本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
什么是 Step Functions?
管理状态和转换数据
了解有关使用变量在状态之间传递数据和使用转换数据的信息 JSONata。
借Amazon Step Functions助,您可以创建工作流(也称为)状态机,以构建分布式应用程序、实现流程自动化、协调微服务以及创建数据和机器学习管道。
Step Functions 基于状态机 和任务。在 Step Functions 中,状态机称为工作流程,是一系列由事件驱动的步骤。工作流程中的每个步骤都称为状态。例如,任务状态表示另一个Amazon服务执行的工作单元,例如调用另一个服务Amazon Web Services 服务或 API。在 Step Functions 中,运行用于执行任务的工作流程的实例称为执行。
状态机任务中的工作也可以使用活动来完成,活动是存在于 Step Functions 之外的工作线程。
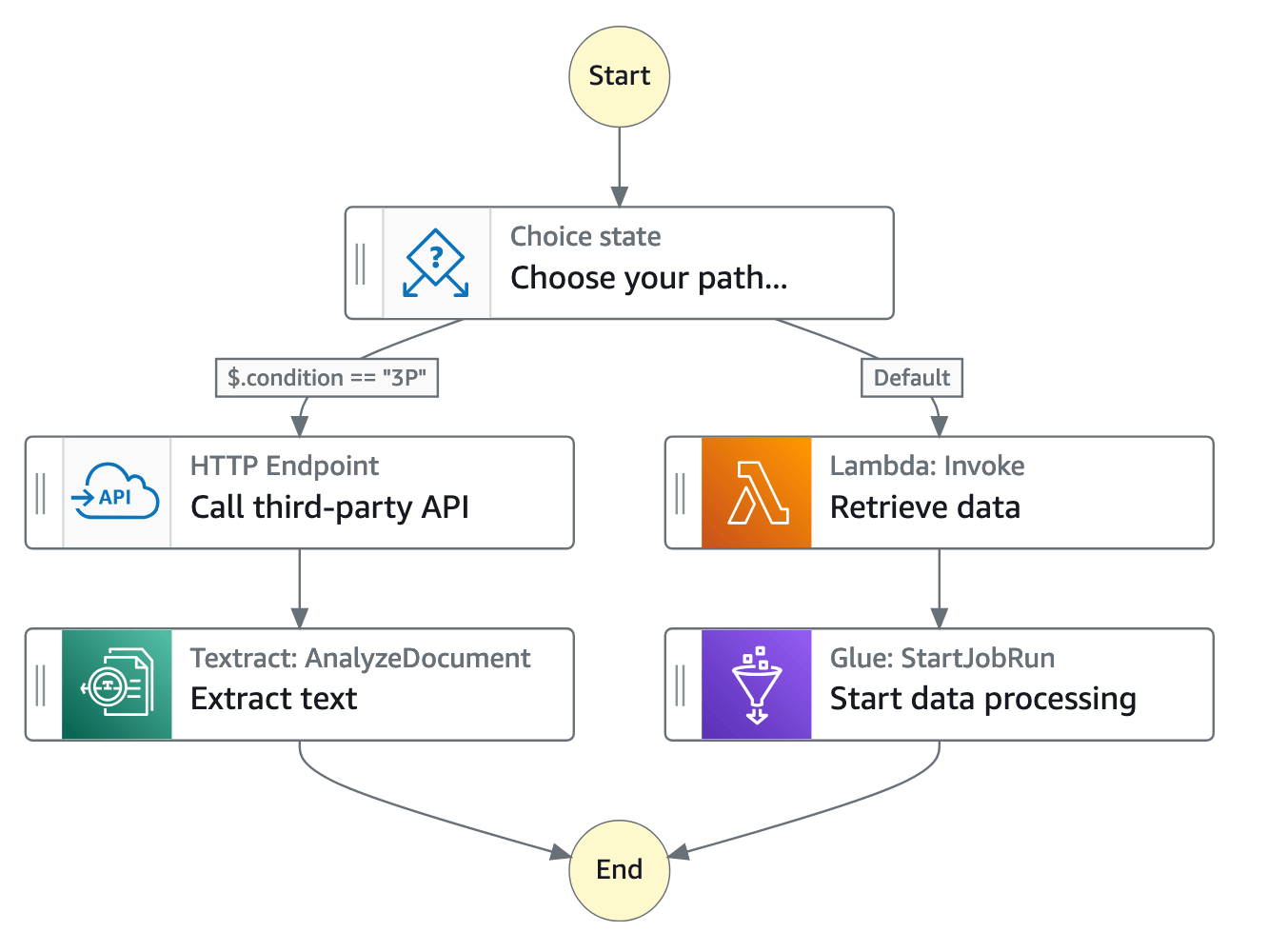
在 Step Functions 的控制台中,可以可视化、编辑和调试应用程序的工作流程。可以检查工作流程中每个步骤的状态,以便确保应用程序按预期依顺序运行。
根据您的用例,您可以让 Step Functions 调用Amazon服务(例如 Lambda)来执行任务。您可以使用 Step Functions 控制Amazon服务Amazon Glue,例如用于创建提取、转换和加载工作流程。您还可以为需要人为交互的应用程序创建长时间运行的自动化工作流。
有关提供 Step Fun Amazon ctions 的区域的完整列表,请参阅Amazon区域表
了解如何使用 Step Functions
从本指南中的入门教程开始。有关高级主题和使用案例,请参阅 The Step Functions Workshop
标准和快速工作流程类型
Step Functions 具有两种工作流程类型:
-
标准工作流程非常适合长时间运行、可审计的工作流程,因为这类工作流程会显示执行历史记录和可视化调试。
标准工作流程包含仅一次工作流程执行,并且最多可以运行一年。这表示标准工作流中的每个步骤将只执行一次。
-
Express 工作流程非常适合 high-event-rate工作负载,例如流数据处理和物联网数据摄取。
Express at-least-once工作流程具有工作流程执行功能,最多可以运行五分钟。这表示快速工作流中的一个或多个步骤可能会运行多次,而工作流中的每个步骤至少会执行一次。
| 标准工作流 | 快速工作流 |
|---|---|
| 每秒 2000 的执行速率 | 每秒 100000 的执行速率 |
| 每秒 4000 的状态转换速率 | 状态转换速率几乎不受限制 |
| 按状态转换定价 | 按执行次数和执行持续时间定价 |
| 显示执行历史记录和可视化调试 | 根据日志级别显示执行历史记录和可视化调试 |
| 在 Step Functions 中查看执行历史记录 |
将执行历史发送到 CloudWatch |
| 支持与所有服务集成。 支持与某些服务的优化集成。 |
支持与所有服务集成。 |
| 对于所有服务支持请求响应 模式 Support Run a J ob 在特定服务中 and/or 等待回调模式(详情请参阅以下部分) |
对于所有服务支持请求响应 模式 |
有关 Step Functions 定价和选择工作流程类型的更多信息,请参阅以下内容:
与其他 服务集成
Step Functions 与多种Amazon服务集成。要调用其他Amazon服务,您可以使用两种集成类型:
-
AmazonSDK 集成提供了一种直接从状态机调用任何Amazon服务的方法,使您可以访问成千上万个 API 操作。
-
优化集成提供了在状态机中使用这些服务的自定义选项。
要将 Step Functions 与其它服务结合使用,有三种服务集成模式:
-
调用服务,并让 Step Functions 在获得 HTTP 响应后进入下一个状态。
-
调用服务,并让 Step Functions 等待作业完成。
-
使用任务令牌调用服务,并让 Step Functions 等到任务令牌带着回调返回。
标准工作流程和快速工作流程支持相同的集成,但支持的集成模式不同。
-
标准工作流程支持请求响应 集成。某些服务支持 Run a Job (.sync) 或等待回调 (. waitForTask代币),在某些情况下两者兼而有之。有关详细信息,请参阅以下优化集成表。
-
快速工作流程仅支持请求响应 集成。
为协助在两种类型之间做出选择,请参阅在 Step Functions 中选择工作流程类型。
AmazonStep Functions 中的 SDK 集成
| 集成 服务 | 请求响应 | 运行任务:.sync | 等待回电-. waitForTask代币 |
|---|---|---|---|
| 超过两百项服务 | 标准和快速 | 不支持 | 标准 |
Step Functions 中的优化集成
| 集成 服务 | 请求响应 | 运行任务:.sync | 等待回电-. waitForTask代币 |
|---|---|---|---|
| Amazon API Gateway | 标准和快速 | 不支持 | 标准 |
| Amazon Athena | 标准和快速 | 标准 | 不支持 |
| Amazon Batch | 标准和快速 | 标准 | 不支持 |
| Amazon Bedrock | 标准和快速 | 标准 | 标准 |
| Amazon CodeBuild | 标准和快速 | 标准 | 不支持 |
| Amazon DynamoDB | 标准和快速 | 不支持 | 不支持 |
| Amazon ECS/Fargate | 标准和快速 | 标准 | 标准 |
| Amazon EKS | 标准和快速 | 标准 | 标准 |
| Amazon EMR | 标准和快速 | 标准 | 不支持 |
| Amazon EMR on EKS | 标准和快速 | 标准 | 不支持 |
| Amazon EMR Serverless | 标准和快速 | 标准 | 不支持 |
| Amazon EventBridge | 标准和快速 | 不支持 | 标准 |
| Amazon Glue | 标准和快速 | 标准 | 不支持 |
| Amazon Glue DataBrew | 标准和快速 | 标准 | 不支持 |
| Amazon Lambda | 标准和快速 | 不支持 | 标准 |
| AWS Elemental MediaConvert | 标准和快速 | 标准 | 不支持 |
| Amazon SageMaker AI | 标准和快速 | 标准 | 不支持 |
| Amazon SNS | 标准和快速 | 不支持 | 标准 |
| Amazon SQS | 标准和快速 | 不支持 | 标准 |
| Amazon Step Functions | 标准和快速 | 标准 | 标准 |
工作流程的用例示例
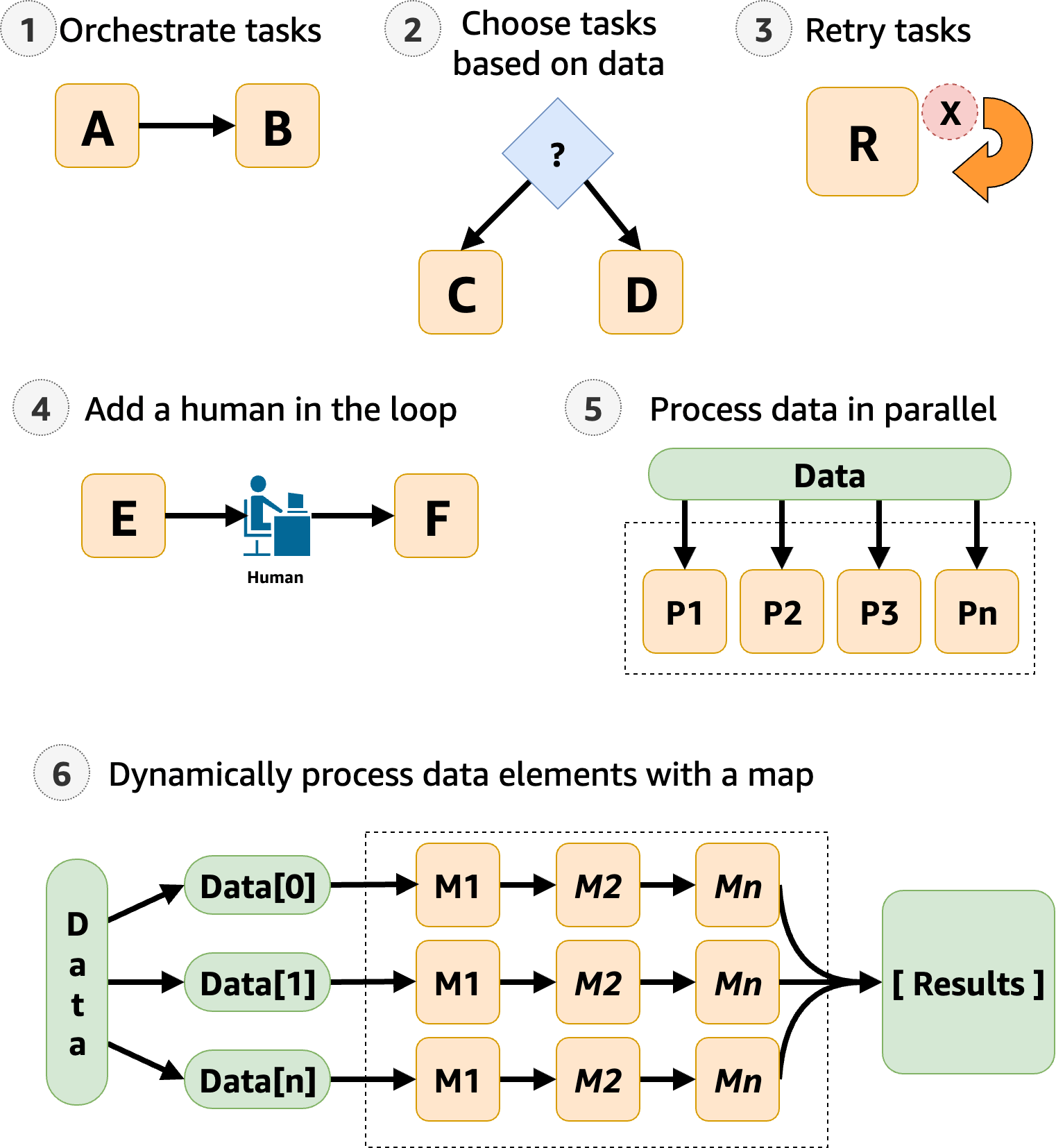
Step Functions 用于管理应用程序的组件和逻辑,因此可以减少编写的代码,从而专注于快速构建和更新应用程序。下图显示了 Step Functions 工作流程的六个用例。
-
编排任务:可以创建按特定顺序编排一系列任务或步骤 的工作流程。例如,任务 A 可能是一个 Lambda 函数,它为任务 B 中的另一个 Lambda 函数提供输入。工作流程的最后一个步骤将提供最终结果。
-
根据数据选择任务:使用
Choice状态,可让 Step Functions 根据状态的输入做出决策。例如,假设一位客户申请提高信用额度。如果该申请超过了客户预先批准的信用额度,则可以让 Step Functions 将客户的申请发送给经理进行签署。如果该申请低于客户预先批准的信用额度,则可以让 Step Functions 自动批准该申请。 -
错误处理(
Retry/Catch):可以重试失败的任务,或者捕获失败的任务并自动运行替代步骤。例如,在客户请求用户名后,第一次调用验证服务可能会失败,因此工作流程可能会重试该请求。第二个请求成功时,工作流程就可以继续推进了。
或者,也许客户请求的用户名无效或不可用,
Catch语句可能会导致一个 Step Functions 工作流程步骤来建议使用其它用户名。有关
Retry和Catch的示例,请参阅处理 Step Functions 工作流程中的错误。 -
加入人工审批:Step Functions 可以在工作流程中加入人工审批步骤。例如,假设一位银行客户试图向朋友汇款。通过回调和任务令牌,可以让 Step Functions 等到客户的朋友确认转账,然后 Step Functions 将继续推进该工作流程,向银行客户通知转账已完成。
-
以并行步骤处理数据:使用
Parallel状态,Step Functions 可以采用并行步骤来处理输入数据。例如,客户可能需要将视频文件转换为多种显示分辨率,以便查看者可以在多台设备上观看视频。您的工作流程可以将原始视频文件发送到多个 Lambda 函数,或者使用优化的AWS Elemental MediaConvert集成将视频同时处理为多种显示分辨率。 -
动态处理数据元素:使用
Map状态,Step Functions 可以对数据集中的每个项目运行一组工作流程步骤。迭代以并行方式运行,这可以实现快速处理数据集。例如,当您的客户订购三十件商品时,系统需要应用相同的工作流程来准备每件商品进行配送。将所有商品收集并打包好进行配送后,下一步可能是快速向客户发送一封包含跟踪信息的确认电子邮件。有关示例初学者模板,请参阅处理具有 Map 的数据。