将 Amazon Aurora 机器学习与 Aurora PostgreSQL 结合使用
通过将 Amazon Aurora 机器学习与您的 Aurora PostgreSQL 数据库集群结合使用,您可以根据需要使用 Amazon Comprehend、Amazon SageMaker AI 或 Amazon Bedrock。这些服务各自支持特定的机器学习使用案例。
只有某些 Amazon Web Services 区域 和特定版本的 Aurora PostgreSQL 才支持 Aurora 机器学习。在尝试设置 Aurora 机器学习之前,请检查您的 Aurora PostgreSQL 版本和区域的可用性。有关更多信息,请参阅 使用 Aurora PostgreSQL 的 Aurora 机器学习。
主题
将 Aurora 机器学习与 Aurora PostgreSQL 结合使用的要求
Amazon 机器学习服务是在其自己的生产环境中设置和运行的托管式服务。Aurora 机器学习支持与 Amazon Comprehend、SageMaker AI 和 Amazon Bedrock 相集成。在尝试将 Aurora PostgreSQL 数据库集群设置为使用 Aurora 机器学习之前,请务必了解以下要求和先决条件。
Amazon Comprehend、SageMaker AI 和 Amazon Bedrock 服务必须与您的 Aurora PostgreSQL 数据库集群在相同的 Amazon Web Services 区域中运行。您不能在不同区域的 Aurora PostgreSQL 数据库集群中使用 Amazon Comprehend、SageMaker AI 或 Amazon Bedrock 服务。
如果 Aurora PostgreSQL 数据库集群与 Amazon Comprehend 和 SageMaker AI 服务位于不同的基于 Amazon VPC 服务的虚拟公有云(VPC)中,则 VPC 的安全组需要允许与目标 Aurora 机器学习服务的出站连接。有关更多信息,请参阅 启用从 Amazon Aurora 到其它 Amazon 服务的网络通信。
对于 SageMaker AI,您要用于推理的机器学习组件必须设置好并准备就绪。在配置 Aurora PostgreSQL 数据库集群的过程中,您需要具有 SageMaker AI 端点的 Amazon 资源名称(ARN)。您团队中的数据科学家可能最有能力使用 SageMaker AI,以准备模型并处理其他此类任务。要开始使用 Amazon SageMaker AI,请参阅 Get Started with Amazon SageMaker AI。有关推理和端点的更多信息,请参阅实时推理。
-
对于 Amazon Bedrock,您需要在 Aurora PostgreSQL 数据库集群配置过程中提供要用于推理的 Bedrock 模型的模型 ID。您团队中的数据科学家可能最有能力与 Bedrock 合作,以决定使用哪些模型,在需要时对其进行微调,并处理其他此类任务。要开始使用 Amazon Bedrock,请参阅 How to setup Bedrock。
-
Amazon Bedrock 用户需要先请求模型访问权限,然后才能使用模型。如果您想要添加其他文本、聊天和图像生成模型,则需要在 Amazon Bedrock 中请求模型访问权限。有关更多信息,请参阅模型访问。
Aurora 机器学习与 Aurora PostgreSQL 结合使用时支持的功能和限制
Aurora 机器学习通过 ContentType 的 text/csv 值支持任何可读取和写入逗号分隔值(CSV)格式的 SageMaker AI 端点。目前接受此格式的内置 SageMaker AI 算法有以下几种。
线性学习器
Random Cut Forest
XGBoost
要了解有关这些算法的更多信息,请参阅《Amazon SageMaker AI 开发人员指南》中的 Choose an Algorithm。
将 Amazon Bedrock 与 Aurora 机器学习结合使用时,以下限制适用:
-
用户定义函数(UDF)提供了与 Amazon Bedrock 交互的原生方式。UDF 没有特定的请求或响应要求,因此它们可以使用任何模型。
-
您可以使用 UDF 来构建所需的任何工作流程。例如,您可以组合基本基元(例如
pg_cron)来运行查询、提取数据、生成推理以及写入表以直接提供查询。 -
UDF 不支持批处理调用或并行调用。
-
Aurora 机器学习扩展不支持向量接口。作为扩展的一部分,可以使用函数以
float8[]格式输出模型响应的嵌入内容,以将这些嵌入内容存储在 Aurora 中。有关使用float8[]的更多信息,请参阅将 Amazon Bedrock 与 Aurora PostgreSQL 数据库集群结合使用。
设置 Aurora PostgreSQL 数据库集群以使用 Aurora 机器学习
要让 Aurora 机器学习与您的 Aurora PostgreSQL 数据库集群结合使用,您需要为您要使用的每项服务创建一个 Amazon Identity and Access Management(IAM)角色。IAM 角色允许您的 Aurora PostgreSQL 数据库集群代表集群使用 Aurora 机器学习服务。您还需要安装 Aurora 机器学习扩展。在以下主题中,您可以找到其中每个 Aurora 机器学习服务的设置过程。
主题
设置 Aurora PostgreSQL 以使用 Amazon Bedrock
在接下来的过程中,您首先创建 IAM 角色和策略,它们授予 Aurora PostgreSQL 代表集群使用 Amazon Bedrock 的权限。然后,您将策略附加到 Aurora PostgreSQL 数据库集群用来与 Amazon Bedrock 结合使用的 IAM 角色。为简单起见,此过程使用 Amazon Web Services 管理控制台 来完成所有任务。
设置 Aurora PostgreSQL 数据库集群以使用 Amazon Bedrock
登录 Amazon Web Services 管理控制台,然后通过以下网址打开 IAM 控制台:https://console.aws.amazon.com/iam/
。 通过 https://console.aws.amazon.com/iam/
打开 IAM 控制台。 在 Amazon Identity and Access Management(IAM)控制台菜单上选择 Policies(策略)[在 Access management(访问管理)下]。
选择创建策略。在可视化编辑器页面中,选择服务,然后在“选择服务”字段中输入 Bedrock。展开读取访问权限级别。从 Amazon Bedrock 读取设置中选择 InvokeModel。
选择要通过策略授予读取权限的根基/预调配模型。
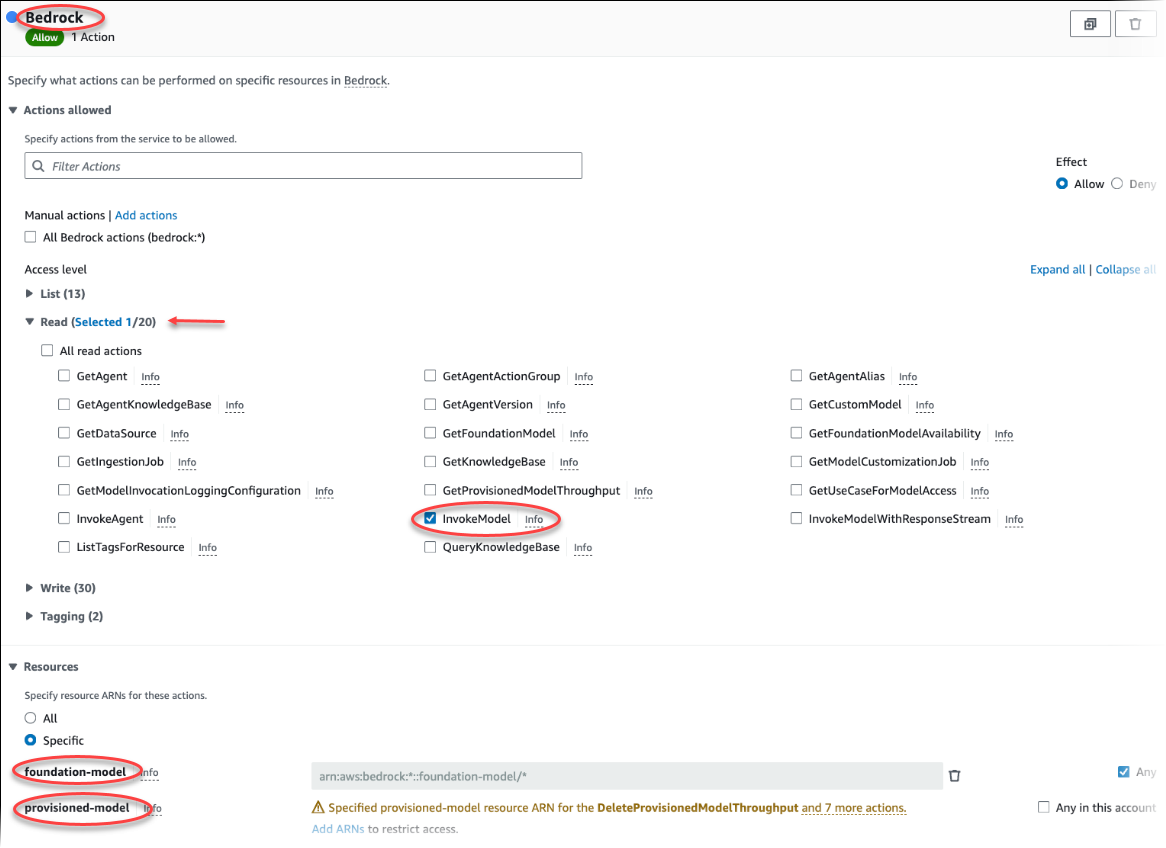
选择 Next: Tags(下一步:标签)并定义任何标签(这是可选的)。选择下一步:审核。输入策略的名称和说明,如图中所示。
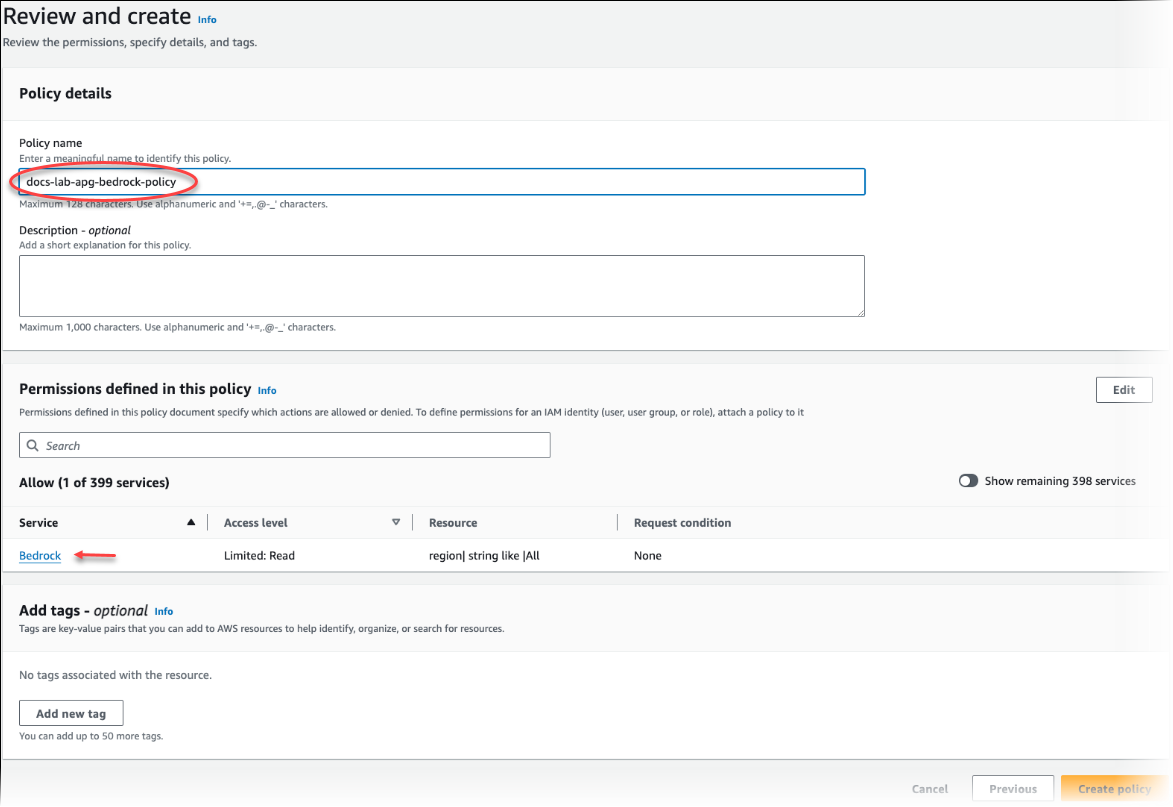
选择创建策略。保存策略后,控制台会显示提示。您可以在 Policies(策略)列表中找到它。
在 IAM 控制台上选择 Roles(角色)[在 Access management(访问管理)下]。
选择创建角色。
在“选择可信实体”页面上,选择 Amazon 服务磁贴,然后选择 RDS 以打开选择器。
选择 RDS – Add Role to Database(RDS – 将角色添加到数据库)。
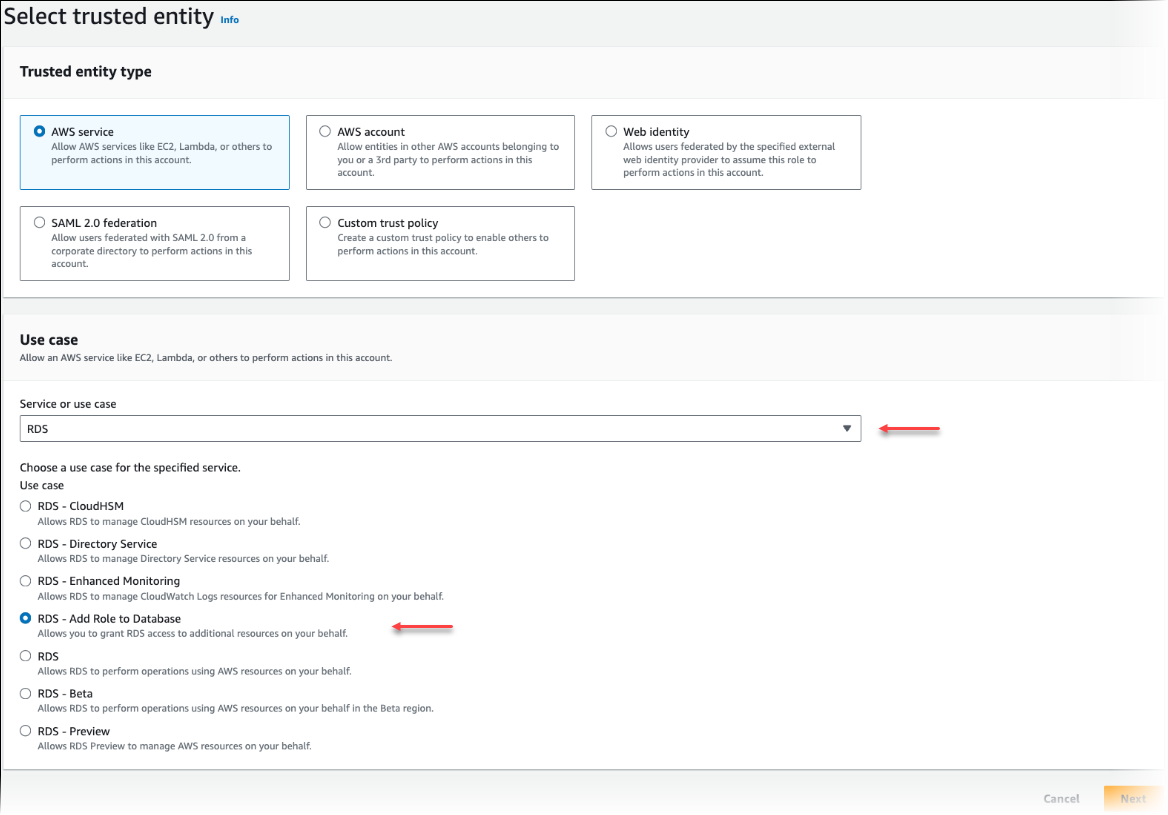
选择下一步。在 Add permissions(添加权限)页面上,找到您在上一步中创建的策略,并从列出的策略中选择此策略。选择下一步。
Next: Review(下一步:审核)。输入 IAM 角色的名称和说明。
通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 导航到 Aurora PostgreSQL 数据库集群所在的 Amazon Web Services 区域。
-
在导航窗格中,选择数据库,然后选择要与 Bedrock 结合使用的 Aurora PostgreSQL 数据库集群。
-
选择 Connectivity & security(连接和安全性)选项卡,然后滚动以找到该页面的 Manage IAM roles(管理 IAM 角色)部分。从 Add IAM roles to this cluster(将 IAM 角色添加到此集群)选择器中,选择您在前面的步骤中创建的角色。在功能选择器中,选择 Bedrock,然后选择添加角色。
该角色(及其策略)与 Aurora PostgreSQL 数据库集群相关联。该过程完成后,该角色将在 Current IAM roles for this cluster(此集群的当前 IAM 角色)列表中列出,如下所示。
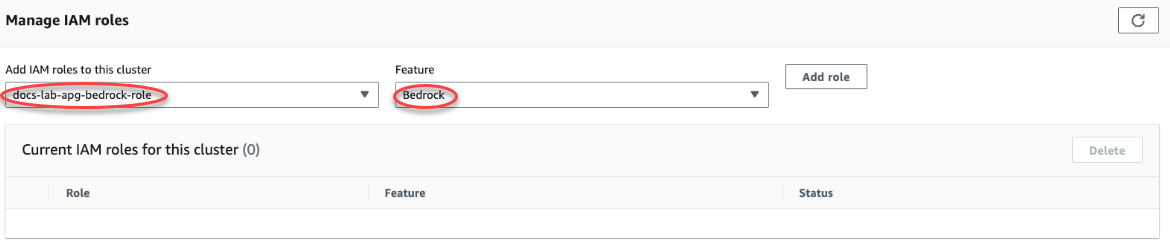
Amazon Bedrock 的 IAM 设置已完成。通过安装扩展继续设置 Aurora PostgreSQL 以使用 Aurora 机器学习,详见 安装 Aurora 机器学习扩展。
设置 Aurora PostgreSQL 以使用 Amazon Comprehend
在接下来的过程中,您首先创建 IAM 角色和策略,它们授予 Aurora PostgreSQL 代表集群使用 Amazon Comprehend 的权限。然后,您将策略附加到 Aurora PostgreSQL 数据库集群用来与 Amazon Comprehend 结合使用的 IAM 角色。为简单起见,此过程使用 Amazon Web Services 管理控制台来完成所有任务。
设置 Aurora PostgreSQL 数据库集群以使用 Amazon Comprehend
登录 Amazon Web Services 管理控制台,然后通过以下网址打开 IAM 控制台:https://console.aws.amazon.com/iam/
。 通过 https://console.aws.amazon.com/iam/
打开 IAM 控制台。 在 Amazon Identity and Access Management(IAM)控制台菜单上选择 Policies(策略)[在 Access management(访问管理)下]。
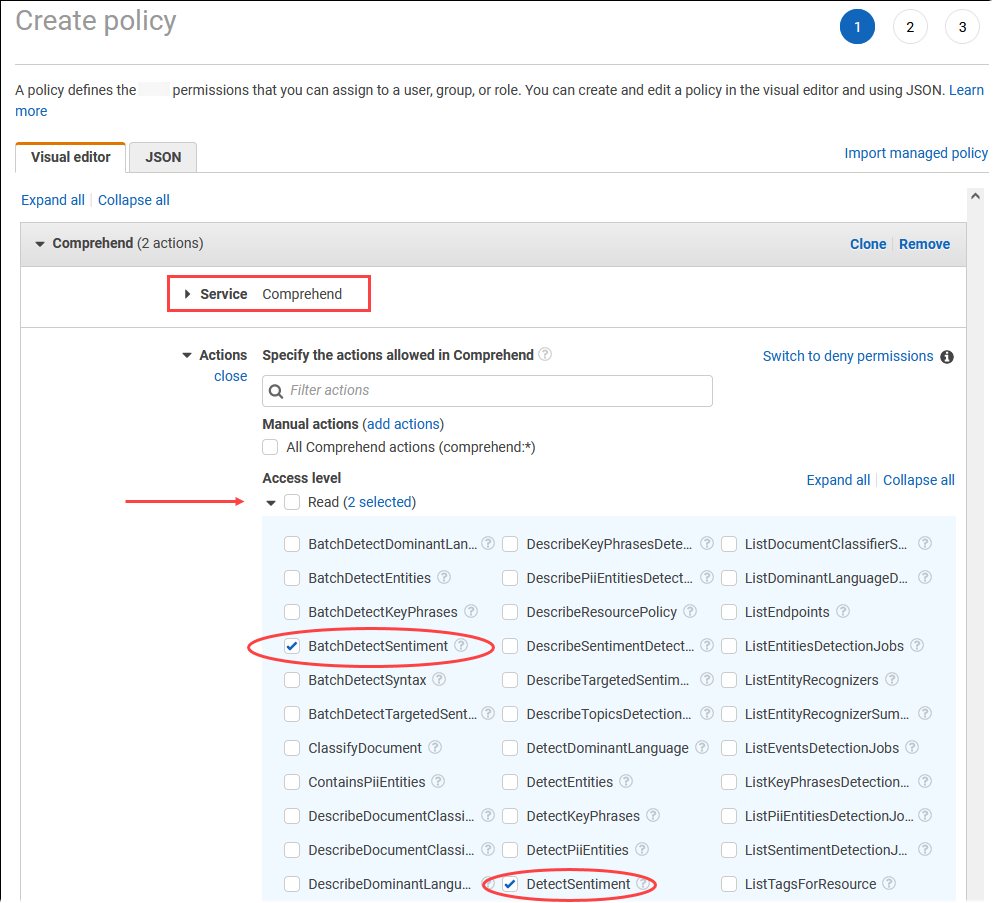
选择创建策略。在可视化编辑器页面中,选择 Service(服务),然后在 Select a service(选择服务)字段中输入 Comprehend。展开读取访问权限级别。从 Amazon Comprehend 读取设置中选择 BatchDetectSentiment 和 DetectSentiment。
选择 Next: Tags(下一步:标签)并定义任何标签(这是可选的)。选择下一步:审核。输入策略的名称和说明,如图中所示。
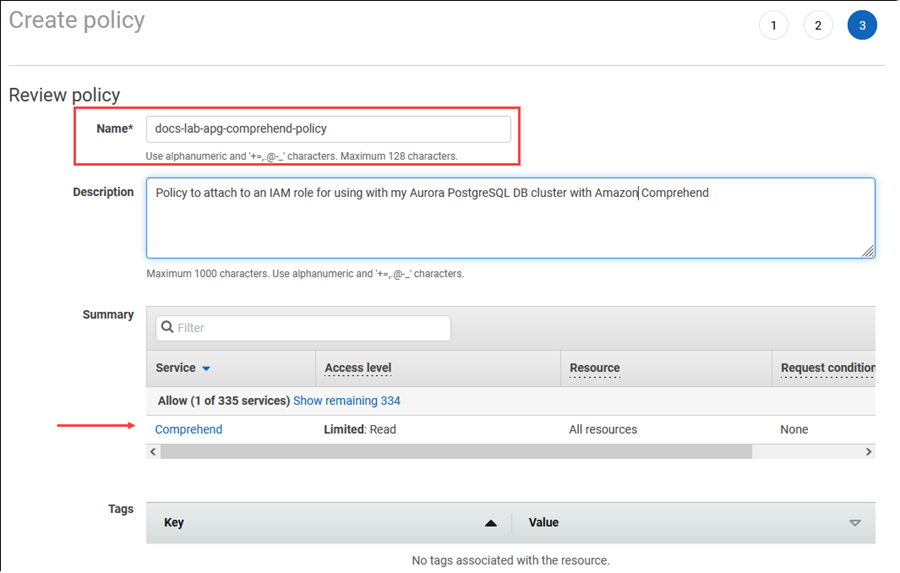
选择创建策略。保存策略后,控制台会显示提示。您可以在 Policies(策略)列表中找到它。
在 IAM 控制台上选择 Roles(角色)[在 Access management(访问管理)下]。
选择创建角色。
在“选择可信实体”页面上,选择 Amazon 服务磁贴,然后选择 RDS 以打开选择器。
选择 RDS – Add Role to Database(RDS – 将角色添加到数据库)。
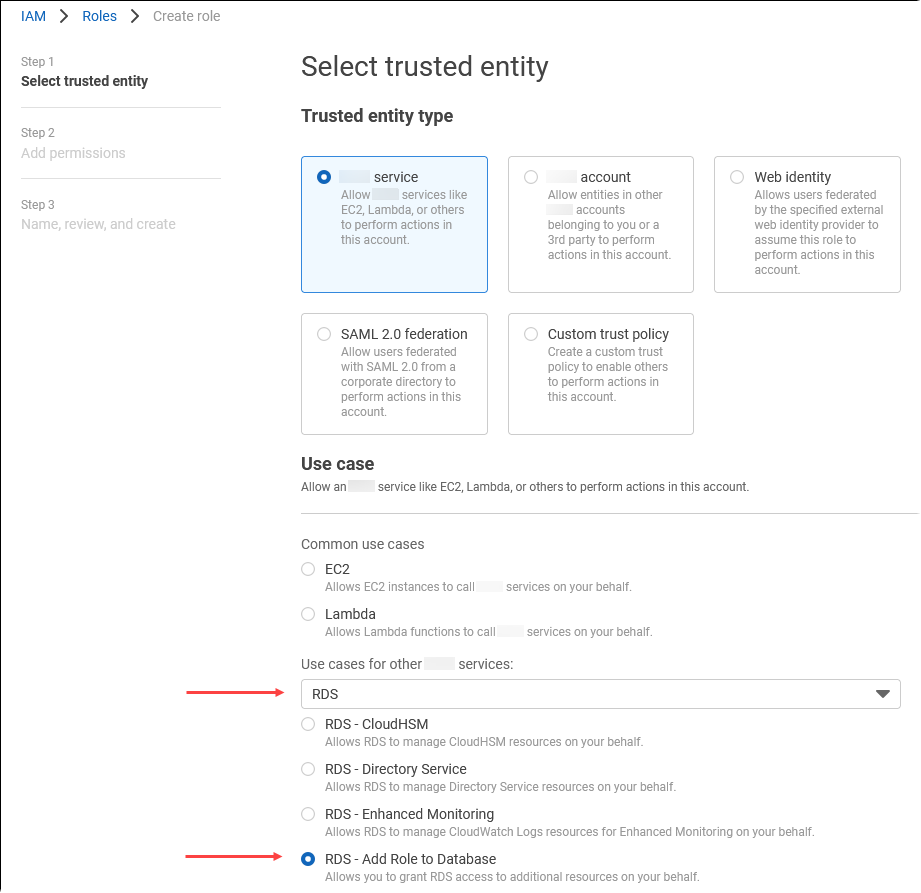
选择下一步。在 Add permissions(添加权限)页面上,找到您在上一步中创建的策略,并从列出的策略中选择此策略。选择 Next(下一步)
Next: Review(下一步:审核)。输入 IAM 角色的名称和说明。
通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 导航到 Aurora PostgreSQL 数据库集群所在的 Amazon Web Services 区域。
-
在导航窗格中,选择 Databases(数据库),然后选择要与 Amazon Comprehend 结合使用的 Aurora PostgreSQL 数据库集群。
-
选择 Connectivity & security(连接和安全性)选项卡,然后滚动以找到该页面的 Manage IAM roles(管理 IAM 角色)部分。从 Add IAM roles to this cluster(将 IAM 角色添加到此集群)选择器中,选择您在前面的步骤中创建的角色。在功能选择器中,选择 Comprehend,然后选择添加角色。
该角色(及其策略)与 Aurora PostgreSQL 数据库集群相关联。该过程完成后,该角色将在 Current IAM roles for this cluster(此集群的当前 IAM 角色)列表中列出,如下所示。
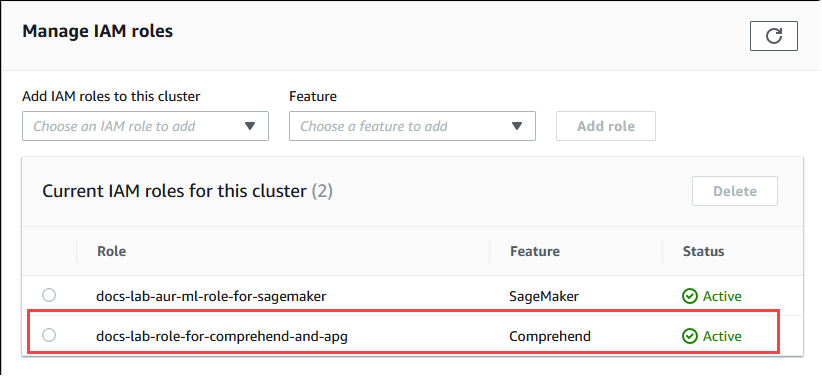
Amazon Comprehend 的 IAM 设置已完成。通过安装扩展继续设置 Aurora PostgreSQL 以使用 Aurora 机器学习,详见 安装 Aurora 机器学习扩展。
设置 Aurora PostgreSQL 以使用 Amazon SageMaker AI
在为 Aurora PostgreSQL 数据库集群创建 IAM 策略和角色之前,您需要设置 SageMaker AI 模型且端点可用。
设置 Aurora PostgreSQL 数据库集群以使用 SageMaker AI
登录 Amazon Web Services 管理控制台,然后通过以下网址打开 IAM 控制台:https://console.aws.amazon.com/iam/
。 在 Amazon Identity and Access Management(IAM)控制台菜单上选择 Policies(策略)[在 Access management(访问管理)下],然后选择 Create policy(创建策略)。在可视化编辑器中,对于 Service(服务)选择 SageMaker。对于 Actions(操作),打开 Read(读取)选择器 [在 Access level(访问级别)下],然后选择 InvokeEndpoint。当您这样做时,会显示一个警告图标。
打开 Resources(资源)选择器,然后在 InvokeEndpoint 操作的 Specify endpoint resource ARN(指定端点资源 ARN)下选择 Add ARN to restrict access(添加 ARN 以限制访问权限)链接。
输入 SageMaker AI 资源的 Amazon Web Services 区域和端点的名称。您的 Amazon 账户已预先填入。
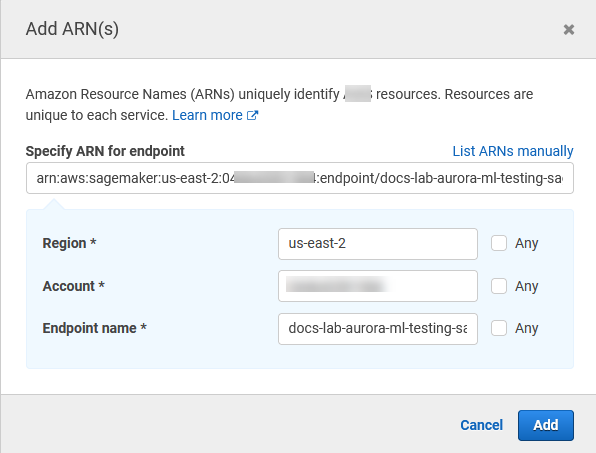
选择 Add(添加)以保存。选择 Next: Tags(下一步:标签)和 Next: Review(下一步:检查),以进入策略创建过程的最后一页。
输入此策略的 Name(名称)和 Description(描述),然后选择 Create policy(创建角色)。策略已创建并添加到 Policies(策略)列表中。发生这种情况时,您会在控制台中看到提示。
在 IAM 控制台中,选择 Roles(角色)。
选择 Create role(创建角色)。
在“选择可信实体”页面上,选择 Amazon 服务磁贴,然后选择 RDS 以打开选择器。
选择 RDS – Add Role to Database(RDS – 将角色添加到数据库)。
选择下一步。在 Add permissions(添加权限)页面上,找到您在上一步中创建的策略,并从列出的策略中选择此策略。选择 Next(下一步)
Next: Review(下一步:审核)。输入 IAM 角色的名称和说明。
通过以下网址打开 Amazon RDS 控制台:https://console.aws.amazon.com/rds/
。 导航到 Aurora PostgreSQL 数据库集群所在的 Amazon Web Services 区域。
-
在导航窗格中,选择数据库,然后选择要与 SageMaker AI 结合使用的 Aurora PostgreSQL 数据库集群。
-
选择 Connectivity & security(连接和安全性)选项卡,然后滚动以找到该页面的 Manage IAM roles(管理 IAM 角色)部分。从 Add IAM roles to this cluster(将 IAM 角色添加到此集群)选择器中,选择您在前面的步骤中创建的角色。在功能选择器中,选择 SageMaker AI,然后选择添加角色。
该角色(及其策略)与 Aurora PostgreSQL 数据库集群相关联。该过程完成后,该角色将在 Current IAM roles for this cluster(此集群的当前 IAM 角色)列表中列出。
SageMaker AI 的 IAM 设置已完成。通过安装扩展继续设置 Aurora PostgreSQL 以使用 Aurora 机器学习,详见 安装 Aurora 机器学习扩展。
设置 Aurora PostgreSQL 以将 Amazon S3 用于 SageMaker AI(高级)
要将 SageMaker AI 用于自己的模型,而不是使用 SageMaker AI 提供的预构建组件,您需要为 Aurora PostgreSQL 数据库集群设置一个 Amazon Simple Storage Service(Amazon S3)存储桶以供使用。这是一个高级主题,本《Amazon Aurora 用户指南》中没有完整记载。一般过程与集成对 SageMaker AI 的支持的过程一样,如下所示。
为 Amazon S3 创建 IAM 策略和角色。
添加 IAM 角色,并在 Aurora PostgreSQL 数据库集群的 Connectivity & security(连接和安全性)选项卡上将 Amazon S3 导入或导出添加为一项功能。
将角色的 ARN 添加到 Aurora 数据库集群的自定义数据库集群参数组中。
有关基本使用信息,请参阅 将数据导出到 Amazon S3 以进行 SageMaker AI 模型训练(高级)。
安装 Aurora 机器学习扩展
Aurora 机器学习扩展 aws_ml 1.0 提供了两个函数,您可以使用它们来调用 Amazon Comprehend、SageMaker AI 服务;而 aws_ml 2.0 提供了两个其他函数,您可以使用它们来调用 Amazon Bedrock 服务。在 Aurora PostgreSQL 数据库集群上安装这些扩展还会为该功能创建管理角色。
注意
使用这些函数取决于已完成 Aurora 机器学习服务(Amazon Comprehend、SageMaker AI、Amazon Bedrock)的 IAM 设置,详见设置 Aurora PostgreSQL 数据库集群以使用 Aurora 机器学习。
aws_comprehend.detect_sentiment – 您可以使用此函数将情感分析应用于存储在 Aurora PostgreSQL 数据库集群上的数据库中的文本。
aws_sagemaker.invoke_endpoint – 您在 SQL 代码中使用此函数与集群中的 SageMaker AI 端点进行通信。
aws_bedrock.invoke_model – 您在 SQL 代码中使用此函数与集群中的 Bedrock 模型进行通信。此函数的响应将采用 TEXT 格式,因此,如果模型以 JSON 正文的格式进行响应,则此函数的输出将以字符串的格式传递给最终用户。
aws_bedrock.invoke_model_get_embeddings – 您可以在 SQL 代码中使用此函数来调用 Bedrock 模型,这些模型在 JSON 响应中返回输出嵌入内容。当您想提取与 json-key 直接关联的嵌入内容时,可以利用这一点来简化任何自行管理的工作流程的响应。
在 Aurora PostgreSQL 数据库集群中安装 Aurora 机器学习扩展
使用
psql连接到 Aurora PostgreSQL 数据库集群的写入器实例。连接到要在其中安装aws_ml扩展的特定数据库。psql --host=cluster-instance-1.111122223333.aws-region.rds.amazonaws.com --port=5432 --username=postgres --password --dbname=labdb
labdb=>CREATE EXTENSION IF NOT EXISTS aws_ml CASCADE;NOTICE: installing required extension "aws_commons" CREATE EXTENSIONlabdb=>
安装 aws_ml 扩展还会创建 aws_ml 管理角色和三个新架构,如下所示。
aws_comprehend– 适用于 Amazon Comprehend 服务和detect_sentiment函数(aws_comprehend.detect_sentiment)的来源的模式。aws_sagemaker– 适用于 SageMaker AI 服务和invoke_endpoint函数(aws_sagemaker.invoke_endpoint)的来源的模式。aws_bedrock– 适用于 Amazon Bedrock 服务以及invoke_model(aws_bedrock.invoke_model)和invoke_model_get_embeddings(aws_bedrock.invoke_model_get_embeddings)函数的来源的架构。
rds_superuser 角色被授予 aws_ml 管理角色,并成为这三个 Aurora 机器学习架构的 OWNER。要允许其他数据库用户访问 Aurora 机器学习函数,rds_superuser 需要授予对 Aurora 机器学习函数的 EXECUTE 权限。默认情况下,对于这两个 Aurora 机器学习模式中的函数,将从 PUBLIC 中撤销 EXECUTE 权限。
在多租户数据库配置中,您可以通过对您要保护的特定 Aurora 机器学习模式使用 REVOKE USAGE,以阻止租户访问 Aurora 机器学习函数。
将 Amazon Bedrock 与 Aurora PostgreSQL 数据库集群结合使用
对于 Aurora PostgreSQL,Aurora 机器学习提供了以下 Amazon Bedrock 函数来处理文本数据。只有在安装 aws_ml 2.0 扩展并完成所有设置过程后,此函数才可用。有关更多信息,请参阅 设置 Aurora PostgreSQL 数据库集群以使用 Aurora 机器学习。
- aws_bedrock.invoke_model
-
此函数采用 JSON 格式的文本作为输入,并针对托管在 Amazon Bedrock 上的各种模型对其进行处理,然后从模型中获取 JSON 文本响应。此响应可能包含文本、图像或嵌入内容。该函数的文档摘要如下所示。
aws_bedrock.invoke_model( IN model_id varchar, IN content_type text, IN accept_type text, IN model_input text, OUT model_output varchar)
此函数的输入和输出如下所示。
-
model_id– 模型的标识符。 content_type– 对 Bedrock 的模型的请求类型。accept_type– 期望从 Bedrock 的模型中得到的响应类型。对于大多数模型,通常为应用程序/JSON。model_input– 提示;模型的一组特定输入,格式由 content_type 指定。有关模型接受的请求格式/结构的更多信息,请参阅 Inference parameters for foundation models。model_output– Bedrock 模型的输出(文本形式)。
以下示例说明如何使用 invoke_model 为 Bedrock 调用 Anthropic Claude 2 模型。
例示例:使用 Amazon Bedrock 函数的简单查询
SELECT aws_bedrock.invoke_model ( model_id := 'anthropic.claude-v2', content_type:= 'application/json', accept_type := 'application/json', model_input := '{"prompt": "\n\nHuman: You are a helpful assistant that answers questions directly and only using the information provided in the context below.\nDescribe the answer in detail.\n\nContext: %s \n\nQuestion: %s \n\nAssistant:","max_tokens_to_sample":4096,"temperature":0.5,"top_k":250,"top_p":0.5,"stop_sequences":[]}' );
- aws_bedrock.invoke_model_get_embeddings
-
在某些情况下,模型输出可以指向向量嵌入内容。鉴于每个模型的响应各不相同,可以利用另一个函数 invoke_model_get_embeddings,它的工作原理与 invoke_model 完全一样,但是通过指定相应的 json-key 来输出嵌入内容。
aws_bedrock.invoke_model_get_embeddings( IN model_id varchar, IN content_type text, IN json_key text, IN model_input text, OUT model_output float8[])
此函数的输入和输出如下所示。
-
model_id– 模型的标识符。 content_type– 对 Bedrock 的模型的请求类型。在这里,accept_type 设置为默认值application/json。model_input– 提示;模型的一组特定输入,格式由 content_type 指定。有关模型接受的请求格式/结构的更多信息,请参阅 Inference parameters for foundation models。json_key- 对要从中提取嵌入内容的字段的引用。如果嵌入模型发生变化,则可能会有所不同。-
model_output– Bedrock 模型的输出,作为一个具有 16 位小数的嵌入内容数组。
以下示例显示了如何使用 Titan Embeddings G1 - 文本嵌入模型为 PostgreSQL I/O 监控视图短语生成嵌入内容。
例示例:使用 Amazon Bedrock 函数的简单查询
SELECT aws_bedrock.invoke_model_get_embeddings( model_id := 'amazon.titan-embed-text-v1', content_type := 'application/json', json_key := 'embedding', model_input := '{ "inputText": "PostgreSQL I/O monitoring views"}') AS embedding;
将 Amazon Comprehend 与 Aurora PostgreSQL 数据库集群结合使用
对于 Aurora PostgreSQL,Aurora 机器学习提供了以下 Amazon Comprehend 函数来处理文本数据。只有在安装 aws_ml 扩展并完成所有设置过程后,此函数才可用。有关更多信息,请参阅 设置 Aurora PostgreSQL 数据库集群以使用 Aurora 机器学习。
- aws_comprehend.detect_sentiment
-
此函数将文本作为输入,并评估文本是否具有正面、负面、中立或混合的情感姿态。它会输出这种情绪以及其评估的置信度。该函数的文档摘要如下所示。
aws_comprehend.detect_sentiment( IN input_text varchar, IN language_code varchar, IN max_rows_per_batch int, OUT sentiment varchar, OUT confidence real)
此函数的输入和输出如下所示。
-
input_text– 用于评估和分配情绪(负面、正面、中立、混合)的文本。 language_code– 使用带有区域子标签(根据需要)的双字母 ISO 639-1 标识符或 ISO 639-2 三字母代码(视情况而定)标识的input_text的语言。例如,en是英语的代码,zh是简体中文的代码。有关更多信息,请参阅《Amazon Comprehend 开发人员指南》中的支持的语言。max_rows_per_batch– 批处理模式处理的每个批处理的最大行数。有关更多信息,请参阅 了解批处理模式和 Aurora 机器学习函数。sentiment– 输入文本的情绪,标识为 POSITIVE、NEGATIVE、NEUTRAL 或 MIXED。confidence– 指定sentiment的准确性的置信度。值范围为 0.0 到 1.0。
在下文中,您可以找到如何使用此函数的示例。
例示例:使用 Amazon Comprehend 函数的简单查询
以下是一个简单查询的示例,它调用此函数来评估客户对您的支持团队的满意度。假设您有一个数据库表(support),该表存储每次请求帮助后的客户反馈。此示例查询将 aws_comprehend.detect_sentiment 函数应用于表的 feedback 列中的文本,并输出情绪和该情绪的置信度。此查询还按降序输出结果。
SELECT feedback, s.sentiment,s.confidence FROM support,aws_comprehend.detect_sentiment(feedback, 'en') s ORDER BY s.confidence DESC;feedback | sentiment | confidence ----------------------------------------------------------+-----------+------------ Thank you for the excellent customer support! | POSITIVE | 0.999771 The latest version of this product stinks! | NEGATIVE | 0.999184 Your support team is just awesome! I am blown away. | POSITIVE | 0.997774 Your product is too complex, but your support is great. | MIXED | 0.957958 Your support tech helped me in fifteen minutes. | POSITIVE | 0.949491 My problem was never resolved! | NEGATIVE | 0.920644 When will the new version of this product be released? | NEUTRAL | 0.902706 I cannot stand that chatbot. | NEGATIVE | 0.895219 Your support tech talked down to me. | NEGATIVE | 0.868598 It took me way too long to get a real person. | NEGATIVE | 0.481805 (10 rows)
要避免针对每个表行支付多次情绪检测费用,您可以对结果进行具体化。队感兴趣的行执行此操作。例如,正在更新临床医生的笔记,以便只有讲法语(fr)的人才能使用情绪检测功能。
UPDATE clinician_notes SET sentiment = (aws_comprehend.detect_sentiment (french_notes, 'fr')).sentiment, confidence = (aws_comprehend.detect_sentiment (french_notes, 'fr')).confidence WHERE clinician_notes.french_notes IS NOT NULL AND LENGTH(TRIM(clinician_notes.french_notes)) > 0 AND clinician_notes.sentiment IS NULL;
有关优化函数调用的更多信息,请参阅将 Aurora 机器学习与 Aurora PostgreSQL 结合使用的性能注意事项。
将 SageMaker AI 与 Aurora PostgreSQL 数据库集群结合使用
在如 设置 Aurora PostgreSQL 以使用 Amazon SageMaker AI 中所述设置 SageMaker AI 环境并与 Aurora PostgreSQL 集成后,您可以使用 aws_sagemaker.invoke_endpoint 函数调用操作。aws_sagemaker.invoke_endpoint 函数仅连接到同一 Amazon Web Services 区域 中的模型端点。如果您的数据库实例在多个 Amazon Web Services 区域 中有副本,请确保在每个 Amazon Web Services 区域 中设置并部署每个 SageMaker AI 模型。
对 aws_sagemaker.invoke_endpoint 的调用使用您设置的 IAM 角色进行身份验证,该角色用于将 Aurora PostgreSQL 数据库集群与 SageMaker AI 服务以及您在设置过程中提供的端点相关联。SageMaker AI 模型端点的作用域限于单个账户,并且不是公有的。endpoint_name URL 不包含账户 ID。SageMaker AI 通过由数据库实例的 SageMaker AI IAM 角色提供的身份验证令牌确定账户 ID。
- aws_sagemaker.invoke_endpoint
此函数将 SageMaker AI 端点作为输入,并将应处理的行数作为一个批次进行处理。它还将 SageMaker AI 模型端点预期的各种参数作为输入。此函数的参考文档如下所示。
aws_sagemaker.invoke_endpoint( IN endpoint_name varchar, IN max_rows_per_batch int, VARIADIC model_input "any", OUT model_output varchar )
此函数的输入和输出如下所示。
endpoint_name– 独立于 Amazon Web Services 区域 的端点 URL。max_rows_per_batch– 批处理模式处理的每个批处理的最大行数。有关更多信息,请参阅 了解批处理模式和 Aurora 机器学习函数。model_input– 适用于模型的一个或多个输入参数。它们可以是 SageMaker AI 模型所需的任何数据类型。PostgreSQL 允许您为一个函数指定最多 100 个输入参数。数组数据类型必须是一维的,但可以包含 SageMaker AI 模型期望的尽可能多的元素。SageMaker AI 模型的输入数仅受 SageMaker AI 6 MB 消息大小限制所限。model_output– SageMaker AI 模型的输出(文本形式)。
创建用户定义的函数以调用 SageMaker AI 模型
创建单独的用户定义的函数来为每个 SageMaker AI 模型调用 aws_sagemaker.invoke_endpoint。您的用户定义的函数表示托管模型的 SageMaker AI 端点。aws_sagemaker.invoke_endpoint 函数在用户定义的函数中运行。用户定义的函数提供了许多好处:
-
可以为 SageMaker AI 模型指定其自己的名称,而不是仅为所有 SageMaker AI 模型调用
aws_sagemaker.invoke_endpoint。 -
可以仅在 SQL 应用程序代码中的一个位置指定模型端点 URL。
-
可以单独控制每个 Aurora 机器学习函数的
EXECUTE权限。 -
可以使用 SQL 类型声明模型输入和输出类型。SQL 强制实施传递给 SageMaker AI 模型的参数的数量和类型,并在必要时执行类型转换。使用 SQL 类型还会将
SQL NULL转换为 SageMaker AI 模型预期的适当默认值。 -
如果要更快地返回前几行,则可以减小最大批处理大小。
要指定用户定义的函数,请使用 SQL 数据定义语言 (DDL) 语句 CREATE FUNCTION。在定义函数时,您指定了以下内容:
-
模型的输入参数。
-
要调用的特定 SageMaker AI 端点。
-
返回类型。
用户定义的函数在对输入参数运行模型后,将返回 SageMaker AI 端点计算的推理。以下示例为带两个输入参数的 SageMaker AI 模型创建用户定义的函数。
CREATE FUNCTION classify_event (IN arg1 INT, IN arg2 DATE, OUT category INT)
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', NULL,
arg1, arg2 -- model inputs are separate arguments
)::INT -- cast the output to INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;请注意以下几点:
-
aws_sagemaker.invoke_endpoint函数输入可以是任意数据类型的一个或多个参数。 -
此示例使用 INT 输出类型。如果将输出从
varchar类型强制转换为其他类型,则必须将其强制转换为 PostgreSQL 内置标量类型,例如INTEGER、REAL、FLOAT或NUMERIC。有关这些类型的更多信息,请参阅 PostgreSQL 文档中的数据类型。 -
指定
PARALLEL SAFE可启用并行查询处理。有关更多信息,请参阅“通过并行查询处理缩短响应时间”。 -
指定
COST 5000以估计运行函数的成本。使用正数来提供函数的估计运行成本,单位为cpu_operator_cost。
将数组作为输入传递到 SageMaker AI 模型
aws_sagemaker.invoke_endpoint 函数最多可具有 100 个输入参数,这是 PostgreSQL 函数的限制。如果 SageMaker AI 模型需要 100 个以上的相同类型的参数,则将模型参数作为数组传递。
以下示例定义一个函数,该函数将数组作为输入传递到 SageMaker AI 回归模型。输出将强制转换为 REAL 值。
CREATE FUNCTION regression_model (params REAL[], OUT estimate REAL) AS $$ SELECT aws_sagemaker.invoke_endpoint ( 'sagemaker_model_endpoint_name', NULL, params )::REAL $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
在调用 SageMaker AI 模型时指定批处理大小
以下示例为 SageMaker AI 模型创建一个用户定义的函数,该函数将批处理大小的默认值设置为 NULL。此外,在您调用该函数时,它可让您提供其他批处理大小。
CREATE FUNCTION classify_event (
IN event_type INT, IN event_day DATE, IN amount REAL, -- model inputs
max_rows_per_batch INT DEFAULT NULL, -- optional batch size limit
OUT category INT) -- model output
AS $$
SELECT aws_sagemaker.invoke_endpoint (
'sagemaker_model_endpoint_name', max_rows_per_batch,
event_type, event_day, COALESCE(amount, 0.0)
)::INT -- casts output to type INT
$$ LANGUAGE SQL PARALLEL SAFE COST 5000;请注意以下几点:
-
使用可选的
max_rows_per_batch参数可控制批处理模式函数调用的行数。如果您使用 NULL 值,则查询优化程序会自动选择最大批处理大小。有关更多信息,请参阅 了解批处理模式和 Aurora 机器学习函数。 -
默认情况下,作为参数值传递的 NULL 将转换为空字符串,然后再传递到 SageMaker AI。对于此示例,输入具有不同的类型。
-
如果您具有非文本输入,或具有需要默认为空字符串以外的某个值的文本输入,请使用
COALESCE语句。使用COALESCE可在对aws_sagemaker.invoke_endpoint的调用中将 NULL 转换为所需的空替换值。对于此示例中的amount参数,NULL 值将转换为 0.0。
调用带多个输出的 SageMaker AI 模型
以下示例为返回多个输出的 SageMaker AI 模型创建一个用户定义的函数。您的函数需要将 aws_sagemaker.invoke_endpoint 函数的输出强制转换为相应的数据类型。例如,可以将内置 PostgreSQL 点类型用于 (x,y) 对或用户定义的复合类型。
此用户定义的函数将返回一个模型中的值,该模型通过对输出使用复合类型来返回多个输出。
CREATE TYPE company_forecasts AS ( six_month_estimated_return real, one_year_bankruptcy_probability float); CREATE FUNCTION analyze_company ( IN free_cash_flow NUMERIC(18, 6), IN debt NUMERIC(18,6), IN max_rows_per_batch INT DEFAULT NULL, OUT prediction company_forecasts) AS $$ SELECT (aws_sagemaker.invoke_endpoint('endpt_name', max_rows_per_batch,free_cash_flow, debt))::company_forecasts; $$ LANGUAGE SQL PARALLEL SAFE COST 5000;
对于复合类型,按照字段在模型输出中的显示顺序来使用字段,并将 aws_sagemaker.invoke_endpoint 的输出强制转换为复合类型。调用方可以按名称或使用 PostgreSQL“.*”表示法来提取各个字段。
将数据导出到 Amazon S3 以进行 SageMaker AI 模型训练(高级)
建议您使用提供的算法和示例来熟悉 Aurora 机器学习和 SageMaker AI,而不是尝试训练自己的模型。有关更多信息,请参阅 Get Started with Amazon SageMaker AI。
要训练 SageMaker AI 模型,请将数据导出到 Amazon S3 存储桶。SageMaker AI 使用 Amazon S3 存储桶在部署模型之前对其进行训练。您可以从 Aurora PostgreSQL 数据库集群中查询数据,并将数据直接保存到 Amazon S3 存储桶中存储的文本文件。然后,SageMaker AI 使用 Amazon S3 存储桶中的数据进行训练。有关 SageMaker AI 模型训练的更多信息,请参阅 Train a model with Amazon SageMaker AI。
注意
在为 SageMaker AI 模型训练或批处理评分创建 Amazon S3 存储桶时,请在 Amazon S3 存储桶名称中使用 sagemaker。有关更多信息,请参阅《Amazon SageMaker AI 开发人员指南》中的 Specify a Amazon S3 Bucket to Upload Training Datasets and Store Output Data。
有关导出数据的更多信息,请参阅将数据从 Aurora PostgreSQL 数据库集群导出到 Amazon S3。
将 Aurora 机器学习与 Aurora PostgreSQL 结合使用的性能注意事项
Amazon Comprehend 和 SageMaker AI 服务在由 Aurora 机器学习函数调用时会完成大部分工作。这意味着您可以根据需要独立扩缩这些资源。对于您的 Aurora PostgreSQL 数据库集群,您可以使函数调用尽可能高效。接下来,您可以找到从 Aurora PostgreSQL 中使用 Aurora 机器学习时需要注意的一些性能注意事项。
了解批处理模式和 Aurora 机器学习函数
通常,PostgreSQL 一次运行一行函数。Aurora 机器学习可通过使用称作批处理模式执行的方法,针对多个行将对外部 Aurora 机器学习服务的调用组合为批处理来减少此开销。在批处理模式中,Aurora 机器学习将接收对一批输入行的响应,然后将响应传回正在运行的查询(一次一行)。此优化将提高 Aurora 查询的吞吐量,而不限制 PostgreSQL 查询优化程序。
如果从 SELECT 列表、WHERE 子句或 HAVING 子句引用函数,则 Aurora 会自动使用批处理模式。请注意,顶级的简单 CASE 表达式符合批处理模式执行的条件。顶级搜索的 CASE 表达式符合批处理模式执行的条件,前提是第一个 WHEN 子句是具有批处理模式函数调用的简单谓词。
您的用户定义的函数必须是一个 LANGUAGE SQL 函数,并且应指定 PARALLEL SAFE 和 COST 5000。
从 SELECT 语句到 FROM 子句的函数迁移
通常,Aurora 会自动将符合批处理模式执行条件的 aws_ml 函数迁移到 FROM 子句。
可以在每个查询级别上手动检查合格的批处理模式函数到 FROM 子句的迁移。为此,您可以使用 EXPLAIN 语句(以及 ANALYZE 和 VERBOSE),并在每个批处理模式 Function Scan 下查找“批处理”信息。您也可以在不运行查询的情况下使用 EXPLAIN(以及 VERBOSE)。然后,您可以观察对函数的调用是否在原始语句中未指定的嵌套循环联接下显示为 Function
Scan。
在以下示例中,计划中的嵌套循环联接运算符表明 Aurora 已迁移 anomaly_score 函数。它已将此函数从 SELECT 列表迁移到 FROM 子句,其中它符合批处理模式执行的条件。
EXPLAIN (VERBOSE, COSTS false)
SELECT anomaly_score(ts.R.description) from ts.R;
QUERY PLAN
-------------------------------------------------------------
Nested Loop
Output: anomaly_score((r.description)::text)
-> Seq Scan on ts.r
Output: r.id, r.description, r.score
-> Function Scan on public.anomaly_score
Output: anomaly_score.anomaly_score
Function Call: anomaly_score((r.description)::text)要禁用批处理模式执行,请将 apg_enable_function_migration 参数设置为 false。这可阻止 aws_ml 函数从 SELECT 迁移到 FROM 子句。下面演示了如何操作。
SET apg_enable_function_migration = false;apg_enable_function_migration 参数是一个由查询计划管理的 Aurora PostgreSQL apg_plan_mgmt 扩展识别的 Grand Unified Configuration (GUC) 参数。要在会话中禁用函数迁移,请使用查询计划管理将生成的计划另存为 approved 计划。在运行时,查询计划管理会使用其 approved 设置强制执行 apg_enable_function_migration 计划。无论 apg_enable_function_migration GUC 参数设置如何,此强制执行都会发生。有关更多信息,请参阅“管理 Aurora PostgreSQL 的查询执行计划”。
使用 max_rows_per_batch 参数
aws_comprehend.detect_sentiment 和 aws_sagemaker.invoke_endpoint 函数都有一个 max_rows_per_batch 参数。此参数指定可以发送到 Aurora 机器学习服务的行数。函数处理的数据集越大,批处理大小就可以越大。
批处理模式函数通过构建批量行来将 Aurora 机器学习函数调用的成本分散在大量行上,从而提高效率。但是,如果 SELECT 语句因 LIMIT 子句而提前完成,则可以在比查询使用的行更多的行上构建批处理。此方法可能会导致您的 Amazon 账户产生额外费用。要获得批处理模式执行的好处,并避免构建过大的批处理,请在函数调用中使用较小的 max_rows_per_batch 参数值。
如果您执行使用批处理模式执行的查询的 EXPLAIN(VERBOSE、ANALYZE),则嵌套循环联接下方将显示 FunctionScan 运算符。EXPLAIN 报告的循环数等于已从 FunctionScan 运算符提取某个行的次数。如果语句使用了 LIMIT 子句,则提取次数是一致的。要优化批处理的大小,请将 max_rows_per_batch 参数设置为此值。但是,如果批处理模式函数是在 WHERE 子句或 HAVING 子句的谓词中引用的,则您可能无法预先知道提取次数。在此情况下,使用循环作为指南,并尝试使用 max_rows_per_batch 查找可优化性能的设置。
验证批处理模式执行
要查看函数是否在批处理模式下运行,请使用 EXPLAIN ANALYZE。如果使用了批处理模式执行,则查询计划将在“批处理”部分中包含此信息。
EXPLAIN ANALYZE SELECT user-defined-function();
Batch Processing: num batches=1 avg/min/max batch size=3333.000/3333.000/3333.000
avg/min/max batch call time=146.273/146.273/146.273在此示例中,有 1 个批处理包含 3333 个行,其处理时间为 146.273 毫秒。“批处理”部分显示以下内容:
-
针对此函数扫描操作的批处理的数目
-
批处理大小的平均值、最小值和最大值
-
批处理执行时间的平均值、最小值和最大值
最后一个批处理通常会小于其余的批处理,这通常会导致最小批处理大小比平均值小得多。
要更快地返回前几行,请将 max_rows_per_batch 参数设置为较小的值。
要在用户定义的函数中使用 LIMIT 时减少对 ML 服务的批处理模式调用的次数,请将 max_rows_per_batch 参数设置为较小的值。
通过并行查询处理缩短响应时间
要尽快从大量行中获取结果,可以将并行查询处理与批处理模式处理结合使用。您可以对 SELECT、CREATE TABLE AS SELECT 和 CREATE
MATERIALIZED VIEW 语句使用并行查询处理。
注意
PostgreSQL 尚不支持对数据操作语言 (DML) 语句进行并行查询。
并行查询处理可同时在数据库和 ML 服务内进行。数据库实例类中的核心数将限制运行查询时可使用的并行度。数据库服务器可以构建并行查询执行计划,来将任务划分到一组并行工作线程中。随后,所有这些工作线程都能构建包含数万个(或每个服务允许的数量)行的批处理的请求。
来自所有并行工件的批处理请求将发送到 SageMaker AI 端点。端点可以支持的并行度受支持此端点的实例的数量和类型所约束。要获得 K 并行度,您需要一个具有至少 K 个核心的数据库实例类。您还需要为模型配置 SageMaker AI 端点,以具有性能足够高的实例类的 K 个初始实例。
要使用并行查询处理,您可以为包含您计划传递的数据的表设置 parallel_workers 存储参数。将 parallel_workers 设置为批处理模式函数,例如 aws_comprehend.detect_sentiment。如果优化程序选择并行查询计划,则可以批量调用和并行调用Amazon ML 服务。
可以将以下参数与 aws_comprehend.detect_sentiment 函数结合使用来获取具有四向并行度的计划。如果您更改以下两个参数中的任一参数,则必须重新启动数据库实例才能使更改生效。
-- SET max_worker_processes to 8; -- default value is 8
-- SET max_parallel_workers to 8; -- not greater than max_worker_processes
SET max_parallel_workers_per_gather to 4; -- not greater than max_parallel_workers
-- You can set the parallel_workers storage parameter on the table that the data
-- for the Aurora machine learning function is coming from in order to manually override the degree of
-- parallelism that would otherwise be chosen by the query optimizer
--
ALTER TABLE yourTable SET (parallel_workers = 4);
-- Example query to exploit both batch-mode execution and parallel query
EXPLAIN (verbose, analyze, buffers, hashes)
SELECT aws_comprehend.detect_sentiment(description, 'en')).*
FROM yourTable
WHERE id < 100;有关控制并行查询的更多信息,请参阅 PostgreSQL 文档中的并行计划
使用具体化视图和具体化列
当您从数据库中调用 Amazon 服务(例如 SageMaker AI 或 Amazon Comprehend)时,将根据该服务的定价策略向您的账户收费。要最大程度地减少向您的账户收取的费用,您可以将调用 Amazon 服务的结果具体化为一个具体化列,以便针对每个输入行调用 Amazon 服务的次数不会超过一次。如果需要,您可以添加 materializedAt 时间戳列来记录将列具体化的时间。
通用的单行 INSERT 语句的延迟通常比调用批处理模式函数的延迟短得多。因此,如果您为应用程序执行的每个单行 INSERT 调用批处理模式函数,则可能无法满足应用程序的延迟要求。要将调用 Amazon 服务的结果具体化为一个具体化列,高性能的应用程序通常需要填充具体化列。为此,它们会定期发布同时在大批行上运行的 UPDATE 语句。
UPDATE 接受可能影响正在运行的应用程序的行级锁定。因此,您可能需要使用 SELECT ... FOR UPDATE SKIP LOCKED,或使用 MATERIALIZED
VIEW。
针对大量的行实时运行的分析查询可以将批处理模式具体化与实时处理相结合。为此,这些查询会将预具体化结果的 UNION ALL 与对尚没有具体化结果的行执行的查询相结合。在某些情况下,多个位置需要此类 UNION ALL,否则查询将由第三方应用程序生成。如果是这样,您可以创建一个 VIEW 来封装 UNION ALL 操作,以便不向 SQL 应用程序的其余部分公开此详细信息。
您可以使用具体化视图在即时快照中具体化任意 SELECT 语句的结果。您还可以将来随时使用它刷新具体化视图。目前,PostgreSQL 不支持增量刷新,因此每次刷新具体化视图时,都会完全重新计算具体化视图。
可以使用 CONCURRENTLY 选项刷新具体化视图,这将在不使用排他锁的情况下更新具体化视图的内容。通过执行此操作,使 SQL 应用程序能够在刷新具体化视图时从该视图中进行读取。
监控 Aurora 机器学习
您可以通过将自定义数据库集群参数组中的 track_functions 参数设置为 all 来监控 aws_ml 函数。默认情况下,此参数设置为 pl,这意味着仅跟踪过程语言函数。通过将其更改为 all,还可以跟踪 aws_ml 函数。有关更多信息,请参阅 PostgreSQL 文档中的运行时统计数据
有关监控从 Aurora 机器学习函数调用的 SageMaker AI 操作的性能的信息,请参阅《Amazon SageMaker AI 开发人员指南》中的 Monitor Amazon SageMaker AI。
在将 track_functions 设置为 all 时,您可以查询 pg_stat_user_functions 视图,以获取有关您定义和用于调用 Aurora 机器学习服务的函数的统计数据。对于每个函数,该视图提供 calls、total_time 和 self_time 的数量。
要查看 aws_sagemaker.invoke_endpoint 和 aws_comprehend.detect_sentiment 函数的统计数据,您可以使用以下查询按模式名称筛选结果。
SELECT * FROM pg_stat_user_functions WHERE schemaname LIKE 'aws_%';
要清除统计数据,请执行以下操作。
SELECT pg_stat_reset();
您可以通过查询 PostgreSQL pg_proc 系统目录来获取调用 aws_sagemaker.invoke_endpoint 函数的 SQL 函数的名称。该目录存储有关函数、过程等的信息。有关更多信息,请参阅 PostgreSQL 文档中的 pg_procprosrc)包含文本 invoke_endpoint 的函数的名称(proname)。
SELECT proname FROM pg_proc WHERE prosrc LIKE '%invoke_endpoint%';