本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
训练模型
在此步骤中,您需要选择一种训练算法,并为模型运行训练作业。Amaz SageMaker on Python SDK
选择训练算法
要为数据集选择正确的算法,通常需要评估不同的模型,以找到最适合数据的模型。为简单起见,本教程中使用了 SageMaker AI 使用亚马逊 AI 的 xgBoost 算法 SageMaker 内置算法,无需对模型进行预评估。
提示
如果您想让 SageMaker AI 为您的表格数据集找到合适的模型,请使用自动执行机器学习解决方案的 Amazon A SageMaker utopilot。有关更多信息,请参阅 SageMaker 自动驾驶。
创建并运行训练作业
弄清楚要使用哪个模型后,开始构造用于训练的 A SageMaker I 估计器。本教程使用了 XGBoost 的内置算法来构建 SageMaker AI 通用估计器。
运行模型训练作业
-
导入 Amaz SageMaker on Python 软件开发工具包
,然后从当前 SageMaker 的人工智能会话中检索基本信息。 import sagemaker region = sagemaker.Session().boto_region_name print("Amazon Region: {}".format(region)) role = sagemaker.get_execution_role() print("RoleArn: {}".format(role))此过程返回以下信息:
-
region— 运行 SageMaker AI 笔记本实例的当前 Amazon 区域。 -
role– 笔记本实例使用的 IAM 角色。
注意
通过运行来检查 SageMaker Python 开发工具包的版本
sagemaker.__version__。本教程基于sagemaker>=2.20。如果 SDK 已过时,请运行以下命令安装最新版本:! pip install -qU sagemaker如果您在现有的 SageMaker Studio 或笔记本实例中运行此安装,则需要手动刷新内核才能完成版本更新的应用。
-
-
使用
sagemaker.estimator.Estimator类创建 XGBoost 估算器。在以下示例代码中,XGBoost 估算器被命名为xgb_model。from sagemaker.debugger import Rule, ProfilerRule, rule_configs from sagemaker.session import TrainingInput s3_output_location='s3://{}/{}/{}'.format(bucket, prefix, 'xgboost_model') container=sagemaker.image_uris.retrieve("xgboost", region, "1.2-1") print(container) xgb_model=sagemaker.estimator.Estimator( image_uri=container, role=role, instance_count=1, instance_type='ml.m4.xlarge', volume_size=5, output_path=s3_output_location, sagemaker_session=sagemaker.Session(), rules=[ Rule.sagemaker(rule_configs.create_xgboost_report()), ProfilerRule.sagemaker(rule_configs.ProfilerReport()) ] )要构造 A SageMaker I 估计器,请指定以下参数:
-
image_uri– 指定训练容器映像 URI。在此示例中, SageMaker AI xgBoost 训练容器 URI 是使用指定的。sagemaker.image_uris.retrieve -
role— A SageMaker I 用来代表您执行任务的 Amazon Identity and Access Management (IAM) 角色(例如,读取训练结果、从 Amazon S3 调用模型工件以及将训练结果写入 Amazon S3)。 -
instance_count和instance_type– 用于模型训练的 Amazon EC2 ML 计算实例的类型和数量。在此训练练习中,您使用的是单个ml.m4.xlarge实例,该实例有 4 个 CPU、16 GB 内存、Amazon Elastic Block Store (Amazon EBS) 存储和高网络性能。有关 EC2 计算实例类型的更多信息,请参阅 Amazon EC2 实例类型。有关账单的更多信息,请参阅 Amazon SageMaker 定价 。 -
volume_size– 要附加到训练实例的 EBS 存储卷的大小 (GB)。如果使用File模式(默认情况下File模式处于打开状态),该值必须足够大,以存储训练数据。如果不指定该参数,默认值为 30。 -
output_path— 指向 SageMaker AI 存储模型工件和训练结果的 S3 存储桶的路径。 -
sagemaker_session— 管理与训练作业使用 SageMaker 的 API 操作和其他 Amazon 服务的交互的会话对象。 -
rules— 指定 SageMaker 调试器内置规则列表。在此示例中,create_xgboost_report()规则创建一份 XGBoost 报告,该报告提供对训练进度和结果的见解,ProfilerReport()规则创建一份有关 EC2 计算资源利用率的报告。有关更多信息,请参阅 SageMaker XGBoost 的调试器交互式报告。
提示
如果要对大型深度学习模型(例如卷积神经网络 (CNN) 和自然语言处理 (NLP) 模型)进行分布式训练,请使用 SageMaker AI Distributed 进行数据并行性或模型并行性。有关更多信息,请参阅 在 Amazon A SageMaker I 中进行分布式训练。
-
-
通过调用估算器的
set_hyperparameters方法为 XGBoost 算法设置超参数。有关 XGBoost 超参数的完整列表,请参阅 XGBoost 超参数。xgb_model.set_hyperparameters( max_depth = 5, eta = 0.2, gamma = 4, min_child_weight = 6, subsample = 0.7, objective = "binary:logistic", num_round = 1000 )提示
您也可以使用 SageMaker AI 超参数优化功能调整超参数。有关更多信息,请参阅 使用 SageMaker AI 自动调整模型。
-
使用
TrainingInput类来配置用于训练的数据输入流。以下示例代码演示如何配置TrainingInput对象以使用您在将数据集拆分为训练、验证和测试数据集部分上传到 Amazon S3 的训练数据集和验证数据集。from sagemaker.session import TrainingInput train_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/train.csv"), content_type="csv" ) validation_input = TrainingInput( "s3://{}/{}/{}".format(bucket, prefix, "data/validation.csv"), content_type="csv" ) -
要开始模型训练,请使用训练数据集和验证数据集调用估算器的
fit方法。通过设置wait=True,fit方法会显示进度日志,并等待训练完成。xgb_model.fit({"train": train_input, "validation": validation_input}, wait=True)有关模型训练的更多信息,请参阅 使用 Amazon 训练模型 SageMaker。本教程的训练作业最多可能需要 10 分钟时间。
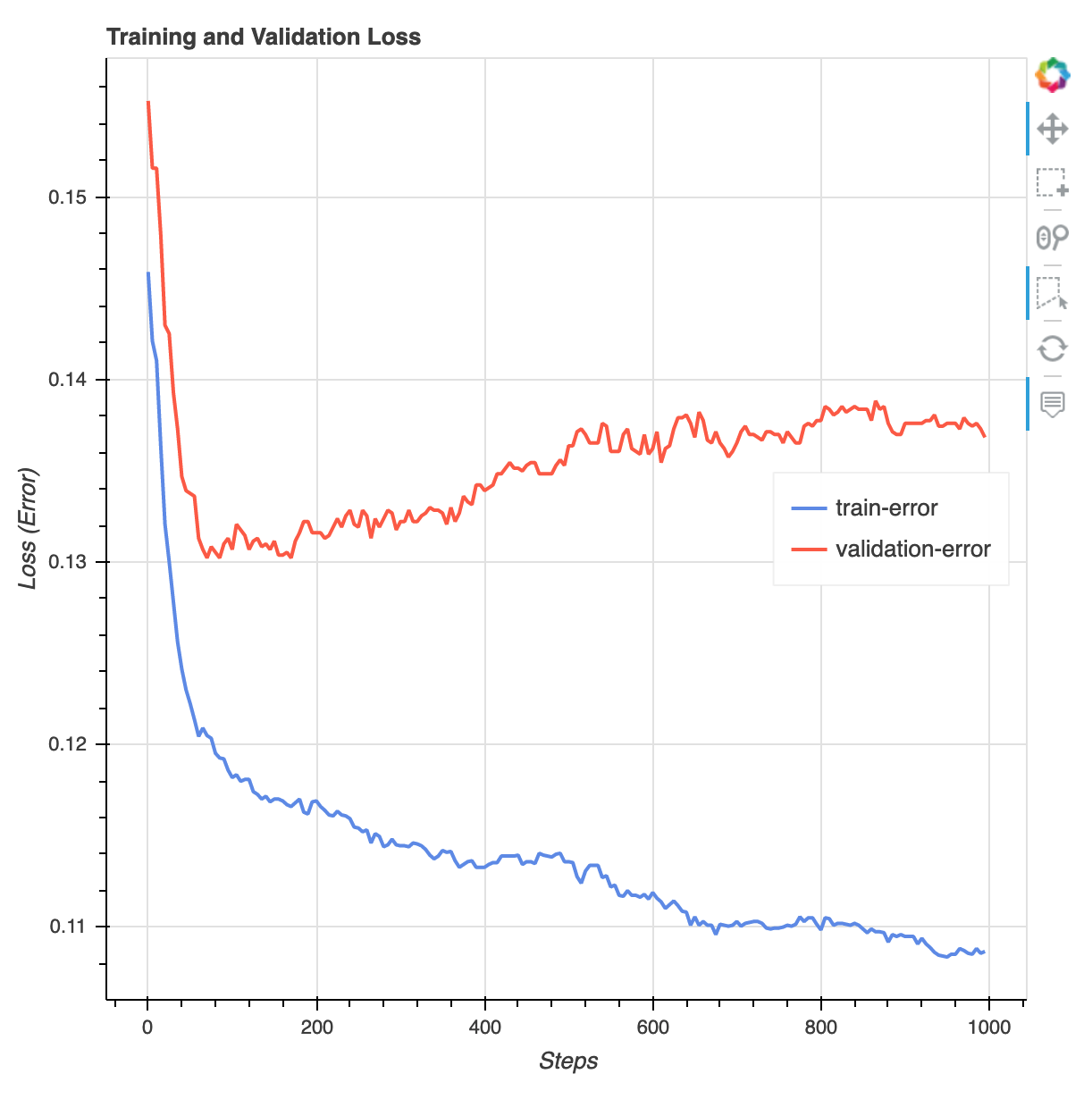
训练作业完成后,您可以下载 XGBoost 训练报告和 Debugger 生成的 SageMaker 分析报告。通过 XGBoost 训练报告,您可以深入了解训练的进度和结果,例如关于迭代的损失函数、特征重要性、混淆矩阵、准确率曲线以及其他训练统计结果。例如,您可以从 XGBoost 训练报告中找到以下损失曲线,该曲线清楚地表明存在过度拟合问题。
运行以下代码以指定生成 Debugger 训练报告的 S3 存储桶 URI,并检查这些报告是否存在。
rule_output_path = xgb_model.output_path + "/" + xgb_model.latest_training_job.job_name + "/rule-output" ! aws s3 ls {rule_output_path} --recursive将 Debugger XGBoost 训练和分析报告下载到当前工作区:
! aws s3 cp {rule_output_path} ./ --recursive运行以下 IPython 脚本以获取 XGBoost 训练报告的文件链接:
from IPython.display import FileLink, FileLinks display("Click link below to view the XGBoost Training report", FileLink("CreateXgboostReport/xgboost_report.html"))以下 IPython 脚本返回 Debugger 分析报告的文件链接,该报告显示 EC2 实例资源利用率、系统瓶颈检测结果和 python 操作分析结果的摘要和详细信息:
profiler_report_name = [rule["RuleConfigurationName"] for rule in xgb_model.latest_training_job.rule_job_summary() if "Profiler" in rule["RuleConfigurationName"]][0] profiler_report_name display("Click link below to view the profiler report", FileLink(profiler_report_name+"/profiler-output/profiler-report.html"))提示
如果 HTML 报告未在 JupyterLab 视图中呈现绘图,则必须在报告顶部选择 T rust HTML。
要识别训练问题,例如过度拟合、渐变消失以及其他阻碍模型收敛的问题,请在创建和训练机器学习模型的原型和训练时使用 D SageMaker ebugger 并自动执行操作。有关更多信息,请参阅 Amazon SageMaker 调试器。要查找模型参数的完整分析,请参阅 Amazon D SageMaker ebugger 的可解释性
示例笔记本。
你现在已经有了经过训练的 XGBoost 模型。 SageMaker AI 将模型工件存储在您的 S3 存储桶中。要查找模型构件的位置,请运行以下代码以打印 xgb_model 估算器的 model_data 属性:
xgb_model.model_data
提示
要测量机器学习生命周期的每个阶段(数据收集、模型训练和调整以及监控为预测而部署的机器学习模型)中可能出现的偏差,请使用 Clarify SageMaker 。有关更多信息,请参阅 模型可解释性。有关端到端示例,请参阅 Clarify 的公平性和可解释性示例 SageMaker 笔记本