本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
配置并启动超参数调优作业
重要
允许 Amazon SageMaker Studio 或 Amazon SageMaker Studio Classic 创建亚马逊 SageMaker资源的自定义 IAM 策略还必须授予向这些资源添加标签的权限。之所以需要为资源添加标签的权限,是因为 Studio 和 Studio Classic 会自动为创建的任何资源添加标签。如果 IAM 策略允许 Studio 和 Studio Classic 创建资源但不允许标记,则在尝试创建资源时可能会出现 AccessDenied “” 错误。有关更多信息,请参阅 提供标记 A SageMaker I 资源的权限。
Amazon 亚马逊 A SageMaker I 的托管策略授予创建 SageMaker 资源的权限已经包括在创建这些资源时添加标签的权限。
超参数是在模型训练过程中影响学习过程的高级参数。要获得最佳模型预测,您可以优化超参数配置或设置超参数值。找到最佳配置的过程称为超参数调优。要配置并启动超参数调优作业,请完成本指南中的步骤。
设置超参数调优作业
要指定超参数调优作业的设置,可以在创建调优作业时定义 JSON 对象。将此 JSON 对象作为 HyperParameterTuningJobConfig 参数的值传递给 CreateHyperParameterTuningJob API。
在此 JSON 对象中,指定以下字段:
在此 JSON 对象中,指定:
-
HyperParameterTuningJobObjective– 用于评估超参数调优作业启动的训练作业性能的目标指标。 -
ParameterRanges– 可调超参数在优化期间可以使用的值范围。有关更多信息,请参阅 定义超参数范围。 -
RandomSeed– 用于初始化伪随机数生成器的值。设置随机种子将允许超参数调优搜索策略为相同的调优作业生成更一致的配置(可选)。 -
ResourceLimits– 超参数调优作业可以使用的最大训练数和最大并行训练作业数。
以下代码示例演示了如何使用内置 XGBoost 算法配置超参数调优作业。此代码示例演示了如何定义 eta、alpha、min_child_weight 和 max_depth 超参数的范围。有关这些超参数和其他超参数的更多信息,请参阅 XGBoost 参数
在此代码示例中,超参数调整作业的目标指标会找到最大化的超参数配置。validation:auc SageMaker AI 内置算法会自动将目标指标写入 CloudWatch 日志。以下代码示例演示了如何设置 RandomSeed。
tuning_job_config = { "ParameterRanges": { "CategoricalParameterRanges": [], "ContinuousParameterRanges": [ { "MaxValue": "1", "MinValue": "0", "Name": "eta" }, { "MaxValue": "2", "MinValue": "0", "Name": "alpha" }, { "MaxValue": "10", "MinValue": "1", "Name": "min_child_weight" } ], "IntegerParameterRanges": [ { "MaxValue": "10", "MinValue": "1", "Name": "max_depth" } ] }, "ResourceLimits": { "MaxNumberOfTrainingJobs": 20, "MaxParallelTrainingJobs": 3 }, "Strategy": "Bayesian", "HyperParameterTuningJobObjective": { "MetricName": "validation:auc", "Type": "Maximize" }, "RandomSeed" : 123 }
配置训练作业
超参数调优作业将启动训练作业,以找到超参数的最佳配置。这些训练作业应使用 SageMaker A CreateHyperParameterTuningJobI API 进行配置。
要配置训练作业,可定义一个 JSON 对象并将其作为 TrainingJobDefinition 参数的值传递给 CreateHyperParameterTuningJob。
在此 JSON 对象中,可以指定以下字段:
-
AlgorithmSpecification– 包含训练算法和相关元数据的 Docker 映像的注册表路径。要指定算法,您可以在 Docker容器中使用自己的自定义算法或 A SageMaker I 内置算法(必需)。 -
InputDataConfig– 输入配置,包括训练和测试数据的ChannelName、ContentType和数据来源(必填)。 -
InputDataConfig– 输入配置,包括训练和测试数据的ChannelName、ContentType和数据来源(必填)。 -
算法输出的存储位置。指定存储训练作业输出的 S3 存储桶。
-
RoleArn— A SageMaker I 用来执行任务的 (IAM) 角色的亚马逊资源名称 Amazon Identity and Access Management (ARN)。任务包括读取输入数据、下载 Docker 映像、将模型工件写入 S3 存储桶、将日志写入 Amazon CloudWatch Logs 以及将指标写入亚马逊 CloudWatch (必填)。 -
StoppingCondition– 训练作业在停止之前可以运行的最大运行时(以秒为单位)。该值应大于训练模型所需的时间(必填)。 -
MetricDefinitions– 用以定义训练作业发出的任何指标的名称和正则表达式。仅当使用自定义训练算法时才需要定义指标。以下代码中的示例使用内置算法,已经定义了指标。有关定义指标(可选)的信息,请参阅定义指标。 -
TrainingImage– 指定训练算法的 Docker容器映像(可选)。 -
StaticHyperParameters– 在调优作业中无需调整的超参数的名称和值(可选)。
以下代码示例为 使用亚马逊 AI 的 xgBoost 算法 SageMaker内置算法的 eval_metric、num_round、objective、rate_drop 和 tweedie_variance_power 参数设置了静态值。
命名并启动超参数调优作业
配置超参数调优作业之后,可以通过调用 CreateHyperParameterTuningJob API 启动该作业。以下代码示例使用了 tuning_job_config 和 training_job_definition。这两个对象是在之前的两个代码示例中定义的,用于创建超参数调优作业。
tuning_job_name = "MyTuningJob" smclient.create_hyper_parameter_tuning_job(HyperParameterTuningJobName = tuning_job_name, HyperParameterTuningJobConfig = tuning_job_config, TrainingJobDefinition = training_job_definition)
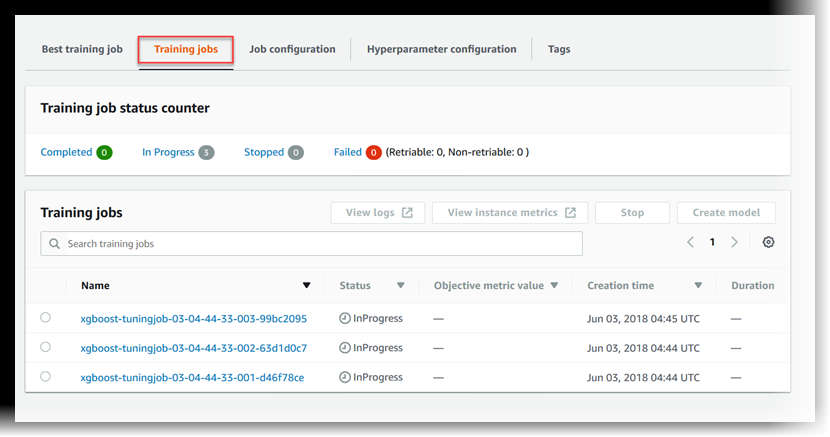
查看训练作业的状态
查看超参数调优作业启动的训练作业的状态
-
在超参数调优作业列表中,选择您启动的作业。
-
选择训练作业。
-
查看各个训练作业的状态。要查看有关作业的详细信息,请在训练作业列表中选择该作业。要查看超参数调优作业启动的所有训练作业的状态摘要,请查看训练作业状态计数器。
训练作业可能处于以下状态:
-
Completed– 训练作业已成功完成。 -
InProgress– 训练作业正在进行中。 -
Stopped– 训练作业在完成之前被手动停止。 -
Failed (Retryable)– 训练作业失败,但可以重试。只有在训练作业由于出现内部服务错误而失败时,才能重试该训练作业。 -
Failed (Non-retryable)– 训练作业失败,并且无法重试。在出现客户端错误时,无法重试失败的训练作业。
注意
可以停止超参数调优作业并删除底层资源,但无法删除作业本身。
-
查看最佳训练作业
超参数调优作业使用各个训练作业返回的目标指标来评估训练作业。在超参数调优作业进行中时,最佳训练作业是迄今为止返回了最佳目标指标的作业。超参数调优作业完成后,最佳训练作业是返回了最佳目标指标的作业。
要查看最佳训练作业,可选择最佳训练作业。
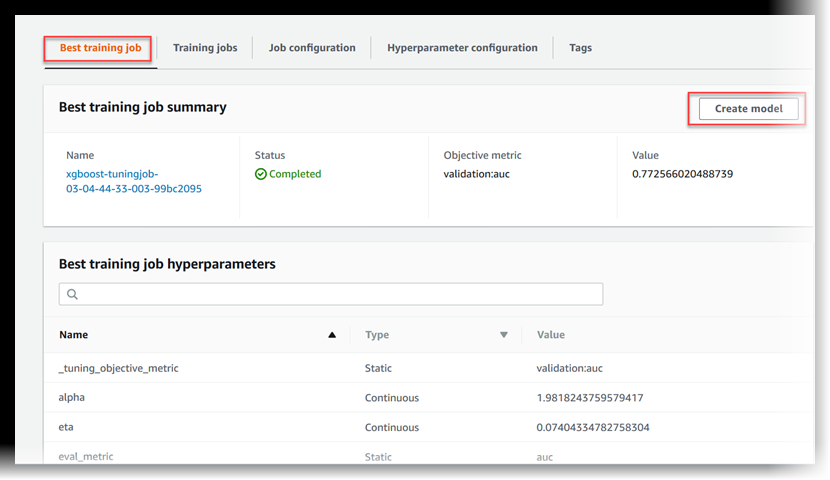
要将最佳训练作业部署为可以托管在 SageMaker AI 端点的模型,请选择创建模型。