本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
管道
Amaz SageMaker on Pipelines 是一项专门构建的工作流程编排服务,用于自动进行机器学习 (ML) 开发。
与其他 Amazon 工作流程产品相比,管道具有以下优势:
Auto-scaling 无服务器基础架构您无需管理底层编排基础设施即可运行 Pipelines,这使您可以专注于核心机器学习任务。 SageMaker AI 会根据您的机器学习工作负载的要求自动配置、扩展和关闭管道编排计算资源。
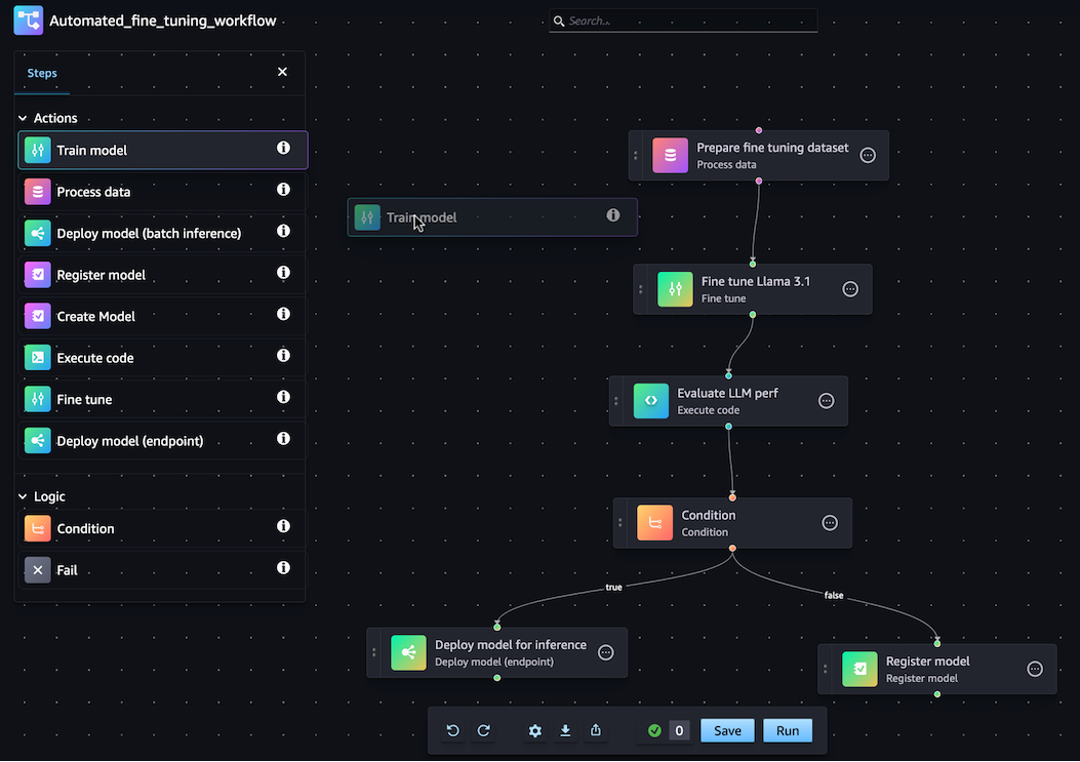
直观的用户体验可通过所选界面创建和管理管道:可视化编辑器、SDK、API 或 JSON。您可以拖放各种机器学习步骤,在 Amazon SageMaker Studio 可视化界面中创作您的管道。下面的截图显示了 Studio 管道可视化编辑器。
如果您更喜欢以编程方式管理机器学习工作流程, SageMaker Python SDK 可提供高级编排功能。有关更多信息,请参阅 Python 软件开发工具包 SageMaker 文档中的 Amaz
Amazon 集成 Pipelines 提供与所有 SageMaker AI 功能和其他 Amazon 服务的无缝集成,可自动执行数据处理、模型训练、微调、评估、部署和监控作业。您可以将 SageMaker AI 功能整合到您的管道中,并使用深度链接在这些功能中进行导航,从而大规模创建、监控和调试您的机器学习工作流程。
降低成本使用 Pipelines,您只需为 SageMaker Studio 环境和由管道编排的底层作业(例如 SageMaker 训练、 SageMaker 处理、 SageMaker AI 推理和 Amazon S3 数据存储)付费。
可审计性和任务流水线追踪功能:有了 Pipelines,您可以使用内置的版本控制功能来跟踪管道更新与执行的历史记录。Amazon SageMaker ML Lineage Tracking 可帮助您分析端到端机器学习开发生命周期中的数据源和数据使用者。