本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
使用 Amazon SageMaker 无服务器推理部署模型
Amazon SageMaker Serverless Inference 是一个专门构建的推理选项,使您无需配置或管理任何底层基础设施即可部署和扩展机器学习模型。 On-demand 无服务器推理非常适合在流量激增之间有空闲时间并且可以容忍冷启动的工作负载。无服务器端点可自动启动计算资源,并根据流量的大小扩展和缩减资源,而无需选择实例类型或管理扩展策略。这消除了选择和管理服务器的无差别繁重工作。无服务器推理与 Amazon Lambda 集成,为您提供高可用性、内置容错能力和自动扩展功能。无服务器推理采用按使用量付费的模式,如果您的流量模式不频繁或不可预测,那么无服务器推理是一种经济高效的选择。在没有请求的情况下,无服务器推理会将您的端点缩减到 0,从而使您能最大限度地降低成本。有关按需无服务器推理定价的更多信息,请参阅 A ma SageMaker
您还可以选择将预置并发与无服务器推理结合使用。当您的流量出现可预测的突发情况时,使用预置并发的无服务器推理是一种经济高效的选择。Provisioned Concurrency 允许您在无服务器端点上部署模型,这些模型具有可预测的性能,并通过保持终端保温来实现高可扩展性。 SageMaker AI 可确保根据您分配的预配置并发数量,计算资源已初始化并准备好在几毫秒内做出响应。对于使用预置并发的无服务器推理,您需要为用于处理推理请求的计算容量付费,按毫秒和处理的数据量计费。您还需根据配置的内存、预置的持续时间和启用的并发量,为预置并发使用量付费。有关使用预配置并发的无服务器推理定价的更多信息,请参阅 Amazon 定价。 SageMaker
您可以将无服务器推理与 MLOps Pipelines 集成以简化 ML 工作流,还可以使用无服务器端点来托管在模型注册表中注册的模型。
无服务器推理现已在 21 Amazon 个地区推出:美国东部(弗吉尼亚北部)、美国东部(俄亥俄州)、美国西部(加利福尼亚北部)、美国西部(俄勒冈)、非洲(开普敦)、亚太地区(香港)、亚太地区(孟买)、亚太地区(东京)、亚太地区(首尔)、亚太地区(大阪)、亚太地区(新加坡)、亚太地区(悉尼)、加拿大(中部)、欧洲(法兰克福)、欧洲(爱尔兰)、欧洲(伦敦)、欧洲(巴黎)、欧洲(斯德哥尔摩)、欧洲(米兰)、中东(巴林)、南美洲(圣保罗)。有关 Amazon A SageMaker I 区域可用性的更多信息,请参阅Amazon 区域服务列表
工作原理
下图显示了按需无服务器推理的工作流以及使用无服务器端点的好处。
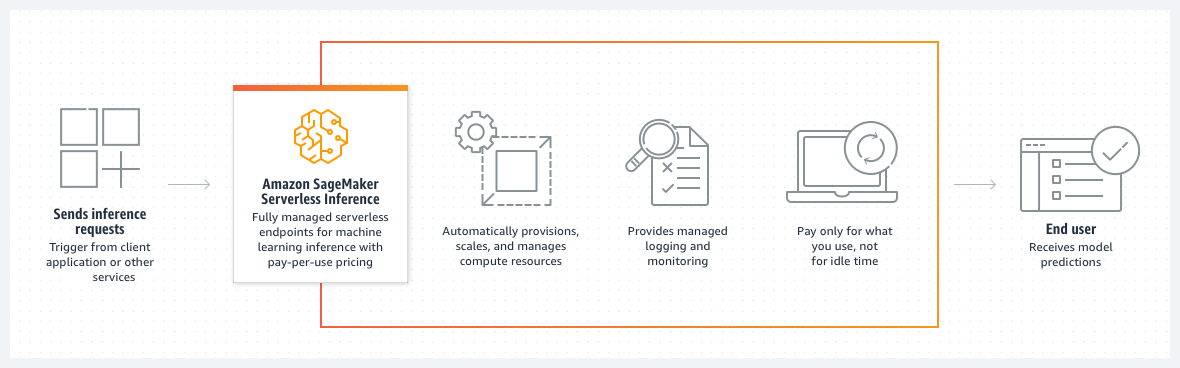
当您创建按需无服务器端点时, SageMaker AI 会为您配置和管理计算资源。然后,您可以向终端节点发出推理请求并接收模型预测作为响应。 SageMaker AI 可根据需要向上和向下扩展计算资源以处理您的请求流量,而且您只需为实际使用的资源付费。
对于预置并发,无服务器推理还与 Application Auto Scaling 集成,因此您可以根据目标指标或计划管理预置并发。有关更多信息,请参阅 自动扩展无服务器端点的预置并发。
以下各节提供了有关无服务器推理及其工作方式的其他详细信息。
容器支持
对于您的终端节点容器,您可以选择 SageMaker AI-provided 容器或自带容器。 SageMaker 人工智能为其内置算法提供了容器,并为一些最常见的机器学习框架(例如 Apache MX TensorFlow net、、和 Chainer)提供了预构建的 Docker 镜像。 PyTorch有关可用 SageMaker 图像的列表,请参阅可用的 Deep Learning Containers 镜像
您可以使用的容器映像的最大大小为 10 GB。对于无服务器端点,我们建议在容器中只创建一个 worker,并且只加载模型的一个副本。请注意,这与实时端点不同,在实时端点中,某些 SageMaker AI 容器可能会为每个 vCPU 创建一个工作线程来处理推理请求并将模型加载到每个 worker 中。
如果您已经有一个用于实时端点的容器,您就可以将相同的容器用于无服务器端点,不过某些功能会被排除在外。要了解有关无服务器推理不支持的容器功能的更多信息,请参阅功能排除。如果您选择使用同一个容器, SageMaker AI 会托管(保留)您的容器映像的副本,直到您删除使用该映像的所有端点。 SageMaker AI 使用密 SageMaker AI-owned Amazon KMS 钥对复制的静态图像进行加密。
内存大小
无服务器端点的最小 RAM 大小为 1024 MB (1 GB),可选择的最大 RAM 大小为 6144 MB (6 GB)。您可以选择的内存大小有 1024 MB、2048 MB、3072 MB、4096 MB、5120 MB 或 6144 MB。无服务器推理会自动分配与所选内存成比例的计算资源。如果选择更大的内存大小,容器就可以访问更多的 vCPU。根据模型大小选择端点内存大小。一般来说,内存大小至少应与模型大小相同。您可能需要进行基准测试,以便根据延迟 SLA 为模型选择合适的内存大小。有关基准测试的分步指南,请参阅 Amazon SageMaker 无服务器推理基准测试工具包简
无论您选择多大的内存,您的无服务器端点都有 5 GB 的临时磁盘存储空间可用。要解决使用存储时的容器权限问题,请参阅问题排查。
并发调用
On-demand Serverless Inference 管理预定义的扩展策略和终端节点容量的配额。无服务器端点对同时处理并发调用的数量有限额限制。如果端点在处理完第一个请求之前被调用,那么它将并发地处理第二个请求。
您可以在账户中的所有无服务器端点之间共享的总并发量取决于您所在的区域:
-
对于美国东部(俄亥俄州)、美国东部(弗吉尼亚州北部)、美国西部(俄勒冈州)、亚太地区(新加坡)、亚太地区(悉尼)、亚太地区(东京)、欧洲地区(法兰克福)和欧洲地区(爱尔兰)区域,您账户中每个区域的所有无服务器端点之间可共享的总并发量为 1000。
-
对于美国西部(北加利福尼亚)、非洲(开普敦)、亚太地区(香港)、亚太地区(孟买)、亚太地区(大阪)、亚太地区(首尔)、加拿大(中部)、欧洲地区(伦敦)、欧洲地区(米兰)、欧洲地区(巴黎)、欧洲地区(斯德哥尔摩)、中东(巴林)和南美洲(圣保罗)区域,您账户中每个区域的总并发量为 500。
您可以将单个端点的最大并发量设置为 200,一个区域中可托管的无服务器端点总数为 50。单个端点的最大并发量可防止该端点占用账户允许的所有调用,任何超出最大值的端点调用都会被节流。
注意
分配给无服务器端点的预置并发应始终小于或等于分配给该端点的最大并发量。
要了解如何设置端点的最大并发量,请参阅创建端点配置。有关配额和限制的更多信息,请参阅中的 Amazon SageMaker AI 终端节点和配额Amazon Web Services 一般参考。如需提高服务限制,请联系 Amazon Support
最大限度减少冷启动
如果您的按需无服务器推理端点有一段时间没有收到流量,然后突然收到新请求,那么您的端点可能需要一些时间才能启动计算资源来处理这些请求。这称为冷启动。由于无服务器端点按需预置计算资源,因此您的端点可能会出现冷启动。如果并发请求超过当前并发请求使用量,也会出现冷启动。冷启动时间取决于模型大小、下载模型所需的时间以及容器的启动时间。
要监控您的冷启动时间有多长,您可以使用 Amazon CloudWatch 指标OverheadLatency来监控您的无服务器终端节点。该指标跟踪为端点启动新计算资源所需的时间。要了解有关在无服务器端点上使用 CloudWatch指标的更多信息,请参阅用于跟踪无服务器端点指标的警报和日志。
您可以使用预配置并发来最大限度地减少冷启动。 SageMaker 对于您分配的预配置并发数量,AI 会使端点保持温暖状态,并准备好在毫秒内做出响应。
功能排除
无服务器推理不支持目前可用于 SageMaker AI Real-time 推理的某些功能,包括 GPU、 Amazon 市场模型包、私有 Docker 注册表、 Multi-Model 端点、VPC 配置、网络隔离、数据捕获、多种生产变体、模型监控器和推理管道。
您不能将基于实例的实时端点转换为无服务器端点。如果您尝试将实时端点更新为无服务器端点,您会收到 ValidationError 消息。您可以将无服务器端点转换为实时端点,但一旦进行了更新,就无法将其还原为无服务器端点。
开始使用
您可以使用 SageMaker AI 控制台、 Amazon 软件开发工具包、Amaz on Pyth SageMaker on 软件开发工具包
注意
Amazon CloudFormation目前不支持使用预置并发的无服务器推理的 Application Auto Scaling。
示例笔记本和博客
有关展示端到端无服务器端点工作流的 Jupyter 笔记本示例,请参阅无服务器推理示例笔记本