Amazon DocumentDB: how it works
Amazon DocumentDB (with MongoDB compatibility) is a fully managed, MongoDB-compatible database service. With Amazon DocumentDB, you can run the same application code and use the same drivers and tools that you use with MongoDB. Amazon DocumentDB is compatible with MongoDB 3.6, 4.0, 5.0, and 8.0.
Topics
Amazon DocumentDB versions
Note
Minor version numbering applies to Amazon DocumentDB 5.0 and later. Amazon DocumentDB 3.6 and 4.0 use only major versions with engine patches.
Starting with Amazon DocumentDB 5.0, the engine version uses a four-level numbering scheme: major.major.minor.patch.
-
Major version—Identified by the first two numbers of the version (for example, 5.0). The major version represents the MongoDB compatibility level. Major versions introduce new features, performance improvements, and MongoDB compatibility updates. Upgrading between major versions (for example, from 4.0 to 5.0) requires a major version upgrade (MVU). For more information, see Amazon DocumentDB in-place major version upgrade.
-
Minor version—Identified by the third number of the version (for example, the
1in 5.0.1). Minor versions include improvements such as new features, security fixes, and bug fixes within the same major version. You can upgrade to a new minor version manually. For more information, see Amazon DocumentDB minor version upgrade. -
Patch version—Engine patches are applied within a minor version and contain critical security fixes and bug fixes. The patch version is tracked by the engine patch version (for example,
3.0.17983), which you can check by runningdb.runCommand({getEngineVersion: 1}). Patches are applied during your cluster's maintenance window. For more information, see Maintaining Amazon DocumentDB.
When you create a new cluster, you can specify any available engine version. For information about available versions and support dates, see Amazon DocumentDB engine version support dates.
When you use Amazon DocumentDB, you begin by creating a cluster. A cluster consists of zero or more database instances and a cluster volume that manages the data for those instances. An Amazon DocumentDB cluster volume is a virtual database storage volume that spans multiple Availability Zones. Each Availability Zone has a copy of the cluster data.
An Amazon DocumentDB cluster consists of two components:
-
Cluster volume—Uses a cloud-native storage service to replicate data six ways across three Availability Zones, providing highly durable and available storage. An Amazon DocumentDB cluster has exactly one cluster volume, which can store up to 128 TiB of data.
-
Instances—Provide the processing power for the database, writing data to, and reading data from, the cluster storage volume. An Amazon DocumentDB cluster can have 0–16 instances.
Instances serve one of two roles:
-
Primary instance—Supports read and write operations, and performs all the data modifications to the cluster volume. Each Amazon DocumentDB cluster has one primary instance.
-
Replica instance—Supports only read operations. An Amazon DocumentDB cluster can have up to 15 replicas in addition to the primary instance. Having multiple replicas enables you to distribute read workloads. In addition, by placing replicas in separate Availability Zones, you also increase your cluster availability.
The following diagram illustrates the relationship between the cluster volume, the primary instance, and replicas in an Amazon DocumentDB cluster:
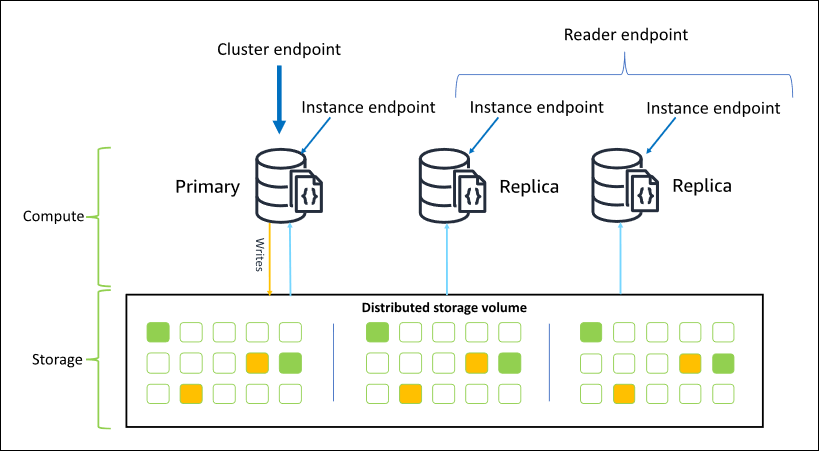
Cluster instances do not need to be of the same instance class, and they can be provisioned and terminated as desired. This architecture lets you scale your cluster’s compute capacity independently of its storage.
When your application writes data to the primary instance, the primary
executes a durable write to the cluster volume. It then replicates the
state of that write (not the data) to each active replica. Amazon DocumentDB replicas
do not participate in processing writes, and thus Amazon DocumentDB replicas are
advantageous for read scaling. Reads from Amazon DocumentDB replicas are eventually
consistent with minimal replica lag—usually less than 100
milliseconds after the primary instance writes the data. Reads from the
replicas are guaranteed to be read in the order in which they were written
to the primary. Replica lag varies depending on the rate of data change,
and periods of high write activity might increase the replica lag. For more
information, see the ReplicationLag metrics at Amazon DocumentDB metrics.
Amazon DocumentDB endpoints
Amazon DocumentDB provides multiple connection options to serve a wide range of use cases. To connect to an instance in an Amazon DocumentDB cluster, you specify the instance's endpoint. An endpoint is a host address and a port number, separated by a colon.
We recommend that you connect to your cluster using the cluster endpoint and in replica set mode (see Connecting to Amazon DocumentDB as a replica set) unless you have a specific use case for connecting to the reader endpoint or an instance endpoint. To route requests to your replicas, choose a driver read preference setting that maximizes read scaling while meeting your application's read consistency requirements. The secondaryPreferred read preference enables replica reads and frees up the primary instance to do more work.
The following endpoints are available from an Amazon DocumentDB cluster.
Cluster Endpoint
The cluster endpoint connects to your cluster’s current primary instance. The cluster endpoint can be used for read and write operations. An Amazon DocumentDB cluster has exactly one cluster endpoint.
The cluster endpoint provides failover support for read and write connections to the cluster. If your cluster’s current primary instance fails, and your cluster has at least one active read replica, the cluster endpoint automatically redirects connection requests to a new primary instance. When connecting to your Amazon DocumentDB cluster, we recommend that you connect to your cluster using the cluster endpoint and in replica set mode (see Connecting to Amazon DocumentDB as a replica set).
The following is an example Amazon DocumentDB cluster endpoint:
sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
The following is an example connection string using this cluster endpoint:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017
For information about finding a cluster's endpoints, see Finding a cluster's endpoints.
Reader endpoint
The reader endpoint load balances read-only connections across all available replicas in your cluster.
A cluster reader endpoint will perform as the cluster endpoint if you are connecting through replicaSet mode, meaning in the connection string, the replica set parameter is &replicaSet=rs0.
In this case, you will be able to perform write operations on the primary.
However, if you connect to the cluster specifying directConnection=true, then attempting to perform a write operation over a connection to the reader endpoint results in an error.
An Amazon DocumentDB cluster has exactly one reader endpoint.
If the cluster contains only one (primary) instance, the reader endpoint connects to the primary instance. When you add a replica instance to your Amazon DocumentDB cluster, the reader endpoint opens read-only connections to the new replica after it is active.
The following is an example reader endpoint for an Amazon DocumentDB cluster:
sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
The following is an example connection string using a reader endpoint:
mongodb://username:password@sample-cluster.cluster-ro-123456789012.us-east-1.docdb.amazonaws.com:27017
The reader endpoint load balances read-only connections, not read requests. If some reader endpoint connections are more heavily used than others, your read requests might not be equally balanced among instances in the cluster. It is recommended to distribute requests by connecting to the cluster endpoint as a replica set and utilizing the secondaryPreferred read preference option.
For information about finding a cluster's endpoints, see Finding a cluster's endpoints.
Instance endpoint
An instance endpoint connects to a specific instance within your cluster. The instance endpoint for the current primary instance can be used for read and write operations. However, attempting to perform write operations to an instance endpoint for a read replica results in an error. An Amazon DocumentDB cluster has one instance endpoint per active instance.
An instance endpoint provides direct control over connections to a specific instance for scenarios in which the cluster endpoint or reader endpoint might not be appropriate. An example use case is provisioning for a periodic read-only analytics workload. You can provision a larger-than-normal replica instance, connect directly to the new larger instance with its instance endpoint, run the analytics queries, and then terminate the instance. Using the instance endpoint keeps the analytics traffic from impacting other cluster instances.
The following is an example instance endpoint for a single instance in an Amazon DocumentDB cluster:
sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
The following is an example connection string using this instance endpoint:
mongodb://username:password@sample-instance.123456789012.us-east-1.docdb.amazonaws.com:27017
Note
An instance’s role as primary or replica can change due to a failover event. Your applications should never assume that a particular instance endpoint is the primary instance. We do not recommend connecting to instance endpoints for production applications. Instead, we recommend that you connect to your cluster using the cluster endpoint and in replica set mode (see Connecting to Amazon DocumentDB as a replica set). For more advanced control of instance failover priority, see Understanding Amazon DocumentDB cluster fault tolerance.
For information about finding a cluster's endpoints, see Finding an instance's endpoint.
Replica set mode
You can connect to your Amazon DocumentDB cluster endpoint in replica set mode by specifying the replica set name rs0. Connecting in replica
set mode provides the ability to specify the Read Concern, Write Concern, and Read Preference options. For more information, see Read consistency.
The following is an example connection string connecting in replica set mode:
mongodb://username:password@sample-cluster.cluster-123456789012.us-east-1.docdb.amazonaws.com:27017/?replicaSet=rs0
When you connect in replica set mode, your Amazon DocumentDB cluster appears to your drivers and clients as a replica set. Instances added and removed from your Amazon DocumentDB cluster are reflected automatically in the replica set configuration.
Each Amazon DocumentDB cluster consists of a single replica set with the default name rs0. The replica set name cannot be modified.
Connecting to the cluster endpoint in replica set mode is the recommended method for general use.
Note
All instances in an Amazon DocumentDB cluster listen on the same TCP port for connections.
TLS support
For more details on connecting to Amazon DocumentDB using Transport Layer Security (TLS), see Encrypting data in transit.
Amazon DocumentDB storage
Amazon DocumentDB data is stored in a cluster volume, which is a single, virtual volume that uses solid state drives (SSDs). A cluster volume consists of six copies of your data, which are replicated automatically across multiple Availability Zones in a single Amazon Web Services Region. This replication helps ensure that your data is highly durable, with less possibility of data loss. It also helps ensure that your cluster is more available during a failover because copies of your data already exist in other Availability Zones. These copies can continue to serve data requests to the instances in your Amazon DocumentDB cluster.
How data storage is billed
Amazon DocumentDB automatically increases the size of a cluster volume as the amount of data increases. An Amazon DocumentDB cluster volume can grow to a maximum size of 128 TiB; however, you are only charged for the space that you use in an Amazon DocumentDB cluster volume. Starting with Amazon DocumentDB 4.0, when data is removed, such as by dropping a collection or index, the overall allocated space decreases by a comparable amount. Thus, you can reduce storage charges by deleting collections, indexes, and databases that you no longer need. In Amazon DocumentDB version 3.6, the cluster volume can reuse space that's freed up when you remove data, but the volume itself never decreases in size. As a result in version 3.6, you may not witness any change in storage when you drop a collection or index, even though the freed up space is reused.
Note
With Amazon DocumentDB 3.6, storage costs are based on the storage "high water mark" (the maximum amount that was
allocated for the Amazon DocumentDB cluster at any point in time). You can manage costs by avoiding ETL practices that
create large volumes of temporary information, or that load large volumes of new data prior to removing unneeded older data.
If removing data from an Amazon DocumentDB cluster results in a substantial amount of allocated but unused space, resetting
the high water mark requires doing a logical data dump and restore to a new cluster, using a tool such as mongodump or
mongorestore. Creating and restoring a snapshot does not reduce the allocated storage because the physical layout
of the underlying storage remains the same in the restored snapshot.
Note
Using utilities like mongodump and mongorestore incur I/O charges based on the sizes of the data
that is being read and written to the storage volume.
For information about Amazon DocumentDB data storage and I/O pricing, see Amazon DocumentDB (with MongoDB compatibility) pricing
Amazon DocumentDB replication
In an Amazon DocumentDB cluster, each replica instance exposes an independent endpoint. These replica endpoints provide read-only access to the data in the cluster volume. They enable you to scale the read workload for your data over multiple replicated instances. They also help improve the performance of data reads and increase the availability of the data in your Amazon DocumentDB cluster. Amazon DocumentDB replicas are also failover targets and are quickly promoted if the primary instance for your Amazon DocumentDB cluster fails.
Amazon DocumentDB reliability
Amazon DocumentDB is designed to be reliable, durable, and fault tolerant. (To improve availability, you should configure your Amazon DocumentDB cluster so that it has multiple replica instances in different Availability Zones.) Amazon DocumentDB includes several automatic features that make it a reliable database solution.
Storage auto-repair
Amazon DocumentDB maintains multiple copies of your data in three Availability Zones, greatly reducing the chance of losing data due to a storage failure. Amazon DocumentDB automatically detects failures in the cluster volume. When a segment of a cluster volume fails, Amazon DocumentDB immediately repairs the segment. It uses the data from the other volumes that make up the cluster volume to help ensure that the data in the repaired segment is current. As a result, Amazon DocumentDB avoids data loss and reduces the need to perform a point-in-time restore to recover from an instance failure.
Survivable cache warming
Amazon DocumentDB manages its page cache in a separate process from the database so that the page cache can survive independently of the database. In the unlikely event of a database failure, the page cache remains in memory. This ensures that the buffer pool is warmed with the most current state when the database restarts.
Crash recovery
Amazon DocumentDB is designed to recover from a crash almost instantaneously, and to continue serving your application data. Amazon DocumentDB performs crash recovery asynchronously on parallel threads so that your database is open and available almost immediately after a crash.
Resource governance
Amazon DocumentDB safeguards resources that are needed to run critical processes in the service, such as health checks. To do this, and when an instance is experiencing high memory pressure, Amazon DocumentDB will throttle requests. As a result, some operations may be queued to wait for the memory pressure to subside. If memory pressure continues, queued operations may timeout. You can monitor whether or not the service throttling operations due to low memory with the following CloudWatch metrics: LowMemThrottleQueueDepth, LowMemThrottleMaxQueueDepth, LowMemNumOperationsThrottled, LowMemNumOperationsTimedOut. For more information, see Monitoring Amazon DocumentDB with CloudWatch. If you see sustained memory pressure on your instance as a result of the LowMem CloudWatch metrics, we advise that you scale-up your instance to provide additional memory for your workload.
Read preference options
Amazon DocumentDB uses a cloud-native shared storage service that replicates data six times across three Availability Zones to provide high levels of durability. Amazon DocumentDB does not rely on replicating data to multiple instances to achieve durability. Your cluster’s data is durable whether it contains a single instance or 15 instances.
Write durability
Amazon DocumentDB uses a unique, distributed, fault-tolerant, self-healing storage system. This system replicates six copies (V=6) of your data across three Amazon Availability Zones to provide high availability and durability. When writing data, Amazon DocumentDB ensures that all writes are durably recorded on a majority of nodes before acknowledging the write to the client. If you are running a three-node MongoDB replica set, using a write concern of {w:3, j:true} would yield the best possible configuration when comparing with Amazon DocumentDB.
Writes to an Amazon DocumentDB cluster must be processed by the cluster’s writer instance. Attempting to write to a reader results in an error. An acknowledged write from an Amazon DocumentDB primary instance is durable, and can't be rolled back. Amazon DocumentDB is highly durable by default and doesn't support a non-durable write option. You can't modify the durability level (that is, write concern). Amazon DocumentDB ignores w=anything and is effectively w: 3 and j: true. You cannot reduce it.
Because storage and compute are separated in the Amazon DocumentDB architecture, a cluster with a single instance is highly durable. Durability is handled at the storage layer. As a result, an Amazon DocumentDB cluster with a single instance and one with three instances achieve the same level of durability. You can configure your cluster to your specific use case while still providing high durability for your data.
Writes to an Amazon DocumentDB cluster are atomic within a single document.
Amazon DocumentDB does not support the wtimeout option and will
not return an error if a value is specified. Writes to the primary
Amazon DocumentDB instance are guaranteed not to block indefinitely.
Read isolation
Reads from an Amazon DocumentDB instance only return data that is durable before the query begins. Reads never return data modified after the query begins execution nor are dirty reads possible under any circumstances.
Read consistency
Data read from an Amazon DocumentDB cluster is durable and will not be rolled back. You can modify the read consistency for Amazon DocumentDB reads by specifying the read preference for the request or connection. Amazon DocumentDB does not support a non-durable read option.
Reads from an Amazon DocumentDB cluster’s primary instance are strongly consistent under normal operating conditions and have read-after-write consistency. If a failover event occurs between the write and subsequent read, the system can briefly return a read that is not strongly consistent. All reads from a read replica are eventually consistent and return the data in the same order, and often with less than 100 ms replica lag.
Amazon DocumentDB read preferences
Amazon DocumentDB supports setting a read preference option only when reading data from the cluster endpoint in replica set mode. Setting a read preference option affects how your MongoDB client or driver routes read requests to instances in your Amazon DocumentDB cluster. You can set read preference options for a specific query, or as a general option in your MongoDB driver. (Consult your client or driver’s documentation for instructions on how to set a read preference option.)
If your client or driver is not connecting to an Amazon DocumentDB cluster endpoint in replica set mode, the result of specifying a read preference is undefined.
Amazon DocumentDB does not support setting tag sets as a read preference.
Supported Read Preference Options
-
primary—Specifying aprimaryread preference helps ensure that all reads are routed to the cluster’s primary instance. If the primary instance is unavailable, the read operation fails. Aprimaryread preference yields read-after-write consistency and is appropriate for use cases that prioritize read-after-write consistency over high availability and read scaling.The following example specifies a
primaryread preference:db.example.find().readPref('primary') -
primaryPreferred—Specifying aprimaryPreferredread preference routes reads to the primary instance under normal operation. If there is a primary failover, the client routes requests to a replica. AprimaryPreferredread preference yields read-after-write consistency during normal operation, and eventually consistent reads during a failover event. AprimaryPreferredread preference is appropriate for use cases that prioritize read-after-write consistency over read scaling, but still require high availability.The following example specifies a
primaryPreferredread preference:db.example.find().readPref('primaryPreferred') -
secondary—Specifying asecondaryread preference ensures that reads are only routed to a replica, never the primary instance. If there are no replica instances in a cluster, the read request fails. Asecondaryread preference yields eventually consistent reads and is appropriate for use cases that prioritize primary instance write throughput over high availability and read-after-write consistency.The following example specifies a
secondaryread preference:db.example.find().readPref('secondary') -
secondaryPreferred—Specifying asecondaryPreferredread preference ensures that reads are routed to a read replica when one or more replicas are active. If there are no active replica instances in a cluster, the read request is routed to the primary instance. AsecondaryPreferredread preference yields eventually consistent reads when the read is serviced by a read replica. It yields read-after-write consistency when the read is serviced by the primary instance (barring failover events). AsecondaryPreferredread preference is appropriate for use cases that prioritize read scaling and high availability over read-after-write consistency.The following example specifies a
secondaryPreferredread preference:db.example.find().readPref('secondaryPreferred') -
nearest—Specifying anearestread preference routes reads based solely on the measured latency between the client and all instances in the Amazon DocumentDB cluster. Anearestread preference yields eventually consistent reads when the read is serviced by a read replica. It yields read-after-write consistency when the read is serviced by the primary instance (barring failover events). Anearestread preference is appropriate for use cases that prioritize achieving the lowest possible read latency and high availability over read-after-write consistency and read scaling.The following example specifies a
nearestread preference:db.example.find().readPref('nearest')
High availability
Amazon DocumentDB supports highly available cluster configurations by using replicas as failover targets for the primary instance. If the primary instance fails, an Amazon DocumentDB replica is promoted as the new primary, with a brief interruption during which read and write requests made to the primary instance fail with an exception.
If your Amazon DocumentDB cluster doesn't include any replicas, the primary instance is re-created during a failure. However, promoting an Amazon DocumentDB replica is much faster than re-creating the primary instance. So we recommend that you create one or more Amazon DocumentDB replicas as failover targets.
Replicas that are intended for use as failover targets should be of the same instance class as the primary instance. They should be provisioned in different Availability Zones from the primary. You can control which replicas are preferred as failover targets. For best practices on configuring Amazon DocumentDB for high availability, see Understanding Amazon DocumentDB cluster fault tolerance.
Scaling reads
Amazon DocumentDB replicas are ideal for read scaling. They are fully dedicated to read operations on your cluster volume, that is, replicas do not process writes. Data replication happens within the cluster volume and not between instances. So each replica’s resources are dedicated to processing your queries, not replicating and writing data.
If your application needs more read capacity, you can add a replica to your cluster quickly (usually in less than ten minutes). If your read capacity requirements diminish, you can remove unneeded replicas. With Amazon DocumentDB replicas, you pay only for the read capacity that you need.
Amazon DocumentDB supports client-side read scaling through the use of Read Preference options. For more information, see Amazon DocumentDB read preferences.
TTL deletes
Deletes from a TTL index area achieved via a background process are best effort and are not guaranteed within a specific timeframe. Factors like instance size, instance resource utilization, document size, and overall throughput can affect the timing of a TTL delete.
When the TTL monitor deletes your documents, each deletion incurs IO costs, which will increase your bill. If throughput and TTL delete rates increase, you should expect an increase in your bill due to increased IO usage.
When you create a TTL index on an existing collection, you must delete all expired documents before creating the index. The current TTL implementation is optimized for deleting a small fraction of documents in the collection, which is typical if TTL was enabled on the collection from the start, and may result in higher IOPS than necessary if a large number of documents need to be deleted at one go.
If you do not want to create a TTL index to delete documents, you can instead segment documents into collections based on time, and simply drop those collections when the documents are no longer needed. For example: you can create one collection per week and drop it without incurring IO costs. This can be significantly more cost effective than using a TTL index.
Billable resources
Identifying billable Amazon DocumentDB resources
As a fully managed database service, Amazon DocumentDB charges for instances,
storage, I/Os, backups, and data transfer. For more information, see Amazon DocumentDB (with MongoDB compatibility)
pricing
To discover billable resources in your account and potentially delete the resources, you can use the Amazon Web Services Management Console or Amazon CLI.
Using the Amazon Web Services Management Console
Using the Amazon Web Services Management Console, you can discover the Amazon DocumentDB clusters, instances, and snapshots that you have provisioned for a given Amazon Web Services Region.
To discover clusters, instances, and snapshots
Sign in to the Amazon Web Services Management Console, and open the Amazon DocumentDB console at https://console.amazonaws.cn/docdb
. -
To discover billable resources in a Region other than your default Region, in the upper-right corner of the screen, choose the Amazon Web Services Region that you want to search.
-
In the navigation pane, choose the type of billable resource that you're interested in: Clusters, Instances, or Snapshots.
-
All your provisioned clusters, instances, or snapshots for the Region are listed in the right pane. You will be charged for clusters, instances, and snapshots.
Using the Amazon CLI
Using the Amazon CLI, you can discover the Amazon DocumentDB clusters, instances, and snapshots that you have provisioned for a given Amazon Web Services Region.
To discover clusters and instances
The following code lists all your clusters and instances
for the specified Region. If you want to search for clusters
and instances in your default Region, you can omit the
--region parameter.
Example
For Linux, macOS, or Unix:
aws docdb describe-db-clusters \ --region us-east-1 \ --query 'DBClusters[?Engine==`docdb`]' | \ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
For Windows:
aws docdb describe-db-clusters ^ --region us-east-1 ^ --query 'DBClusters[?Engine==`docdb`]' | ^ grep -e "DBClusterIdentifier" -e "DBInstanceIdentifier"
Output from this operation looks something like the following.
"DBClusterIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-38",
"DBInstanceIdentifier": "docdb-2019-01-09-23-55-382",
"DBClusterIdentifier": "sample-cluster",
"DBClusterIdentifier": "sample-cluster2",To discover snapshots
The following code lists all your snapshots for the
specified Region. If you want to search for snapshots in
your default Region, you can omit the
--region parameter.
For Linux, macOS, or Unix:
aws docdb describe-db-cluster-snapshots \ --region us-east-1 \ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
For Windows:
aws docdb describe-db-cluster-snapshots ^ --region us-east-1 ^ --query 'DBClusterSnapshots[?Engine==`docdb`].[DBClusterSnapshotIdentifier,SnapshotType]'
Output from this operation looks something like the following.
[
[
"rds:docdb-2019-01-09-23-55-38-2019-02-13-00-06",
"automated"
],
[
"test-snap",
"manual"
]
]You only need to delete manual snapshots.
Automated snapshots are deleted when you delete
the cluster.
Deleting unwanted billable resources
To delete a cluster, you must first delete all the instances in the cluster.
-
To delete instances, see Deleting an Amazon DocumentDB instance.
Important
Even if you delete the instances in a cluster, you are still billed for the storage and backup usage associated with that cluster. To stop all charges, you must also delete your cluster and manual snapshots.
-
To delete clusters, see Deleting an Amazon DocumentDB cluster.
-
To delete manual snapshots, see Deleting a cluster snapshot.