本文属于机器翻译版本。若本译文内容与英语原文存在差异,则一律以英文原文为准。
自动数据标注
如果您愿意,Amazon G SageMaker round Truth 可以使用主动学习来自动标记某些内置任务类型的输入数据。主动学习是一种机器学习技术,可识别应由您的工作人员标注的数据。在 Ground Truth 中,此功能称为自动数据标注。自动数据标注与只用人工相比,有助于减少标注数据集所需的成本和时间。使用自动标签时,会产生 SageMaker 培训和推理成本。
我们建议在大型数据集上使用自动数据标注,因为主动学习所使用的神经网络需要为每个新数据集提供大量数据。通常情况下,当您提供的数据越多,高精度预测的可能性就越大。只有当自动标注模型中使用的神经网络能够达到可接受的高精度时,才会对数据进行自动标注。因此,对于较大的数据集,能自动标注数据的可能性更大,因为神经网络可以达到足够高的自动标注准确性。自动数据标注最适合有数千个数据对象的情况。自动数据标注允许的最小对象数量为 1250,但我们强烈建议至少提供 5000 个对象。
自动数据标注仅适用于以下 Ground Truth 内置任务类型:
流式标注作业不支持自动数据标注。
要了解如何使用自己的模型创建自定义主动学习工作流,请参阅使用自己的模型设置主动学习工作流。
输入数据限额适用于自动数据标注作业。请参阅输入数据限额,了解有关数据集大小、输入数据大小和分辨率限制的信息。
注意
在生产环境中使用自动标注模型之前,需要对该模型进行优化和/或测试。您可以针对由标注作业生成的数据集来优化模型(或创建并优化您选择的另一个监管式模型),以优化模型的架构和超参数。如果您决定使用该模型进行推理而不进行优化,我们强烈建议您确保在使用 Ground Truth 标注的数据集的代表性子集(例如,随机选择的子集)上评估其准确率,且准确率与您的期望目标匹配。
工作原理
创建标注作业时,您可以启用自动数据标注。以下是具体工作方式:
-
Ground Truth 启动自动数据标注作业时,会随机选择输入数据对象的样本,并将其发送给工作人员。如果这些数据对象中有 10% 以上失败,则标注作业将失败。如果标注作业失败,除了查看 Ground Truth 返回的任何错误消息之外,还要检查您的输入数据是否在工作人员用户界面中正确显示、说明是否明确,以及您为工作人员提供了足够的时间来完成任务。
-
标注的数据返回后,将用于创建训练集和验证集。Ground Truth 使用这些数据集来训练和验证用于自动标注的模型。
-
Ground Truth 运行批量转换作业,同时使用验证的模型对验证数据进行推理。批量推理为验证数据中的每个对象生成置信度得分和质量指标。
-
自动标注组件将使用这些质量指标和置信度得分来创建置信度得分阈值,以确保标注质量。
-
Ground Truth 对数据集中未标注的数据运行批量转换作业,同时使用相同的已验证模型进行推理。这将为每个对象生成置信度得分。
-
Ground Truth 自动标注组件确定在步骤 5 中为每个对象生成的置信度得分是否满足在步骤 4 中确定的所需阈值。如果置信度得分满足阈值,则自动标注的预期质量超过要求的准确性水平,该对象将被视为自动标注。
-
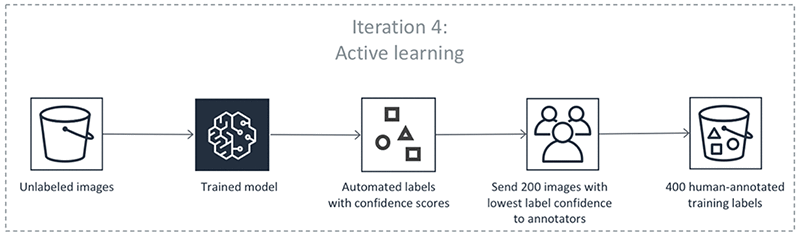
步骤 6 生成具有置信度得分的未标注数据集。Ground Truth 从此数据集中选择置信度得分较低的数据点并将其发送给工作人员。
-
Ground Truth 使用现有的人工标注数据和来自工作人员的额外标注数据来更新模型。
-
该过程将重复执行,直到数据集完全标注或满足另一个停止条件。例如,如果达到人工注释预算,自动标注将停止。
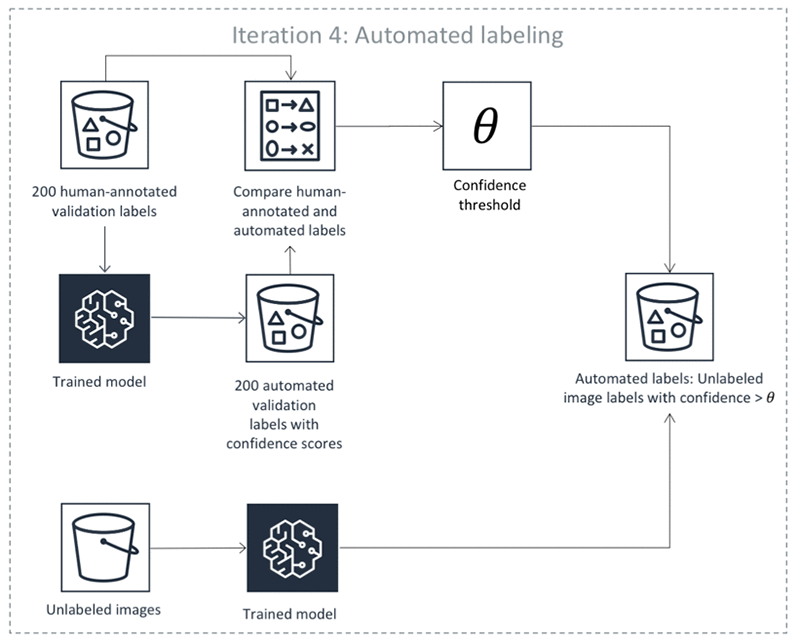
前面的步骤会反复进行。选择下表中的每个选项卡,查看对象检测自动标注作业每次迭代过程的示例。这些图像中给定步骤中使用的数据对象的数量(例如 200)特定于此示例。如果需要标注的对象少于 5000 个,则验证集的大小为整个数据集的 20%。如果输入数据集中有超过 5000 个对象,则验证集的大小为整个数据集的 10%。在使用 API 操作 CreateLabelingJob 时,您可以通过更改 MaxConcurrentTaskCount 的值来控制每次主动学习迭代收集的人工标签数量。使用控制台创建标注作业时,此值设置为 1000。在主动学习选项卡下的主动学习流程中,此值设置为 200。

自动标注的准确性
准确性的定义取决于自动标注使用的内置任务类型。对于所有任务类型,这些准确性要求由 Ground Truth 预先确定,不能手动配置。
-
对于图像分类和文本分类,Ground Truth 使用逻辑来找到至少对应于 95% 标注准确率的标注预测置信度。这意味着,与人工标注者为这些示例提供的标注相比,Ground Truth 期望自动标注的准确率至少达到 95%。
-
对于边界框,自动标注图像的预期平均交并比 (IoU)
为 0.6。为了找到平均 IoU,Ground Truth 计算每个类图像上所有预测边界框和缺失边界框的平均 IoU,然后在各个类之间取这些值的平均值。 -
对于语义分割,自动标注图像的预期平均 IoU 为 0.7。为了找到平均 IoU,Ground Truth 取图像中所有类(不包括背景)的 IoU 值的平均值。
在主动学习的每一次迭代(上表列出的步骤 3-6)中,都会使用人工标注的验证集来找到置信度阈值,从而使自动标注对象的预期准确性满足某些预定义的准确性要求。
创建自动数据标注作业(管理控制台)
要在 A SageMaker I 控制台中创建使用自动标签的标签任务,请按以下步骤操作。
创建自动数据标注作业(控制台)
-
打开 SageMaker 人工智能控制台的 Ground Truth 标签作业部分:https://console.amazonaws.cn/sagemaker/groundtruth
. -
使用创建标注作业(控制台)作为指南,完成作业概览和任务类型部分。请注意,自定义任务类型不支持自动标注。
-
在工作人员下,选择人力类型。
-
在同一部分中,选择启用自动数据标注。
-
以配置边界框工具此为指导,在章节
Task Type标注工具中创建工作人员指令。例如,如果您选择语义分割作为标注作业类型,则此部分称为语义分割标注工具。 -
要预览工作人员说明和控制面板,请选择预览。
-
选择创建。这将创建并启动标注作业和自动标注流程。
您可以在 SageMaker AI 控制台的 “标注任务” 部分中看到您的标签作业。输出数据会出现在创建标注作业时指定的 Amazon S3 存储桶中。有关标注作业输出数据的格式和文件结构的更多信息,请参阅标注作业输出数据。
创建自动数据标注作业 (API)
要使用 SageMaker API 创建自动数据标注任务,请使用CreateLabelingJob操作的LabelingJobAlgorithmsConfig参数。要了解如何使用 CreateLabelingJob 操作启动标注作业,请参阅创建标注作业 (API)。
在参数中指定用于自动数据标签的算法的 Amazon 资源名称 (ARN)。LabelingJobAlgorithmSpecificationArn从自动标注支持的四种 Ground Truth 内置算法中选择一种:
自动数据标注作业完成后,Ground Truth 会返回自动数据标注作业所用模型的 ARN。通过在参数中提供字符串格式的 ARN,可将此模型用作类似自动标记作业类型的起始模型。InitialActiveLearningModelArn要检索模型的 ARN,请使用类似于以下Amazon CLI内容的 Amazon Command Line Interface () 命令。
# Fetch the mARN of the model trained in the final iteration of the previous labeling job.Ground Truth pretrained_model_arn = sagemaker_client.describe_labeling_job(LabelingJobName=job_name)['LabelingJobOutput']['FinalActiveLearningModelArn']
要加密连接到自动标记的 ML 计算实例的存储卷上的数据,请在VolumeKmsKeyId参数中加 Amazon Key Management Service 入 (Amazon KMS) 密钥。有关 Amazon KMS 密钥的信息,请参阅什么是 Amazon 密钥管理服务? 在《Amazon 密钥管理服务开发人员指南》中。
有关使用该CreateLabelingJob操作创建自动数据标注作业的示例,请参阅 AI 笔记本实例的 AI 示例,G roun d Truth 标签作业部分中的 object_d etection_tutor ial 示例。SageMaker SageMaker 要了解如何创建和打开笔记本实例,请参阅创建 Amazon SageMaker 笔记本实例。
自动数据标注所需的 Amazon EC2 实例
下表列出了为训练和批量推理作业运行自动数据标注所需的 Amazon Elastic Compute Cloud (Amazon EC2) 实例。
| 自动数据标注作业类型 | 训练实例类型 | 推理实例类型 |
|---|---|---|
|
图像分类 |
ml.p3.2xlarge* |
ml.c5.xlarge |
|
对象检测(边界框) |
ml.p3.2xlarge* |
ml.c5.4xlarge |
|
文本分类 |
ml.c5.2xlarge |
ml.m4.xlarge |
|
语义分割 |
ml.p3.2xlarge* |
ml.p3.2xlarge* |
* 在亚太地区(孟买)区域 (ap-south-1) 中,改用 ml.p2.8xlarge。
Ground Truth 管理您用于自动数据标注作业的实例。它根据需要创建、配置和终止实例以执行作业。这些实例不会显示在 Amazon EC2 实例控制面板中。
使用自己的模型设置主动学习工作流
您可以使用自己的算法创建一个主动学习工作流,在该工作流中运行训练和推理,对数据进行自动标注。笔记本 bring_your_own_model_for_sagemaker_labeling_workflows_with_active_learning.ipynb 使用 AI 内置算法演示了这一点。 SageMaker BlazingText此笔记本提供了一个 Amazon CloudFormation 堆栈,您可以使用该堆栈来执行此工作流程 Amazon Step Functions。可以在此GitHub 存储库