多详细信息,请参阅从实时端点捕获数据和从批量转换作业捕获数据。
问:启用数据捕获会影响实时端点的性能吗?
数据捕获以异步方式进行,不会影响生产流量。启用数据捕获后,请求和响应负载将与其他一些元数据一起保存到您在 DataCaptureConfig 中指定的 Amazon S3 位置。请注意,将捕获的数据传播到 Amazon S3 时可能会有延迟。
还可以通过列出存储在 Amazon S3 中的数据捕获文件来查看捕获的数据。Amazon S3 路径格式为:s3:///{endpoint-name}/{variant-name}/yyyy/mm/dd/hh/filename.jsonl。Amazon S3 数据捕获应与 Model Monitor 计划位于同一区域。您还应确保基准数据集的列名称仅使用小写字母,并使用下划线 (_) 作为唯一分隔符。
问:为什么模型监控需要 Ground Truth?
Model Monitor 的以下特征需要使用 Ground Truth 标签:
-
模型质量监控将您的模型所做的预测与 Ground Truth 标签进行比较,以衡量模型的质量。
-
模型偏差监控可监控预测是否存在偏差。在部署的机器学习模型中引入偏差的一种可能情况是当训练中使用的数据与用于生成预测的数据不同时。如果用于训练的数据会随着时间的推移而发生变化(例如抵押贷款利率的波动),模型预测的准确性就会大打折扣,除非使用更新的数据对模型进行再训练。例如,如果用于训练预测房价的模型的抵押贷款利率与现实世界中最新的抵押贷款利率不同,则该模型可能会有偏差。
问:对于利用 Ground Truth 进行标注的客户,我可以采取哪些措施来监控模型的质量?
模型质量监控将您的模型所做的预测与 Ground Truth 标签进行比较,以衡量模型的质量。为此,您需要定期为端点或批量转换作业捕获的数据添加标签,然后将其上传到 Amazon S3。除了捕获之外,模型偏差监控的执行还需要 Ground Truth 数据。在实际使用案例中,应定期收集 Ground Truth 数据并将其上传到指定的 Amazon S3 位置。要将 Ground Truth 标签与捕获的预测数据进行匹配,数据集中的每条记录都必须有一个唯一的标识符。有关 Ground Truth 数据的每条记录的结构,请参阅摄取 Ground Truth 标签并将其与预测合并。
以下代码示例可用于为表格数据集生成人工 Ground Truth 数据。
import random def ground_truth_with_id(inference_id): random.seed(inference_id) # to get consistent results rand = random.random() # format required by the merge container return { "groundTruthData": { "data": "1" if rand < 0.7 else "0", # randomly generate positive labels 70% of the time "encoding": "CSV", }, "eventMetadata": { "eventId": str(inference_id), }, "eventVersion": "0", } def upload_ground_truth(upload_time): records = [ground_truth_with_id(i) for i in range(test_dataset_size)] fake_records = [json.dumps(r) for r in records] data_to_upload = "\n".join(fake_records) target_s3_uri = f"{ground_truth_upload_path}/{upload_time:%Y/%m/%d/%H/%M%S}.jsonl" print(f"Uploading {len(fake_records)} records to", target_s3_uri) S3Uploader.upload_string_as_file_body(data_to_upload, target_s3_uri) # Generate data for the last hour upload_ground_truth(datetime.utcnow() - timedelta(hours=1)) # Generate data once a hour def generate_fake_ground_truth(terminate_event): upload_ground_truth(datetime.utcnow()) for _ in range(0, 60): time.sleep(60) if terminate_event.is_set(): break ground_truth_thread = WorkerThread(do_run=generate_fake_ground_truth) ground_truth_thread.start()
以下代码示例演示了如何生成人工流量以发送到模型端点。请注意上面用于调用的 inferenceId 属性。如果存在该属性,则用它联接 Ground Truth 数据(否则使用 eventId)。
import threading class WorkerThread(threading.Thread): def __init__(self, do_run, *args, **kwargs): super(WorkerThread, self).__init__(*args, **kwargs) self.__do_run = do_run self.__terminate_event = threading.Event() def terminate(self): self.__terminate_event.set() def run(self): while not self.__terminate_event.is_set(): self.__do_run(self.__terminate_event) def invoke_endpoint(terminate_event): with open(test_dataset, "r") as f: i = 0 for row in f: payload = row.rstrip("\n") response = sagemaker_runtime_client.invoke_endpoint( EndpointName=endpoint_name, ContentType="text/csv", Body=payload, InferenceId=str(i), # unique ID per row ) i += 1 response["Body"].read() time.sleep(1) if terminate_event.is_set(): break # Keep invoking the endpoint with test data invoke_endpoint_thread = WorkerThread(do_run=invoke_endpoint) invoke_endpoint_thread.start()
必须将 Ground Truth 数据上传到路径格式与已捕获数据的路径格式相同的 Amazon S3 存储桶,格式如下:s3://<bucket>/<prefix>/yyyy/mm/dd/hh
注意
此路径中的日期是收集 Ground Truth 标签的日期。它不必与生成推理的日期相匹配。
问:客户如何自定义监控计划?
除了使用内置监控机制之外,还可以使用预处理和后处理脚本,或通过使用或构建您自己的容器来创建您自己的自定义监控计划和过程。需要注意的是,预处理和后处理脚本仅适用于数据和模型质量作业。
Amazon SageMaker AI 让您能够监控和评估模型终端节点观察到的数据。为此,您必须创建一个用于比较实时流量的基准。基准准备就绪后,请设置一个计划,以持续评估并与基准进行比较。创建计划时,您可以提供预处理和后处理脚本。
以下示例说明如何使用预处理和后处理脚本自定义监控计划。
import boto3, osfrom sagemaker import get_execution_role, Sessionfrom sagemaker.model_monitor import CronExpressionGenerator, DefaultModelMonitor # Upload pre and postprocessor scripts session = Session() bucket = boto3.Session().resource("s3").Bucket(session.default_bucket()) prefix = "demo-sagemaker-model-monitor" pre_processor_script = bucket.Object(os.path.join(prefix, "preprocessor.py")).upload_file("preprocessor.py") post_processor_script = bucket.Object(os.path.join(prefix, "postprocessor.py")).upload_file("postprocessor.py") # Get execution role role = get_execution_role() # can be an empty string # Instance type instance_type = "instance-type" # instance_type = "ml.m5.xlarge" # Example # Create a monitoring schedule with pre and post-processing my_default_monitor = DefaultModelMonitor( role=role, instance_count=1, instance_type=instance_type, volume_size_in_gb=20, max_runtime_in_seconds=3600, ) s3_report_path = "s3://{}/{}".format(bucket, "reports") monitor_schedule_name = "monitor-schedule-name" endpoint_name = "endpoint-name" my_default_monitor.create_monitoring_schedule( post_analytics_processor_script=post_processor_script, record_preprocessor_script=pre_processor_script, monitor_schedule_name=monitor_schedule_name, # use endpoint_input for real-time endpoint endpoint_input=endpoint_name, # or use batch_transform_input for batch transform jobs # batch_transform_input=batch_transform_name, output_s3_uri=s3_report_path, statistics=my_default_monitor.baseline_statistics(), constraints=my_default_monitor.suggested_constraints(), schedule_cron_expression=CronExpressionGenerator.hourly(), enable_cloudwatch_metrics=True, )
问:我可以在哪些场景或使用案例中使用预处理脚本?
当需要转换对 Model Monitor 的输入时,可以使用预处理脚本。考虑以下示例场景:
-
Pre-processing 用于数据转换的脚本。
假设模型的输出是一个数组:
[1.0, 2.1]。Model Monitor 容器仅适用于表格式或平面 JSON 结构,如{“prediction0”: 1.0, “prediction1” : 2.1}。您可以使用如下例所示的预处理脚本将数组转换为正确的 JSON 结构。def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data output_data = inference_record.endpoint_output.data.rstrip("\n") data = output_data + "," + input_data return { str(i).zfill(20) : d for i, d in enumerate(data.split(",")) } -
从 Model Monitor 的指标计算中排除某些记录。
假设您的模型具有可选特征,而您使用
-1表示该可选特征有缺失值。如果您有数据质量监控器,则可能需要从输入值数组中删除-1,使其不包含在监控器的指标计算中。您可以使用如下所示的脚本来删除这些值。def preprocess_handler(inference_record): input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
应用自定义采样策略。
您也可以在预处理脚本中应用自定义采样策略。为此,请将 Model Monitor 的第一方预构建容器配置为根据您指定的采样率忽略一定比例的记录。在以下示例中,处理程序通过在 10% 的处理程序调用中返回记录,否则返回空列表,从而对 10% 的记录进行采样。
import random def preprocess_handler(inference_record): # we set up a sampling rate of 0.1 if random.random() > 0.1: # return an empty list return [] input_data = inference_record.endpoint_input.data return {i : None if x == -1 else x for i, x in enumerate(input_data.split(","))} -
使用自定义日志记录。
您可以将脚本中所需的任何信息记录到 Amazon CloudWatch。这在调试预处理脚本以防出现错误时非常有用。以下示例说明如何使用
preprocess_handler界面登录 CloudWatch。def preprocess_handler(inference_record, logger): logger.info(f"I'm a processing record: {inference_record}") logger.debug(f"I'm debugging a processing record: {inference_record}") logger.warning(f"I'm processing record with missing value: {inference_record}") logger.error(f"I'm a processing record with bad value: {inference_record}") return inference_record
注意
对批量转换数据运行预处理脚本时,输入类型并不总是 CapturedData 对象。对于 CSV 数据,类型为字符串。对于 JSON 数据,类型为 Python 字典。
问:我什么时候可以利用后处理脚本?
成功运行监控后,您可以将后处理脚本用作扩展。以下是一个简单示例,但您可以执行或调用成功运行监控后需要执行的任何业务功能。
def postprocess_handler(): print("Hello from the post-processing script!")
问:我什么时候应该考虑自带容器进行模型监控?
SageMaker AI 提供了一个预先构建的容器,用于分析从端点捕获的数据或表格数据集的批量转换作业。但在某些情况下,您可能需要创建自己的容器。考虑以下场景:
-
您需要满足监管和合规性要求,只能使用在组织内部创建和维护的容器。
-
如果要包含一些第三方库,则可以将
requirements.txt文件放在本地目录中,然后使用 SageMaker AI 估算器中的 source_dir参数引用该文件,这样可以在运行时安装库。但是,如果您有许多库或依赖关系,在运行训练作业时会增加安装时间,则可能需要利用 BYOC。 -
您所处的环境不允许连接互联网(或 Silo),因此无法下载软件包。
-
您要监控的数据格式不是表格式,如 NLP 或 CV 使用案例。
-
当您需要除 Model Monitor 支持的监控指标之外的其他监控指标时。
问:我有 NLP 和 CV 模型。如何监控它们是否存在数据偏差?
Amazon SageMaker AI 的预构建容器支持表格数据集。如果您想监控 NLP 和 CV 模型,可以利用 Model Monitor 提供的扩展点自带容器。有关要求的更多详细信息,请参阅自带容器。下面提供了更多示例:
-
有关如何将 Model Monitor 用于计算机视觉使用案例的详细说明,请参阅检测和分析错误的预测
。 -
有关模型监视器可用于 NLP 用例的场景,请参阅使用自定义 Ama SageMaker zon 模型监控器检测 NLP 数据偏差
。
问:我想删除已启用 Model Monitor 的模型端点,但由于监控计划仍处于活动状态,因此无法删除。我应该怎么办?
如果要删除已启用模型监控器的 SageMaker AI 中托管的推理端点,则必须先删除模型监控计划(使用 DeleteMonitoringSchedule CLI 或 API)。然后,删除该端点。
问: SageMaker 模型监控器是否会计算输入的指标和统计数据?
Model Monitor 计算输出而不是输入的指标和统计数据。
问: SageMaker 模型监视器是否支持多模型端点?
否,Model Monitor 仅支持托管单个模型的端点,不支持监控多模型端点。
问: SageMaker 模型监控器是否提供有关推理管道中各个容器的监控数据?
Model Monitor 支持监控推理管道,但捕获和分析数据是针对整个管道而不是针对管道中的各个容器完成的。
问:设置数据捕获后,我能做些什么来防止推理请求受到影响?
为了防止对推理请求产生影响,数据捕获功能会在磁盘利用率较高时停止捕获请求。建议将磁盘利用率保持在 75% 以下,以确保数据捕获功能继续捕获请求。
问:Amazon S3 数据捕获能否位于与设置监控计划的 Amazon 区域不同的区域?
否,Amazon S3 数据捕获必须与监控计划位于同一区域。
问:什么是基准,如何创建基准? 我可以创建自定义基准吗?
基准用作比较模型的实时预测或批量预测的参考。它计算统计数据和指标以及对它们的约束。监控期间,将结合使用所有这些来识别违规行为。
要使用亚马逊 SageMaker 模型监控器的默认解决方案,您可以利用亚马逊 SageMaker Python 软件开发工具包
基准作业的结果是两个文件:statistics.json 和 constraints.json。统计数据的架构和约束的架构包含相应文件的架构。使用生成的约束进行监控之前,您可以查看这些约束并对其进行修改。根据您对域和业务问题的理解,您可以使约束更严格,也可以放宽约束以控制违规的数量和性质。
问:创建基准数据集的指导原则是什么?
任何监控的首要条件都是要有一个基准数据集,用于计算指标和约束。通常,这是模型使用的训练数据集,但在某些情况下,您可能会选择使用其他参考数据集。
基准数据集的列名称应与 Spark 兼容。为了保持 Spark、CSV、JSON 和 Parquet 之间的最大兼容性,建议仅使用小写字母,并且仅使用 _ 作为分隔符。包括 “ ” 在内的特殊字符可能会导致问题。
问:StartTimeOffset 和 EndTimeOffset 参数是什么?何时使用它们?
当需要使用 Amazon G SageMaker round Truth 来监控模型质量等任务时,您需要确保监控任务仅使用可用 Ground Truth 的数据。的start_time_offset和end_time_offset参数EndpointInputstart_time_offset 和 end_time_offset 定义的时段中的数据。这些参数需要以 ISO 8601 持续时间格式
-
如果 Ground Truth 结果在做出预测后 3 天到达,请设置
start_time_offset="-P3D"和end_time_offset="-P1D",分别为 3 天和 1 天。 -
如果 Ground Truth 结果在做出预测后 6 小时到达,并且您设置了每小时计划,请设置
start_time_offset="-PT6H"和end_time_offset="-PT1H",分别为 6 小时和 1 小时。
问:我是否可以运行“按需”监控作业?
是的,您可以通过运行 Processing 作业来运行 “按需” 监控作业。 SageMaker 对于 Batch Transform MonitorBatchTransformStep
问:如何设置 Model Monitor?
您可以使用以下方法设置 Model Monitor:
-
Amazon SageMaker AI Python SDK
— 有一个模型监控器模块 ,其中包含有助于建议基准、创建监控计划等的类和函数。有关利用 A SageMaker I Python SDK 设置 SageMaker 模型监控器的详细笔记本,请参阅 Amazon 模型监视器笔记本示例 。 -
管道 — 通过QualityCheck 步骤和 ClarifyCheckStepAPI 将管道与模型监视器集成。您可以创建包含这些步骤的 SageMaker AI 管道,该管道可用于在执行管道时按需运行监控作业。
-
Amazon SageMaker Studio Classic — 您可以从已部署的模型终端节点列表中选择终端节点,直接从用户界面创建数据或模型质量监控计划以及模型偏差和可解释性计划。通过选择 UI 中的相关选项卡,可以创建其他类型监控的计划。
-
SageMaker 模型控制面板-您可以通过选择已部署到端点的模型来启用对端点的监控。在以下 SageMaker AI 控制台屏幕截图中,
group1已从 “模型” 仪表板的 “模型” 部分中选择了一个名为的模型。在此页面上,您可以创建监控计划,也可以编辑、激活或停用现有的监控计划和警报。有关如何查看警报和 Model Monitor 计划的分步指南,请参阅查看 Model Monitor 计划和警报。
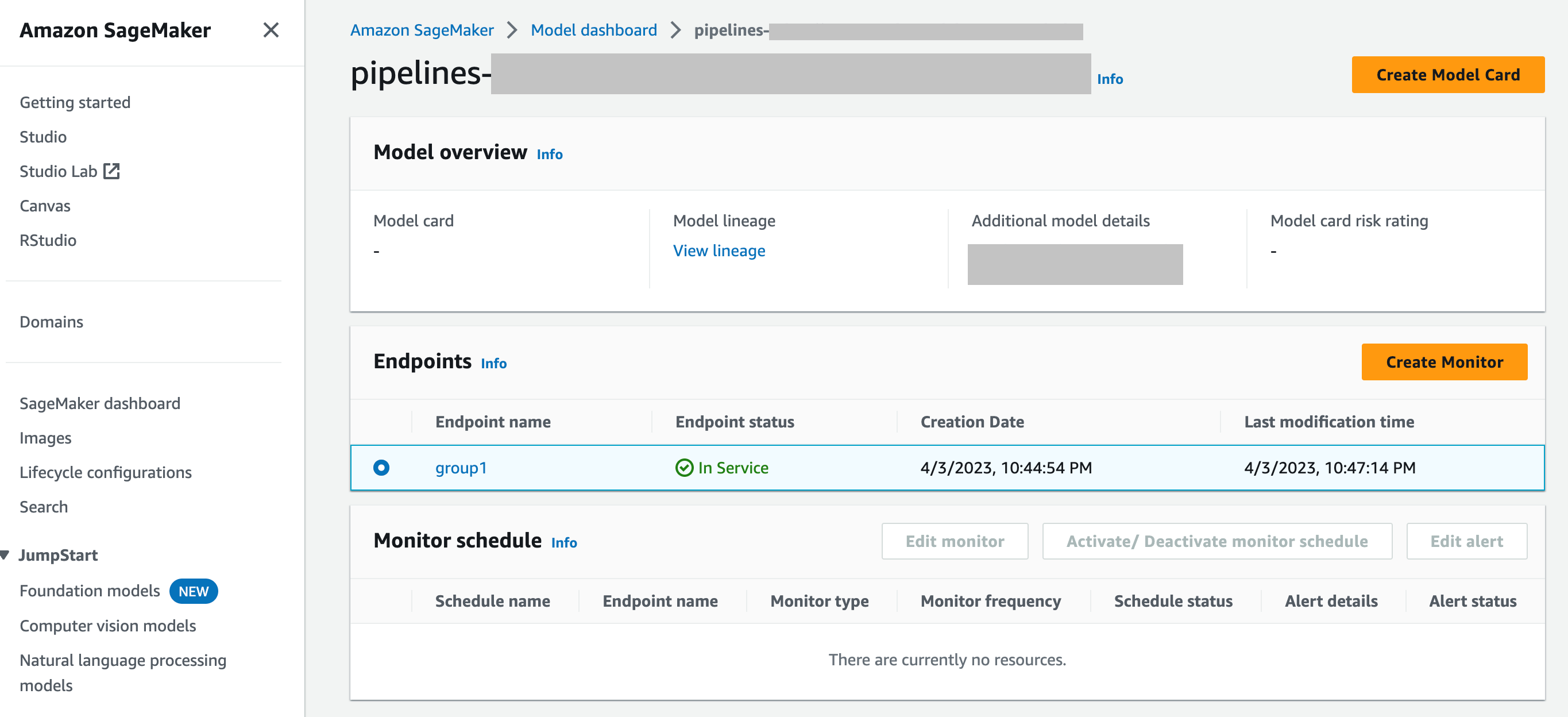
问:模型监视器如何与 SageMaker 模型仪表板集成
SageMaker Model Das hboard 通过提供有关偏离预期行为的自动警报和故障排除,以检查模型并分析随时间推移影响模型性能的因素,从而对所有模型进行统一监控。