ElastiCache components and features
Following, you can find an overview of the major components of an Amazon ElastiCache deployment.
Topics
ElastiCache nodes
A node is the smallest building block of an ElastiCache deployment. A node can exist in isolation from or in some relationship to other nodes.
A node is a fixed-size chunk of secure, network-attached RAM. Each node runs an instance of the engine and version that was chosen when you created your cluster. If necessary, you can scale the nodes in a cluster up or down to a different instance type. For more information, see Scaling ElastiCache (Redis OSS) .
Every node within a cluster is the same instance type and runs the same cache engine. Each cache node has its own Domain Name Service (DNS) name and port. Multiple types of cache nodes are supported, each with varying amounts of associated memory. For a list of supported node instance types, see Supported node types.
You can purchase nodes on a pay-as-you-go basis, where you only pay for your use of a node. Or you can purchase reserved nodes at a much-reduced hourly rate. If your usage rate is high, purchasing reserved nodes can save you money. Suppose that your cluster is almost always in use, and you occasionally add nodes to handle use spikes. In this case, you can purchase a number of reserved nodes to run most of the time. You can then purchase pay-as-you-go nodes for the times you occasionally need to add nodes. For more information on reserved nodes, see ElastiCache reserved nodes.
For more information on nodes, see Managing nodes.
ElastiCache (Redis OSS) shards
A Redis OSS shard (called a node group in the API and CLI) is a grouping of one to six related nodes. A Redis OSS cluster with cluster mode enabled always has at least one shard.
Sharding is a method of database partitioning that separates large databases into smaller, faster, and more easily managed parts called data shards. This can increase database efficiency by distributing operations across multiple separate sections. Using shards can offer many benefits including improved performance, scalability, and cost efficiency.
Redis OSS clusters with cluster mode enabled can have up to 500 shards, with your data partitioned across the shards. The node or shard limit can be increased to a maximum of 500 per cluster if the Redis OSS engine version is 5.0.6 or higher. For example, you can choose to configure a 500 node cluster that ranges between 83 shards (one primary and 5 replicas per shard) and 500 shards (single primary and no replicas). Make sure there are enough available IP addresses to accommodate the increase. Common pitfalls include the subnets in the subnet group have too small a CIDR range or the subnets are shared and heavily used by other clusters. For more information, see Creating a subnet group. For versions below 5.0.6, the limit is 250 per cluster.
To request a limit increase, see
Amazon Service Limits
A multiple node shard implements replication by having one read/write primary node and 1–5 replica nodes. For more information, see High availability using replication groups.
For more information on shards, see Working with shards.
ElastiCache (Redis OSS) clusters
A Redis OSS cluster is a logical grouping of one or more ElastiCache (Redis OSS) shards. Data is partitioned across the shards in a Redis OSS cluster that has cluster mode enabled.
Many ElastiCache operations are targeted at clusters:
-
Creating a cluster
-
Modifying a cluster
-
Taking snapshots of a cluster (all versions of Redis)
-
Deleting a cluster
-
Viewing the elements in a cluster
-
Adding or removing cost allocation tags to and from a cluster
For more detailed information, see the following related topics:
Managing clusters and Managing nodes
Information about clusters, nodes, and related operations.
-
Amazon service limits: Amazon ElastiCache
Information about ElastiCache limits, such as the maximum number of nodes or clusters. To exceed certain of these limits, you can make a request using the Amazon ElastiCache cache node request form
. -
Information about improving the fault tolerance of your clusters and replication groups.
Typical cluster configurations
Following are typical cluster configurations.
Redis OSS clusters
Redis OSS clusters with cluster mode disabled always contain just one shard (in the API and CLI, one node group). A Redis OSS shard contains one to six nodes. If there is more than one node in a shard, the shard supports replication. In this case, one node is the read/write primary node and the others are read-only replica nodes.
For improved fault tolerance, we recommend having at least two nodes in a Redis OSS cluster and enabling Multi-AZ. For more information, see Mitigating Failures.
As demand upon your Redis OSS cluster changes, you can scale up or down. To do this, move your cluster to a different node instance type. If your application is read intensive, we recommend adding read-only replicas to the Redis OSS cluster. By doing this, you can spread the reads across a more appropriate number of nodes.
You can also use data-tiering. More frequently accessed data is stored in memory and less frequently accessed data is stored on disk. The advantage of using data tiering is that it decreases memory needs. For more information, see Data tiering.
ElastiCache supports changing a Redis OSS cluster's node type to a larger node type dynamically. For information on scaling up or down, see Scaling single-node clusters for Redis OSS (Cluster Mode Disabled) or Scaling Redis OSS (Cluster Mode Disabled) clusters with replica nodes.
ElastiCache replication
Replication is implemented by grouping from two to six nodes in a shard (in the API and CLI, called a node group). One of these nodes is the read/write primary node. All the other nodes are read-only replica nodes.
Each replica node maintains a copy of the data from the primary node. Replica nodes use asynchronous replication mechanisms to keep synchronized with the primary node. Applications can read from any node in the cluster but can write only to primary nodes. Read replicas enhance scalability by spreading reads across multiple endpoints. Read replicas also improve fault tolerance by maintaining multiple copies of the data. Locating read replicas in multiple Availability Zones further improves fault tolerance. For more information on fault tolerance, see Mitigating Failures.
Redis OSS clusters support one shard (in the API and CLI, called a node group).
Replication from the API and CLI perspective uses different terminology to maintain compatibility with previous versions, but the results are the same. The following table shows the API and CLI terms for implementing replication.
Comparing Replication: Redis OSS (cluster mode disabled) and Redis OSS (cluster mode enabled)--> Redis OSS cluster with cluster mode enabled vs. Redis OSS cluster with cluster mode disabled
In the following table, you can find a comparison of the features of Redis OSS (cluster mode disabled) and Redis OSS (cluster mode enabled) replication groups.
| Redis OSS cluster with cluster mode disabled | Redis OSS cluster with cluster mode enabled | |
|---|---|---|
| Shards (node groups) | 1 | 1–500 |
| Replicas for each shard (node group) | 0–5 | 0–5 |
| Data partitioning | No | Yes |
| Add/Delete replicas | Yes | Yes |
| Add/Delete node groups | No | Yes |
| Supports scale up | Yes | Yes |
| Supports engine upgrades | Yes | Yes |
| Promote replica to primary | Yes | Automatic |
| Multi-AZ | Optional | Required |
| Backup/Restore | Yes | Yes |
| Notes: | ||
| If any primary has no replicas and the primary fails, you lose all that primary's data. | ||
| You can use backup and restore to migrate to Redis OSS (cluster mode enabled). | ||
| You can use backup and restore to resize your Redis OSS (cluster mode enabled) cluster. | ||
All of the shards (in the API and CLI, node groups) and nodes must reside in the same Amazon Region. However, you can provision the individual nodes in multiple Availability Zones within that Amazon Region.
Read replicas guard against potential data loss because your data is replicated over two or more nodes—the primary and one or more read replicas. For greater reliability and faster recovery, we recommend that you create one or more read replicas in different Availability Zones.
You can also leverage Global datastores. By using the Global Datastore for Redis OSS feature, you can work with fully managed, fast, reliable, and secure replication across Amazon Regions. Using this feature, you can create cross-Region read replica clusters for ElastiCache to enable low-latency reads and disaster recovery across Amazon Regions. For more information, see Replication across Amazon Regions using global datastores.
Replication: Limits and exclusions
Multi-AZ is not supported on node types T1.
Amazon Regions and availability zones
Amazon ElastiCache is available in multiple Amazon Regions around the world. Thus, you can launch ElastiCache clusters in the locations that meet your business requirements. For example, you can launch in the Amazon Region closest to your customers or to meet certain legal requirements.
By default, the Amazon SDKs, Amazon CLI, ElastiCache API, and ElastiCache console reference the US West (Oregon) Region. As ElastiCache expands availability to new Amazon Regions, new endpoints for these Amazon Regions are also available. You can use these in your HTTP requests, the Amazon SDKs, Amazon CLI, and ElastiCache console.
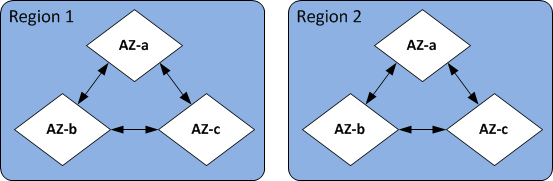
Each Amazon Region is designed to be completely isolated from the other Amazon Regions. Within each are multiple Availability Zones. By launching your nodes in different Availability Zones, you can achieve the greatest possible fault tolerance. For more information about Amazon Regions and Availability Zones, see Choosing regions and availability zones. In the following diagram, you can see a high-level view of how Amazon Regions and Availability Zones work.
For information on Amazon Regions supported by ElastiCache and their endpoints, see Supported regions & endpoints.
ElastiCache endpoints
An endpoint is the unique address your application uses to connect to an ElastiCache node or cluster.
Single node endpoints for Redis OSS with cluster mode disabled
The endpoint for a single node Redis OSS cluster is used to connect to the cluster for both reads and writes.
Multi-node endpoints for Redis OSS with cluster mode disabled
A multiple node Redis OSS cluster with cluster mode disabled has two types of endpoints. The primary endpoint always connects to the primary node in the cluster, even if the specific node in the primary role changes. Use the primary endpoint for all writes to the cluster.
Use the Reader Endpoint to evenly split incoming connections to the endpoint between all read replicas. Use the individual Node Endpoints for read operations (In the API/CLI these are referred to as Read Endpoints).
Redis OSS (Cluster Mode Enabled) endpoints
A Redis OSS cluster with cluster mode enabled has a single configuration endpoint. By connecting to the configuration endpoint, your application is able to discover the primary and read endpoints for each shard in the cluster.
For more information, see Finding connection endpoints.
ElastiCache parameter groups
Cache parameter groups are an easy way to manage runtime settings for supported engine software. Parameters are used to control memory usage, eviction policies, item sizes, and more. An ElastiCache parameter group is a named collection of engine-specific parameters that you can apply to a cluster. By doing this, you make sure that all of the nodes in that cluster are configured in exactly the same way.
For a list of supported parameters, their default values, and which ones can be modified, see DescribeEngineDefaultParameters (CLI: describe-engine-default-parameters).
For more detailed information on ElastiCache parameter groups, see Configuring engine parameters using parameter groups.
ElastiCache security
For enhanced security, ElastiCache (Redis OSS) node access is restricted to applications running on the Amazon EC2 instances that you allow. You can control the Amazon EC2 instances that can access your cluster using security groups.
By default, all new ElastiCache clusters are launched in an Amazon Virtual Private Cloud (Amazon VPC) environment. You can use subnet groups to grant cluster access from Amazon EC2 instances running on specific subnets.
In addition to restricting node access, ElastiCache supports TLS and in-place encryption for nodes running specified versions of ElastiCache. For more information, see the following:
ElastiCache subnet groups
A subnet group is a collection of subnets (typically private) that you can designate for your clusters running in an Amazon VPC environment.
If you create a cluster in an Amazon VPC, then you must specify a cache subnet group. ElastiCache uses that cache subnet group to choose a subnet and IP addresses within that subnet to associate with your cache nodes.
For more information about cache subnet group usage in an Amazon VPC environment, see the following:
ElastiCache (Redis OSS) backups
A backup is a point-in-time copy of a Redis OSS cluster. Backups can be used to restore an existing cluster or to seed a new cluster. Backups consist of all the data in a cluster plus some metadata.
Depending upon the version of Redis OSS running on your cluster, the backup process requires differing amounts of reserved memory to succeed. For more information, see the following:
ElastiCache events
When important events happen on a cache cluster, ElastiCache sends notification to a specific Amazon SNS topic. These events can include such things as failure or success in adding a node, a security group modification, and others. By monitoring for key events, you can know the current state of your clusters and in many cases take corrective action.
For more information on ElastiCache events, see Amazon SNS monitoring of ElastiCache events.