将 Amazon Aurora 机器学习与 Aurora MySQL 结合使用
通过将 Amazon Aurora 机器学习与您的 Aurora MySQL 数据库集群结合使用,您可以根据需要使用 Amazon Bedrock、Amazon Comprehend 或 Amazon SageMaker AI。这些服务分别支持不同的机器学习使用案例。
目录
将 Aurora 机器学习与 Aurora MySQL 结合使用的要求
Amazon 机器学习服务是在其自己的生产环境中设置和运行的托管式服务。Aurora 机器学习支持与 Amazon Bedrock、Amazon Comprehend 和 SageMaker AI 相集成。在尝试将 Aurora MySQL 数据库集群设置为使用 Aurora 机器学习之前,请务必了解以下要求和先决条件。
-
机器学习服务必须与您的 Aurora MySQL 数据库集群在相同的 Amazon Web Services 区域中运行。您不能在不同区域的 Aurora MySQL 数据库集群中使用机器学习服务。
-
如果 Aurora MySQL 数据库集群与 Amazon Bedrock、Amazon Comprehend 或 SageMaker AI 服务位于不同的虚拟公有云(VPC)中,则 VPC 的安全组需要允许与目标 Aurora 机器学习服务的出站连接。有关更多信息,请参阅《Amazon VPC 用户指南》中的使用安全组控制到 Amazon 资源的流量。
-
如果您要将 Aurora 机器学习与该集群结合使用,您可以将运行较低版本 Aurora MySQL 的 Aurora 集群升级到支持的更高版本。有关更多信息,请参阅 Amazon Aurora MySQL 的数据库引擎更新。
-
Aurora MySQL 数据库集群必须使用自定义数据库集群参数组。在您要使用的每个 Aurora 机器学习服务的设置过程结束时,添加为该服务创建的关联 IAM 角色的 Amazon 资源名称(ARN)。建议您事先为 Aurora MySQL 创建自定义数据库集群参数组,并将您的 Aurora MySQL 数据库集群配置为使用该参数组,以便在设置过程结束时做好修改准备。
-
对于 SageMaker AI:
-
您要用于推理的机器学习组件必须设置好并准备就绪。在配置 Aurora MySQL 数据库集群的过程中,确保具有 SageMaker AI 端点的 ARN。您团队中的数据科学家可能最有能力使用 SageMaker AI,以准备模型并处理其他此类任务。要开始使用 Amazon SageMaker AI,请参阅 Get Started with Amazon SageMaker AI。有关推理和端点的更多信息,请参阅实时推理。
-
要将 SageMaker AI 用于您自己的训练数据,您必须设置 Amazon S3 存储桶,作为 Aurora 机器学习的 Aurora MySQL 配置的一部分。为此,您需要遵循与设置 SageMaker AI 集成相同的常规流程。有关此可选设置过程的摘要,请参阅设置 Aurora MySQL 数据库集群以将 Amazon S3 用于 SageMaker AI(可选)。
-
-
对于 Aurora Global Database,您可以设置要在构成 Aurora Global Database 的所有 Amazon Web Services 区域中使用的 Aurora 机器学习服务。例如,如果您想将 Aurora 机器学习以及 SageMaker AI 一起用于 Aurora Global Database,则可以对每个 Amazon Web Services 区域中的每个 Aurora MySQL 数据库集群执行以下操作:
-
使用相同的 SageMaker AI 训练模型和端点设置 Amazon SageMaker AI 服务。它们也必须使用相同的名称。
-
创建 IAM 角色,详见设置 Aurora MySQL 数据库集群以使用 Aurora 机器学习。
-
将 IAM 角色的 ARN 添加到每个 Amazon Web Services 区域中每个 Aurora MySQL 数据库集群的自定义数据库集群参数组中。
这些任务要求在构成 Aurora Global Database 的所有 Amazon Web Services 区域中,Aurora 机器学习均可用于您的 Aurora MySQL 版本。
-
区域和版本可用性
功能可用性和支持因每个 Aurora 数据库引擎的特定版本以及 Amazon Web Services 区域而异。
-
有关适用于 Aurora MySQL 的 Amazon Comprehend 和 Amazon SageMaker AI 的版本和区域可用性的信息,请参阅使用 Aurora MySQL 的 Aurora 机器学习。
-
仅 Aurora MySQL 版本 3.06 及更高版本支持 Amazon Bedrock。
有关 Amazon Bedrock 的区域可用性的信息,请参阅《Amazon Bedrock 用户指南》中的 Model support by Amazon Web Services 区域。
Aurora 机器学习与 Aurora MySQL 结合使用时支持的功能和限制
将 Aurora MySQL 与 Aurora 机器学习结合使用时,以下限制适用:
-
Aurora 机器学习扩展不支持向量接口。
-
在触发器中使用时,不支持 Aurora 机器学习集成。
Aurora 机器学习函数与二进制日志(binlog)复制不兼容。
-
调用 Aurora 机器学习函数时,设置
--binlog-format=STATEMENT引发异常。 -
Aurora 机器学习函数是不确定的,而不确定的存储函数与 binlog 格式不兼容。
有关更多信息,请参阅 MySQL 文档中的 Binary Logging Formats
。 -
-
如果存储函数调用带有 generated-always 列的表,则不支持此类函数。这适用于任何 Aurora MySQL 存储函数。要了解有关此列类型的更多信息,请参阅 MySQL 文档中的 CREATE TABLE 和生成的列
。 -
Amazon Bedrock 函数不支持
RETURNS JSON。如果需要,您可以使用CONVERT或CAST从TEXT转换为JSON。 -
Amazon Bedrock 不支持批量请求。
-
Aurora MySQL 通过将
ContentType设置为text/csv,来支持任何可读取和写入逗号分隔值(CSV)格式的 SageMaker AI 端点。这种格式已被以下内置的 SageMaker AI 算法所接受:-
线性学习器
-
Random Cut Forest
-
XGBoost
要了解有关这些算法的更多信息,请参阅《Amazon SageMaker AI 开发人员指南》中的 Choose an Algorithm。
-
设置 Aurora MySQL 数据库集群以使用 Aurora 机器学习
在以下主题中,您可以找到其中每个 Aurora 机器学习服务的单独设置过程。
主题
设置 Aurora MySQL 数据库集群以使用 Amazon Bedrock
Aurora 机器学习依赖于 Amazon Identity and Access Management(IAM)角色和策略来允许 Aurora MySQL 数据库集群访问和使用 Amazon Bedrock 服务。以下过程创建 IAM 权限策略和角色,以便您的数据库集群可以与 Amazon Bedrock 集成。
创建 IAM policy
登录 Amazon Web Services 管理控制台,然后通过以下网址打开 IAM 控制台:https://console.aws.amazon.com/iam/
。 -
在导航窗格中选择策略。
-
选择创建策略。
-
在指定权限页面上,对于选择服务,选择 Bedrock。
将显示 Amazon Bedrock 权限。
-
展开读取,然后选择 InvokeModel。
-
对于资源,选择全部。
指定权限页面应与下图类似。

-
选择下一步。
-
在审核并创建页面上,输入策略的名称,例如
BedrockInvokeModel。 -
查看您的策略,然后选择创建策略。
接下来,您将创建使用 Amazon Bedrock 权限策略的 IAM 角色。
创建 IAM 角色
登录Amazon Web Services 管理控制台,然后通过以下网址打开 IAM 控制台:https://console.aws.amazon.com/iam/
。 -
在导航窗格中选择 Roles。
-
选择创建角色。
-
在选择可信实体页面上,对于使用案例,选择 RDS。
-
选择 RDS - 向数据库添加角色,然后选择下一步。
-
在添加权限页面上,对于权限策略,选择您创建的 IAM 策略,然后选择下一步。
-
在命名、查看和创建页面上,输入角色的名称,例如
ams-bedrock-invoke-model-role。角色应与下图类似。

-
检查您的角色,然后选择创建角色。
接下来,将 Amazon Bedrock IAM 角色与数据库集群关联。
将 IAM 角色与您的数据库集群关联
登录Amazon Web Services 管理控制台并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
从导航窗格中选择 Databases (数据库)。
-
选择要连接到 Amazon Bedrock 服务的 Aurora MySQL 数据库集群。
-
选择连接和安全性选项卡。
-
在管理 IAM 角色部分,选择选择要添加到此集群的 IAM。
-
选择您创建的 IAM,然后选择添加角色。
IAM 角色与您的数据库集群相关联,最初状态为待定,然后为活动。该过程完成后,您可以在当前该集群的 IAM 角色列表中找到该角色。

您必须将此 IAM 角色的 ARN 添加到与 Aurora MySQL 数据库集群关联的自定义数据库集群参数组的 aws_default_bedrock_role 参数中。如果 Aurora MySQL 数据库集群不使用自定义数据库集群参数组,则需要创建一个与 Aurora MySQL 数据库集群结合使用的此类参数组,以完成集成。有关更多信息,请参阅 Amazon Aurora 数据库集群的数据库集群参数组。
配置数据库集群参数
-
在 Amazon RDS 控制台中,打开 Aurora MySQL 数据库集群的 Configuration(配置)选项卡。
-
找到为集群配置的数据库集群参数组。选择链接以打开自定义数据库集群参数组,然后选择编辑。
-
在自定义数据库集群参数组中找到
aws_default_bedrock_role参数。 -
在值字段中,输入 IAM 角色的 ARN。
-
选择 Save changes(保存更改)以保存设置。
-
重启 Aurora MySQL 数据库集群的主实例,以使此参数设置生效。
Amazon Bedrock 的 IAM 集成已完成。按照授予数据库用户访问 Aurora 机器学习的权限所述,继续设置 Aurora MySQL 数据库集群以与 Amazon Bedrock 结合使用。
设置 Aurora MySQL 数据库集群以使用 Amazon Comprehend
Aurora 机器学习依赖于 Amazon Identity and Access Management 角色和策略来允许 Aurora MySQL 数据库集群访问和使用 Amazon Comprehend 服务。以下过程会自动为您的集群创建 IAM 角色和策略,以便它可以使用 Amazon Comprehend。
设置 Aurora MySQL 数据库集群以使用 Amazon Comprehend
登录Amazon Web Services 管理控制台并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
从导航窗格中选择 Databases (数据库)。
-
选择要连接到 Amazon Comprehend 服务的 Aurora MySQL 数据库集群。
-
选择连接和安全性选项卡。
-
对于管理 IAM 角色部分,选择选择一项服务连接到此集群。
-
从菜单中选择 Amazon Comprehend,然后选择连接服务。
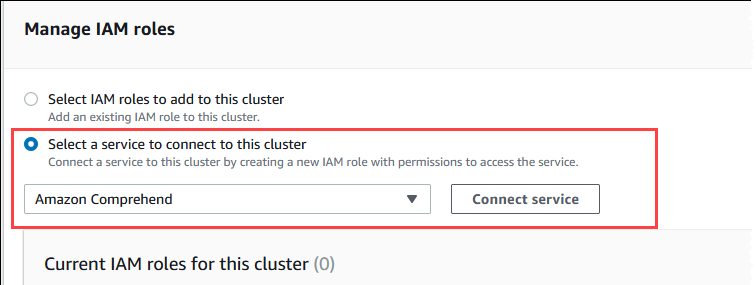
Connect cluster to Amazon Comprehend(将集群连接到 Amazon Comprehend)对话框不需要任何其他信息。但是,您可能会看到一条消息,通知您 Aurora 和 Amazon Comprehend 之间的集成目前处于预览阶段。请务必阅读该消息,然后再继续。如果您不想继续,可以选择取消。
选择 Connect service(连接服务)以完成集成过程。
Aurora 创建 IAM 角色。它还创建允许 Aurora MySQL 数据库集群使用 Amazon Comprehend 服务的策略,并将该策略附加到该角色。该过程完成后,您可以在 Current IAM roles for this cluster(此集群的当前 IAM 角色)列表中找到该角色,如下图所示。
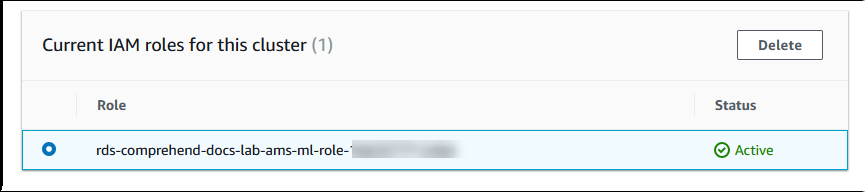
您需要将此 IAM 角色的 ARN 添加到与 Aurora MySQL 数据库集群关联的自定义数据库集群参数组的
aws_default_comprehend_role参数中。如果 Aurora MySQL 数据库集群不使用自定义数据库集群参数组,则需要创建一个与 Aurora MySQL 数据库集群结合使用的此类参数组,以完成集成。有关更多信息,请参阅 Amazon Aurora 数据库集群的数据库集群参数组。创建自定义数据库集群参数组并将其与 Aurora MySQL 数据库集群关联后,您可以继续执行以下步骤。
如果集群使用自定义数据库集群参数组,请执行以下操作。
在 Amazon RDS 控制台中,打开 Aurora MySQL 数据库集群的 Configuration(配置)选项卡。
-
找到为集群配置的数据库集群参数组。选择链接以打开自定义数据库集群参数组,然后选择编辑。
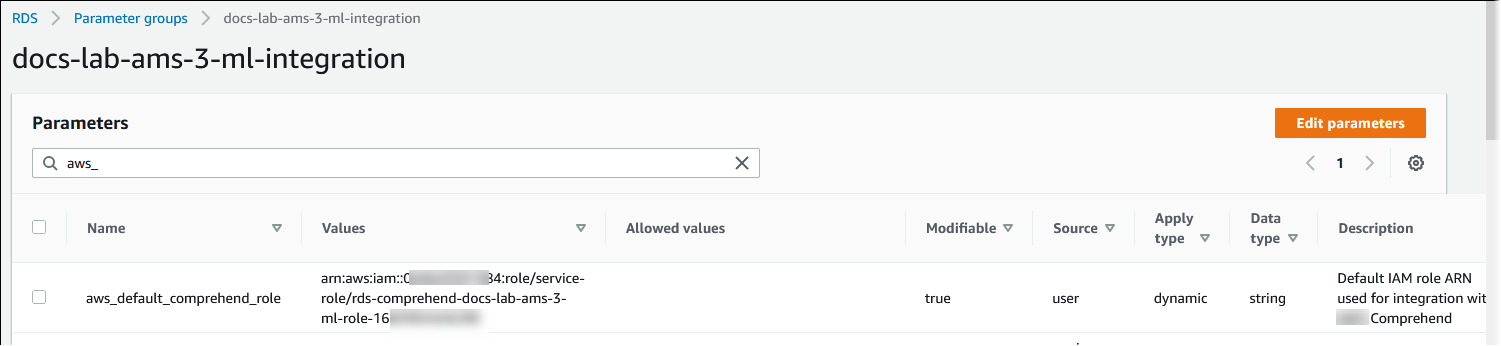
在自定义数据库集群参数组中找到
aws_default_comprehend_role参数。在值字段中,输入 IAM 角色的 ARN。
选择 Save changes(保存更改)以保存设置。在下图中,您可以找到一个示例。
重启 Aurora MySQL 数据库集群的主实例,以使此参数设置生效。
Amazon Comprehend 的 IAM 集成已完成。通过向相应的数据库用户授予访问权限,继续设置 Aurora MySQL 数据库集群以与 Amazon Comprehend 结合使用。
设置 Aurora MySQL 数据库集群以使用 SageMaker AI
以下过程会自动为 Aurora MySQL 数据库集群创建 IAM 角色和策略,以便它可以使用 SageMaker AI。在尝试执行此过程之前,请确保您有 SageMaker AI 端点可用,以便在需要时输入该端点。通常,团队中的数据科学家会努力生成一个可以从 Aurora MySQL 数据库集群使用的端点。您可以在 SageMaker AI 控制台

设置 Aurora MySQL 数据库集群以使用 SageMaker AI
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
从 Amazon RDS 导航菜单中选择数据库,然后选择要连接到 SageMaker AI 服务的 Aurora MySQL 数据库集群。
-
选择连接和安全性选项卡。
-
滚动至 Manage IAM roles(管理 IAM 角色)部分,然后选择 Select a service to connect to this cluster(选择一个服务以连接到此集群)。从选择器中选择 SageMaker AI。
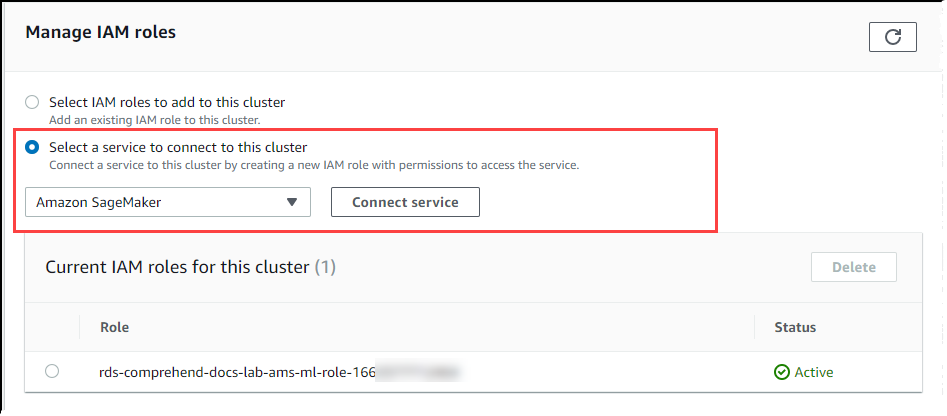
选择连接服务。
在将集群连接到 SageMaker AI 对话框中,输入 SageMaker AI 端点的 ARN。
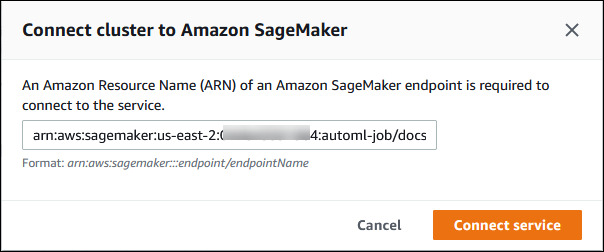
-
Aurora 创建 IAM 角色。它还创建允许 Aurora MySQL 数据库集群使用 SageMaker AI 服务的策略,并将该策略附加到角色。该过程完成后,您可以在当前该集群的 IAM 角色列表中找到该角色。
通过 https://console.aws.amazon.com/iam/
打开 IAM 控制台。 从 Amazon Identity and Access Management 导航菜单的 Access management(访问管理)部分中选择 Roles(角色)。
从列出的角色中找到该角色。其名称使用以下模式。
rds-sagemaker-your-cluster-name-role-auto-generated-digits打开角色的 Summary(摘要)页面并找到 ARN。记下 ARN 或使用复制小组件复制它。
通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 选择您的 Aurora MySQL 数据库集群,然后选择其 Configuration(配置)选项卡。
找到数据库集群参数组,然后选择链接以打开自定义数据库集群参数组。找到
aws_default_sagemaker_role参数并在 Value(值)字段中输入 IAM 角色的 ARN,然后保存设置。重启 Aurora MySQL 数据库集群的主实例,以使此参数设置生效。
IAM 设置现已完成。通过向相应的数据库用户授予访问权限,继续设置 Aurora MySQL 数据库集群以与 SageMaker AI 结合使用。
如果您想使用您的 SageMaker AI 模型进行训练,而不是使用预构建的 SageMaker AI 组件,则还需要将 Amazon S3 存储桶添加到您的 Aurora MySQL 数据库集群中,如下文的 设置 Aurora MySQL 数据库集群以将 Amazon S3 用于 SageMaker AI(可选) 中所述。
设置 Aurora MySQL 数据库集群以将 Amazon S3 用于 SageMaker AI(可选)
要将 SageMaker AI 用于您自己的模型,而不是使用 SageMaker AI 提供的预构建组件,您需要为 Aurora MySQL 数据库集群设置一个 Amazon S3 存储桶以供使用。有关创建 Amazon S3 存储桶的更多信息,请参阅 Amazon Simple Storage Service 用户指南中的创建存储桶。
设置 Aurora MySQL 数据库集群以将 Amazon S3 存储桶用于 SageMaker AI
登录 Amazon Web Services 管理控制台 并通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 -
从 Amazon RDS 导航菜单中选择数据库,然后选择要连接到 SageMaker AI 服务的 Aurora MySQL 数据库集群。
-
选择连接和安全性选项卡。
-
滚动至 Manage IAM roles(管理 IAM 角色)部分,然后选择 Select a service to connect to this cluster(选择一个服务以连接到此集群)。从选择器中选择 Amazon S3。

选择连接服务。
在将集群连接到 Amazon S3 对话框中,输入 Amazon S3 存储桶的 ARN,如下图所示。
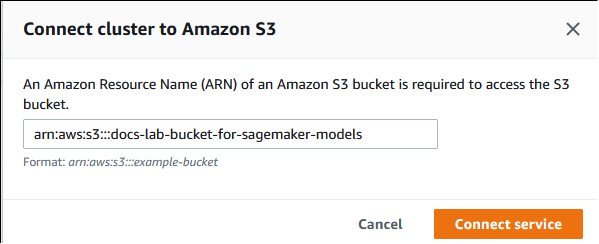
选择 Connect service(连接服务)以完成此过程。
有关将 Amazon S3 存储桶与 SageMaker AI 结合使用的更多信息,请参阅《Amazon SageMaker AI 开发人员指南》中的 Specify an Amazon S3 Bucket to Upload Training Datasets and Store Output Data。要了解有关使用 SageMaker AI 的更多信息,请参阅《Amazon SageMaker AI 开发人员指南》中的 Get Started with Amazon SageMaker AI Notebook Instances。
授予数据库用户访问 Aurora 机器学习的权限
必须向数据库用户授予调用 Aurora 机器学习函数的权限。授予权限的方式取决于您用于 Aurora MySQL 数据库集群的 MySQL 版本,如下所述。如何操作取决于您的 Aurora MySQL 数据库集群使用的 MySQL 版本。
对于 Aurora MySQL 版本 3(与 MySQL 8.0 兼容),必须向数据库用户授予相应的数据库角色。有关更多信息,请参阅《MySQL 8.0 参考手册》中的 Using Roles
。 对于 Aurora MySQL 版本 2(与 MySQL 5.7 兼容),向数据库用户授予权限。有关更多信息,请参阅《MySQL 5.7 参考手册》中的 Access Control and Account Management
。
下表显示了数据库用户使用机器学习函数所需的角色和权限。
| Aurora MySQL 版本 3(角色) | Aurora MySQL 版本 2(权限) |
|---|---|
|
Amazon_BEDROCK_ACCESS |
– |
|
Amazon_COMPREHEND_ACCESS |
INVOKE COMPREHEND |
|
Amazon_SAGEMAKER_ACCESS |
INVOKE SAGEMAKER |
授予对 Amazon Bedrock 函数的访问权限
要向数据库用户授予对 Amazon Bedrock 函数的访问权限,请使用以下 SQL 语句:
GRANT Amazon_BEDROCK_ACCESS TOuser@domain-or-ip-address;
对于您为使用 Amazon Bedrock 而创建的函数,还需要向数据库用户授予 EXECUTE 权限。
GRANT EXECUTE ON FUNCTIONdatabase_name.function_nameTOuser@domain-or-ip-address;
最后,数据库用户必须将其角色设置为 Amazon_BEDROCK_ACCESS:
SET ROLE Amazon_BEDROCK_ACCESS;
Amazon Bedrock 函数现已可供使用。
授予对 Amazon Comprehend 函数的访问权限
要向数据库用户授予对 Amazon Comprehend 函数的访问权限,请使用适用于您的 Aurora MySQL 版本的相应语句。
Aurora MySQL 版本 3(与 MySQL 8.0 兼容)
GRANT Amazon_COMPREHEND_ACCESS TOuser@domain-or-ip-address;Aurora MySQL 版本 2(与 MySQL 5.7 兼容)
GRANT INVOKE COMPREHEND ON *.* TOuser@domain-or-ip-address;
Amazon Comprehend 函数现已可供使用。有关使用示例,请参阅 将 Amazon Comprehend 与 Aurora MySQL 数据库集群结合使用。
授予对 SageMaker AI 函数的访问权限
要向数据库用户授予对 SageMaker AI 函数的访问权限,请使用适用于您的 Aurora MySQL 版本的相应语句。
Aurora MySQL 版本 3(与 MySQL 8.0 兼容)
GRANT Amazon_SAGEMAKER_ACCESS TOuser@domain-or-ip-address;Aurora MySQL 版本 2(与 MySQL 5.7 兼容)
GRANT INVOKE SAGEMAKER ON *.* TOuser@domain-or-ip-address;
对于您为使用 SageMaker AI 而创建的函数,还需要向数据库用户授予 EXECUTE 权限。假设您创建了两个函数 db1.anomoly_score 和 db2.company_forecasts 以调用 SageMaker AI 端点的服务。您应授予执行权限,如以下示例所示。
GRANT EXECUTE ON FUNCTION db1.anomaly_score TOuser1@domain-or-ip-address1; GRANT EXECUTE ON FUNCTION db2.company_forecasts TOuser2@domain-or-ip-address2;
SageMaker AI 函数现已可供使用。有关使用示例,请参阅 将 SageMaker AI 与 Aurora MySQL 数据库集群结合使用。
将 Amazon Bedrock 与 Aurora MySQL 数据库集群结合使用
要使用 Amazon Bedrock,您需要在 Aurora MySQL 数据库中创建一个调用模型的用户定义函数(UDF)。有关更多信息,请参阅《Amazon Bedrock 用户指南》中的 Supported models in Amazon Bedrock。
UDF 使用以下语法:
CREATE FUNCTIONfunction_name(argumenttype) [DEFINER = user] RETURNSmysql_data_type[SQL SECURITY {DEFINER | INVOKER}] ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'model_id' [CONTENT_TYPE 'content_type'] [ACCEPT 'content_type'] [TIMEOUT_MStimeout_in_milliseconds];
-
Amazon Bedrock 函数不支持
RETURNS JSON。如果需要,您可以使用CONVERT或CAST从TEXT转换为JSON。 -
如果您未指定
CONTENT_TYPE或ACCEPT,则默认值为application/json。 -
如果您未指定
TIMEOUT_MS,则使用aurora_ml_inference_timeout的值。
例如,以下 UDF 调用 Amazon Titan Text Express 模型:
CREATE FUNCTION invoke_titan (request_body TEXT) RETURNS TEXT ALIAS AWS_BEDROCK_INVOKE_MODEL MODEL ID 'amazon.titan-text-express-v1' CONTENT_TYPE 'application/json' ACCEPT 'application/json';
要允许数据库用户使用此函数,请使用以下 SQL 命令:
GRANT EXECUTE ON FUNCTIONdatabase_name.invoke_titan TOuser@domain-or-ip-address;
然后,用户会像调用任何其它函数一样调用 invoke_titan,如以下示例所示。请务必根据 Amazon Titan 文本模型格式化请求正文。
CREATE TABLE prompts (request varchar(1024)); INSERT INTO prompts VALUES ( '{ "inputText": "Generate synthetic data for daily product sales in various categories - include row number, product name, category, date of sale and price. Produce output in JSON format. Count records and ensure there are no more than 5.", "textGenerationConfig": { "maxTokenCount": 1024, "stopSequences": [], "temperature":0, "topP":1 } }'); SELECT invoke_titan(request) FROM prompts; {"inputTextTokenCount":44,"results":[{"tokenCount":296,"outputText":" ```tabular-data-json { "rows": [ { "Row Number": "1", "Product Name": "T-Shirt", "Category": "Clothing", "Date of Sale": "2024-01-01", "Price": "$20" }, { "Row Number": "2", "Product Name": "Jeans", "Category": "Clothing", "Date of Sale": "2024-01-02", "Price": "$30" }, { "Row Number": "3", "Product Name": "Hat", "Category": "Accessories", "Date of Sale": "2024-01-03", "Price": "$15" }, { "Row Number": "4", "Product Name": "Watch", "Category": "Accessories", "Date of Sale": "2024-01-04", "Price": "$40" }, { "Row Number": "5", "Product Name": "Phone Case", "Category": "Accessories", "Date of Sale": "2024-01-05", "Price": "$25" } ] } ```","completionReason":"FINISH"}]}
对于您使用的其它模型,请确保相应地为其格式化请求正文。有关更多信息,请参阅《Amazon Bedrock 用户指南》中的 Inference parameters for foundation models。
将 Amazon Comprehend 与 Aurora MySQL 数据库集群结合使用
对于 Aurora MySQL,Aurora 机器学习提供了以下两个内置函数,用于处理 Amazon Comprehend 和您的文本数据。您提供要分析的文本(input_data)并指定语言(language_code)。
- aws_comprehend_detect_sentiment
-
此函数将文本识别为具有积极、消极、中立或混合的情绪姿态。此函数的参考文档如下所示。
aws_comprehend_detect_sentiment( input_text, language_code [,max_batch_size] )要了解更多信息,请参阅《Amazon Comprehend 开发人员指南》中的情绪。
- aws_comprehend_detect_sentiment_confidence
-
此函数衡量针对给定文本检测到的情绪的置信度。它返回一个值(类型为
double),该值表示 aws_comprehend_detect_sentiment 函数分配给文本的情绪的置信度。置信度是介于 0 和 1 之间的统计指标。置信度越高,可给予结果的权重越大。该函数的文档摘要如下所示。aws_comprehend_detect_sentiment_confidence( input_text, language_code [,max_batch_size] )
在两个函数(aws_comprehend_detect_sentiment_confidence、aws_comprehend_detect_sentiment)中,如果未指定值,则 max_batch_size 使用默认值 25。批处理大小应始终大于 0。您可以使用 max_batch_size 优化 Amazon Comprehend 函数调用的性能。较大的批处理大小为了提高 Aurora MySQL 数据库集群上的内存使用率而牺牲更快的性能。有关更多信息,请参阅 将 Aurora 机器学习与 Aurora MySQL 结合使用的性能注意事项。
有关 Amazon Comprehend 中情绪检测函数的参数和返回类型的更多信息,请参阅 DetectSentiment
例示例:使用 Amazon Comprehend 函数的简单查询
以下是一个简单查询的示例,它调用了这两个函数,以查看您的客户对您的支持团队的满意程度。假设您有一个数据库表(support),该表存储每次请求帮助后的客户反馈。此示例查询将这两个内置函数应用于表的 feedback 列中的文本,并输出结果。函数返回的置信度值是介于 0.0 和 1.0 之间的双精度(double)值。为了获得更具可读性的输出,此查询将结果四舍五入到 6 个小数点。为了便于比较,此查询还按降序对结果进行排序,首先从置信度最高的结果开始。
SELECT feedback AS 'Customer feedback', aws_comprehend_detect_sentiment(feedback, 'en') AS Sentiment, ROUND(aws_comprehend_detect_sentiment_confidence(feedback, 'en'), 6) AS Confidence FROM support ORDER BY Confidence DESC;+----------------------------------------------------------+-----------+------------+ | Customer feedback | Sentiment | Confidence | +----------------------------------------------------------+-----------+------------+ | Thank you for the excellent customer support! | POSITIVE | 0.999771 | | The latest version of this product stinks! | NEGATIVE | 0.999184 | | Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 | | Your product is too complex, but your support is great. | MIXED | 0.957958 | | Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 | | My problem was never resolved! | NEGATIVE | 0.920644 | | When will the new version of this product be released? | NEUTRAL | 0.902706 | | I cannot stand that chatbot. | NEGATIVE | 0.895219 | | Your support tech talked down to me. | NEGATIVE | 0.868598 | | It took me way too long to get a real person. | NEGATIVE | 0.481805 | +----------------------------------------------------------+-----------+------------+ 10 rows in set (0.1898 sec)
例示例:确定高于特定置信度的文本的平均情绪
典型的 Amazon Comprehend 查询会查找情绪为特定值且置信度大于特定数字的行。例如,以下查询显示了如何确定数据库中文档的平均情绪。该查询只考虑评估的置信度至少为 80% 的文档。
SELECT AVG(CASE aws_comprehend_detect_sentiment(productTable.document, 'en') WHEN 'POSITIVE' THEN 1.0 WHEN 'NEGATIVE' THEN -1.0 ELSE 0.0 END) AS avg_sentiment, COUNT(*) AS total FROM productTable WHERE productTable.productCode = 1302 AND aws_comprehend_detect_sentiment_confidence(productTable.document, 'en') >= 0.80;
将 SageMaker AI 与 Aurora MySQL 数据库集群结合使用
要从 Aurora MySQL 数据库集群中使用 SageMaker AI 功能,您需要创建存储函数,以嵌入对 SageMaker AI 端点的调用及其推理功能。为此,您可以使用 MySQL 的 CREATE FUNCTION,其方式与您在 Aurora MySQL 数据库集群上执行其他处理任务的方式大致相同。
要使用 SageMaker AI 中部署的模型进行推理,请使用 MySQL 数据定义语言(DDL)语句为存储函数创建用户定义的函数。每个存储函数表示托管模型的 SageMaker AI 端点。定义此类函数时,请指定模型的输入参数、要调用的特定 SageMaker AI 端点以及返回类型。该函数在对输入参数应用模型后,将返回由 SageMaker AI 端点计算的推理。
所有 Aurora 机器学习存储函数均返回数字类型或 VARCHAR。您可以使用除 BIT 以外的任何数字类型。不允许使用其他类型,例如 JSON、BLOB、TEXT 和 DATE。
以下示例显示与 SageMaker AI 结合使用的 CREATE FUNCTION 语法。
CREATE FUNCTION function_name (
arg1 type1,
arg2 type2, ...)
[DEFINER = user]
RETURNS mysql_type
[SQL SECURITY { DEFINER | INVOKER } ]
ALIAS Amazon_SAGEMAKER_INVOKE_ENDPOINT
ENDPOINT NAME 'endpoint_name'
[MAX_BATCH_SIZE max_batch_size];
这是常规 CREATE FUNCTION DDL 语句的扩展。在定义 SageMaker AI 函数的 CREATE FUNCTION 语句中,不要指定函数体。而是要指定函数体通常所在的关键字 ALIAS。目前,Aurora 机器学习只支持 aws_sagemaker_invoke_endpoint 使用这种扩展语法。您还必须指定 endpoint_name 参数。每个模型的 SageMaker AI 端点可以具有不同的特性。
注意
有关 CREATE FUNCTION 的更多信息,请参阅《MySQL 8.0 参考手册》中的 CREATE PROCEDURE 和 CREATE FUNCTION 语句
max_batch_size 参数是可选的。默认情况下,最大批处理大小为 10000。您可以在函数中使用此参数来限制针对 SageMaker AI 的批处理请求中处理的最大输入数。max_batch_size 参数可以帮助避免因输入过大而导致的错误,或者使 SageMaker AI 更快地返回响应。此参数影响用于 SageMaker AI 请求处理的内部缓冲区的大小。为 max_batch_size 指定太大的值可能会导致数据库实例产生大量内存开销。
建议您将 MANIFEST 设置保留为其默认值 OFF。尽管可以使用 MANIFEST ON 选项,但某些 SageMaker AI 功能无法直接使用通过此选项导出的 CSV。清单格式与 SageMaker AI 预期的清单格式不兼容。
您为每个 SageMaker AI 模型创建一个单独的存储函数。需要将函数映射到模型,因为终端节点与特定的模型关联,并且每个模型接受的参数不同。将 SQL 类型用于模型输入和模型输出类型有助于避免在 Amazon 服务之间来回传递数据时出现类型转换错误。您可以控制谁可以应用模型。也可以通过指定表示最大批处理大小的参数来控制运行时特性。
目前,所有 Aurora 机器学习函数都具有 NOT DETERMINISTIC 属性。如果您未明确指定该属性,Aurora 会自动设置 NOT DETERMINISTIC。提出这一要求是因为可以在不向数据库发出任何通知的情况下更改 SageMaker AI 模型。如果发生这种情况,则调用 Aurora 机器学习函数可能会在单个事务中针对同一输入返回不同的结果。
不能在 CONTAINS SQL 语句中使用特性 NO SQL、READS SQL DATA、MODIFIES SQL DATA 或 CREATE
FUNCTION。
下面是调用 SageMaker AI 端点来检测异常的示例用法。这里有一个 SageMaker AI 端点 random-cut-forest-model。random-cut-forest 算法已对相应的模型进行了训练。对于每个输入,模型都会返回一个异常分数。本例显示了分数比平均分数大 3 个标准偏差(大约为 99.9%)的数据点。
CREATE FUNCTION anomaly_score(value real) returns real
alias aws_sagemaker_invoke_endpoint endpoint name 'random-cut-forest-model-demo';
set @score_cutoff = (select avg(anomaly_score(value)) + 3 * std(anomaly_score(value)) from nyc_taxi);
select *, anomaly_detection(value) score from nyc_taxi
where anomaly_detection(value) > @score_cutoff;
返回字符串的 SageMaker AI 函数的字符集要求
建议为返回字符串值的 SageMaker AI 函数指定一个字符集 utf8mb4 作为返回类型。如果这不切实际,则为返回类型使用足够大的字符串长度,以容纳以 utf8mb4 字符集表示的值。下面的示例展示了如何为您的函数声明 utf8mb4 字符集。
CREATE FUNCTION my_ml_func(...) RETURNS VARCHAR(5) CHARSET utf8mb4 ALIAS ...目前,每个返回字符串的 SageMaker AI 函数都使用字符集 utf8mb4 作为返回值。返回值仍使用此字符集,即使您的 SageMaker AI 函数为其返回类型隐式或显式声明了不同的字符集,也是如此。如果 SageMaker AI 函数为返回值声明了不同的字符集,那么如果将返回的数据存储在不够长的表列中,则该数据可能会被无提示截断。例如,带有 DISTINCT 子句的查询将创建一个临时表。因此,由于查询期间在内部处理字符串的方式,SageMaker AI 函数结果可能会被截断。
将数据导出到 Amazon S3 以进行 SageMaker AI 模型训练(高级)
建议您使用提供的一些算法开始使用 Aurora 机器学习和 SageMaker AI,并建议您团队中的数据科学家为您提供可与 SQL 代码结合使用的 SageMaker AI 端点。在下文中,您可以找到有关将自己的 Amazon S3 存储桶与自己的 SageMaker AI 模型和 Aurora MySQL 数据库集群结合使用的极少量信息。
机器学习包括两个主要步骤:训练和推理。要训练 SageMaker AI 模型,请将数据导出到 Amazon S3 存储桶。Jupyter SageMaker AI 笔记本实例使用 Amazon S3 存储桶在部署模型之前对其进行训练。您可以使用 SELECT INTO OUTFILE S3 语句从 Aurora MySQL 数据库集群中查询数据,并将数据直接保存到 Amazon S3 存储桶中存储的文本文件。然后,笔记本实例将使用 Amazon S3 存储桶中的数据进行训练。
Aurora 机器学习将扩展 Aurora MySQL 中现有的 SELECT INTO OUTFILE 语法,以将数据导出为 CSV 格式。需要此格式的模型可以直接使用生成的 CSV 文件进行训练。
SELECT * INTO OUTFILE S3 's3_uri' [FORMAT {CSV|TEXT} [HEADER]] FROM table_name;该扩展支持标准 CSV 格式。
-
格式
TEXT与现有的 MySQL 导出格式相同。这是默认格式。 -
格式
CSV是一种新引入的格式,遵循 RFC-4180中的规范。 -
如果指定可选关键字
HEADER,则输出文件包含一个标题行。标题行中的标签与SELECT语句中的列名称相对应。 -
您仍可使用关键字
CSV和HEADER作为标识符。
现在,SELECT INTO 的扩展句法和语法如下:
INTO OUTFILE S3 's3_uri'
[CHARACTER SET charset_name]
[FORMAT {CSV|TEXT} [HEADER]]
[{FIELDS | COLUMNS}
[TERMINATED BY 'string']
[[OPTIONALLY] ENCLOSED BY 'char']
[ESCAPED BY 'char']
]
[LINES
[STARTING BY 'string']
[TERMINATED BY 'string']
]
将 Aurora 机器学习与 Aurora MySQL 结合使用的性能注意事项
Amazon Bedrock、Amazon Comprehend 和 SageMaker AI 服务在由 Aurora 机器学习函数调用时会完成大部分工作。这意味着您可以根据需要独立扩缩这些资源。对于您的 Aurora MySQL 数据库集群,您可以使函数调用尽可能高效。接下来,您可以找到使用 Aurora 机器学习时需要注意的一些性能注意事项。
模型和提示
使用 Amazon Bedrock 时的性能在很大程度上取决于您使用的模型和提示。选择最适合您的使用案例的模型和提示。
查询缓存
Aurora MySQL 查询缓存对 Aurora 机器学习函数无效。对于任何调用 Aurora 机器学习函数的 SQL 语句,Aurora MySQL 不会将查询结果存储到查询缓存中。
Aurora 机器学习函数调用的批处理优化
您可以从 Aurora 集群影响 Aurora 机器学习性能的主要方面是针对 Aurora 机器学习存储函数调用的批处理模式设置。机器学习函数通常需要大量开销,因此,分别为每行内容调用外部服务是不切实际的。Aurora 机器学习可以通过将为多行内容进行的外部 Aurora 机器学习服务调用合并为同一批次,来尽可能减少此类开销。Aurora 机器学习将接收对输入行的所有响应,同时在查询运行时以一次一行的形式将响应传回给查询。这种优化可提高 Aurora 查询的吞吐量并减少延迟,而不会改变结果。
创建连接到 SageMaker AI 端点的 Aurora 存储函数时,需要定义批处理大小参数。该参数影响每个对 SageMaker AI 的基础调用所传输的行数。对于处理大量行的查询,为每一行单独进行 SageMaker AI 调用的开销可能很大。存储过程处理的数据集越大,批处理大小就可以越大。
如果批处理模式优化可以应用于 SageMaker AI 函数,您可以通过查看 EXPLAIN PLAN 语句生成的查询计划来确定。在本例中,执行计划中的 extra 列包括 Batched machine learning。以下示例显示了对使用批处理模式的 SageMaker AI 函数的调用。
mysql> CREATE FUNCTION anomaly_score(val real) returns real alias aws_sagemaker_invoke_endpoint endpoint name 'my-rcf-model-20191126';
Query OK, 0 rows affected (0.01 sec)
mysql> explain select timestamp, value, anomaly_score(value) from nyc_taxi;
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
| 1 | SIMPLE | nyc_taxi | NULL | ALL | NULL | NULL | NULL | NULL | 48 | 100.00 | Batched machine learning |
+----+-------------+----------+------------+------+---------------+------+---------+------+------+----------+--------------------------+
1 row in set, 1 warning (0.01 sec)
调用内置 Amazon Comprehend 函数之一时,可通过指定可选的 max_batch_size 参数来控制批处理大小。该参数限制每个批次中处理的 input_text 值的最大数。通过一次发送多个项目,减少了 Aurora 和 Amazon Comprehend 之间的往返次数。在使用 LIMIT 子句的查询等情况下,限制批处理大小非常有用。通过使用一个较小的 max_batch_size 值,可以避免调用 Amazon Comprehend 的次数超过输入文本的次数。
用于评估 Aurora 机器学习函数的批处理优化适用于以下情况:
-
选择列表或
SELECT语句的WHERE子句中的函数调用 -
INSERT和REPLACE语句的VALUES列表中的函数调用 -
UPDATE语句的SET值中的 SageMaker AI 函数:INSERT INTO MY_TABLE (col1, col2, col3) VALUES (ML_FUNC(1), ML_FUNC(2), ML_FUNC(3)), (ML_FUNC(4), ML_FUNC(5), ML_FUNC(6)); UPDATE MY_TABLE SET col1 = ML_FUNC(col2), SET col3 = ML_FUNC(col4) WHERE ...;
监控 Aurora 机器学习
您可以通过查询多个全局变量来监控 Aurora 机器学习批量操作,如以下示例所示。
show status like 'Aurora_ml%';
可以使用 FLUSH STATUS 语句重置状态变量。因此,自上次重置变量以来,所有数字均表示总计、平均值等。
Aurora_ml_logical_request_cnt-
自上次状态重置以来,数据库实例评估的要发送到 Aurora 机器学习服务的逻辑请求数。根据是否使用了批处理,此值可能高于
Aurora_ml_actual_request_cnt。 Aurora_ml_logical_response_cnt-
在数据库实例用户运行的所有查询中,Aurora MySQL 从 Aurora 机器学习服务接收的响应次数总计。
Aurora_ml_actual_request_cnt-
在数据库实例用户运行的所有查询中,Aurora MySQL 对 Aurora 机器学习服务发出的请求次数总计。
Aurora_ml_actual_response_cnt-
在数据库实例用户运行的所有查询中,Aurora MySQL 从 Aurora 机器学习服务接收的响应次数总计。
Aurora_ml_cache_hit_cnt-
在数据库实例用户运行的所有查询中,Aurora MySQL 从 Aurora 机器学习服务接收的内部缓存命中次数总计。
Aurora_ml_retry_request_cnt-
自上次状态重置以来,数据库实例已向 Aurora 机器学习服务发送的重试请求数。
Aurora_ml_single_request_cnt-
在数据库实例用户运行的所有查询中,非批处理模式评估的 Aurora 机器学习函数总计。
有关监控从 Aurora 机器学习函数调用的 SageMaker AI 操作的性能的信息,请参阅 Monitor Amazon SageMaker AI。