本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
管道概述
Amazon SageMaker AI 管道是有向无环图 (DAG) 中一系列相互关联的步骤,这些步骤使用拖放用户界面或 Pipelines SDK 进行定义。
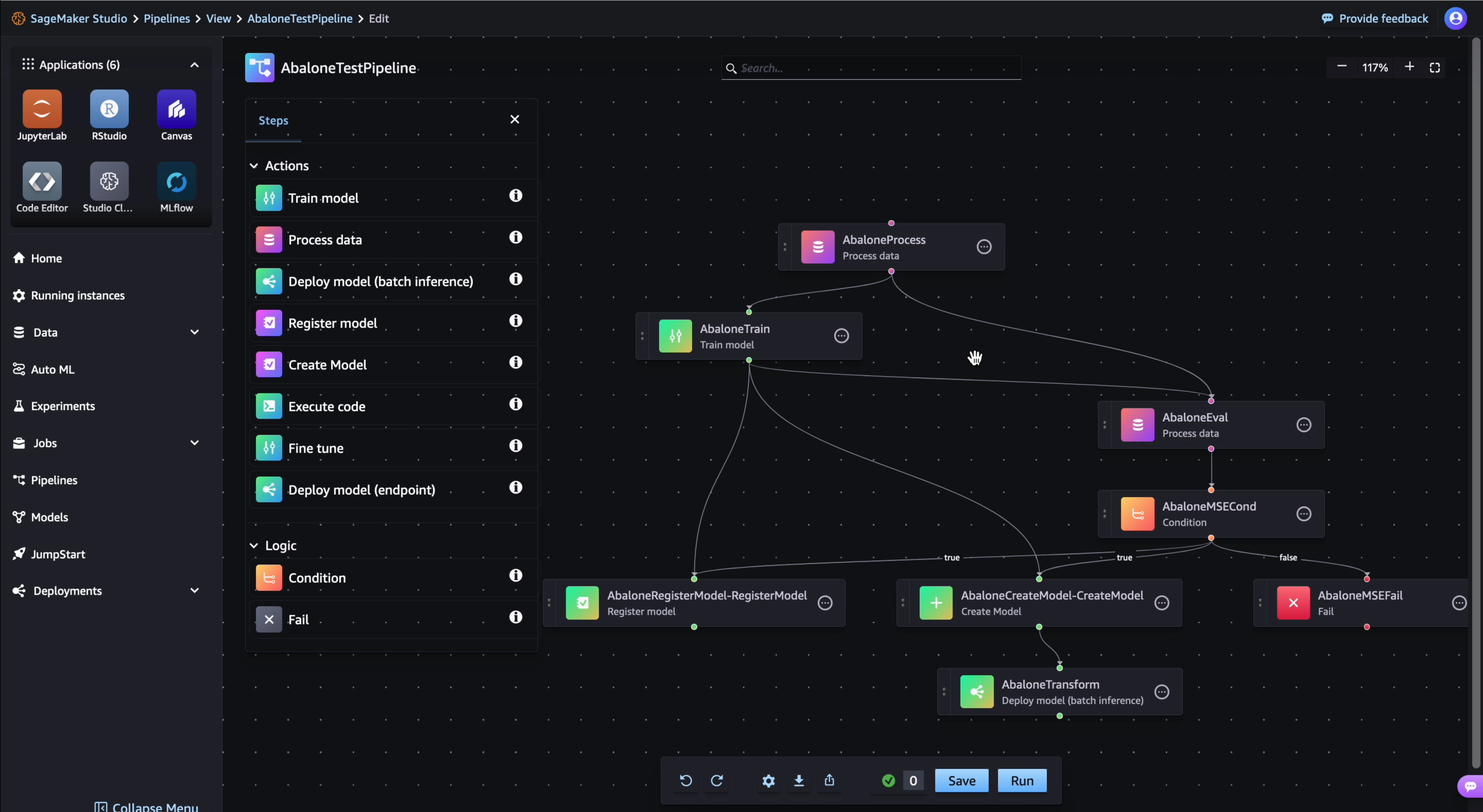
示例 DAG 包括以下步骤:
-
AbaloneProcess是处理步骤的一个实例,在用于训练的数据上运行预处理脚本。例如,脚本可以填充缺失值,对数值数据进行规范化处理,或将数据分成训练数据集、验证数据集和测试数据集。 -
AbaloneTrain是训练步骤的一个实例,用于配置超参数,并根据预处理的输入数据训练模型。 -
AbaloneEval是处理步骤的另一个实例,用于评估模型的准确性。本步骤展示了一个数据依赖的例子 - 本步骤使用AbaloneProcess的测试数据集输出。 -
AbaloneMSECond是条件步骤的一个实例,在本例中,它检查模型评测的均方误差结果是否低于某个限值。如果模型不符合标准,管道运行就会停止。 -
管道运行按以下步骤进行:
-
AbaloneRegisterModel,其中 SageMaker AI 调用RegisterModel步骤将模型作为版本控制的模型包组注册到 Amazon SageMaker 模型注册表中。 -
AbaloneCreateModel,其中 SageMaker AI 调用一个CreateModel步骤来创建模型,为批量转换做准备。在中AbaloneTransform, SageMaker AI 调用 “转换” 步骤,对您指定的数据集生成模型预测。
-
以下主题介绍了 Pipelines 的基本概念。有关描述这些概念的实施的教程,请参阅Pipelines 操作。